In a Latest Paper From Alibaba, Researchers Propose USI (Unified Scheme for ImageNet) For Solving ImageNet
This article summary is based on the research paper: 'Solving ImageNet: a Unified Scheme for Training any Backbone to Top Results' All credits for this research goes to the authors of this paper. 👏 👏 👏 👏 Please don't forget to join our ML Subreddit Need help in creating ML Research content for your lab/startup? Talk to us at [email protected]
Over the last few years, ImageNet (1K) dataset has been at the forefront of deep learning developments. It is used to pretrain computer vision models, and testing model accuracy on ImageNet is a decent predictor for real performance on various downstream tasks. While the ImageNet dataset remains the primary benchmark for model architecture milestones at the intersection of computer vision and deep learning, ImageNet training can be difficult and time-consuming, as expert knowledge is often required to design and fine-tune a dedicated training scheme for each newly proposed architecture. Today, it is usual practice to train each architecture using a custom-made scheme that has been designed and fine-tuned by a professional. With AlexNet CNN’s exceptional result on the ImageNet Large Scale Visual Recognition Challenge ten years ago, current AI research has been kick-started.
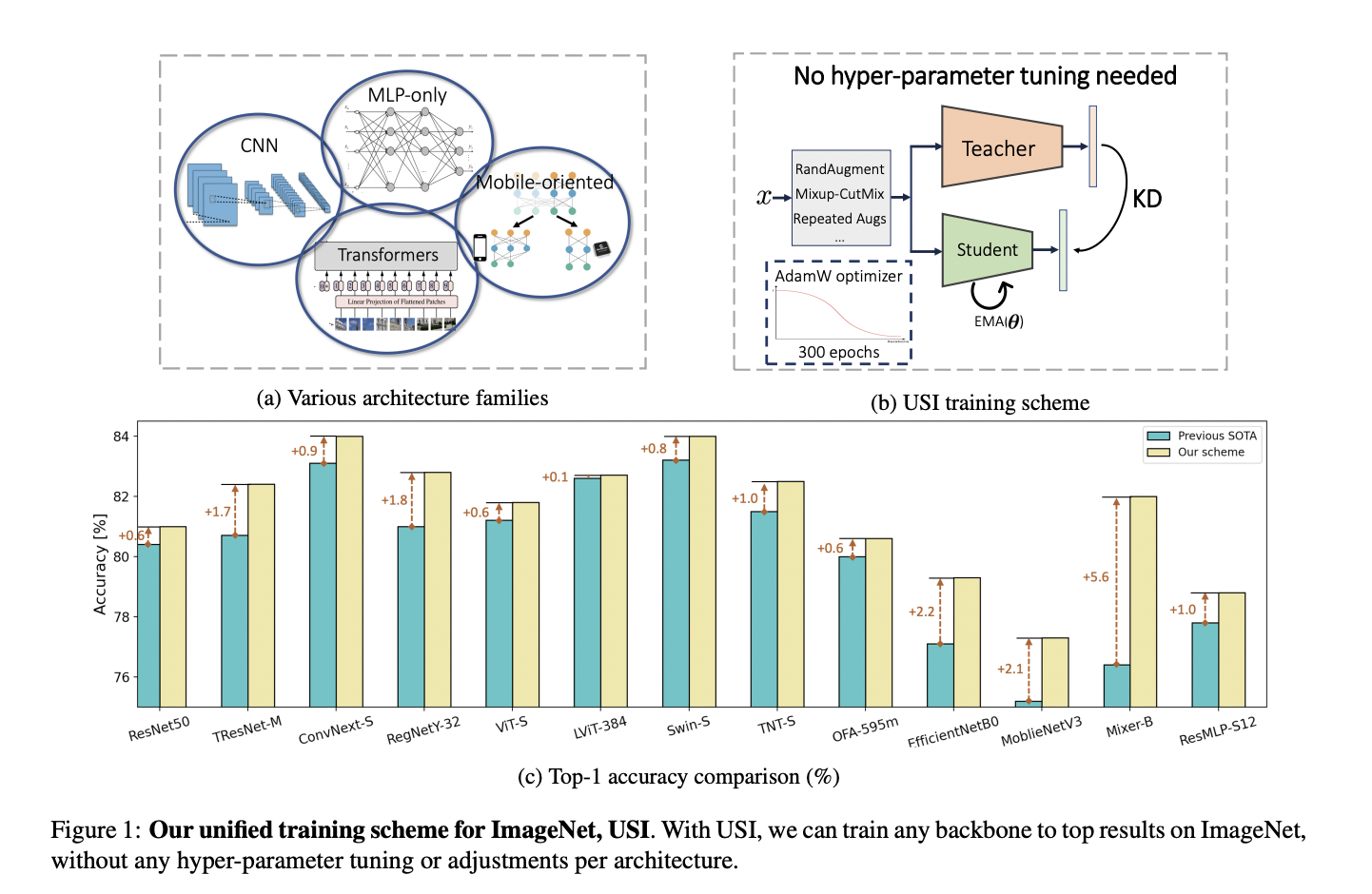
A group of researchers from Alibaba introduced USI (Unified Scheme for ImageNet), a unified scheme that “transforms ImageNet training from an expert-oriented process to an automatic approach,” in the new publication Solving ImageNet: a Unified Scheme for Training Any Backbone to Top Results. The suggested USI can train any backbone on ImageNet, requires no hyperparameter tuning or modifications between models, and consistently produces top model performance in terms of accuracy and efficiency. USI takes any backbone and trains it to achieve maximum performance. It allows for systematic comparisons and the identification of the most efficient backbones along the speed-accuracy Pareto curve.
The team’s significant contributions are summarized as follows:
- For the ImageNet dataset, USI is presented as a unified, efficient training approach that does not require hyperparameter adjustment. Any backbone receives the same treatment. As a result, ImageNet training is transformed from a manual approach to an automated, seamless process.
- USI is tested on ResNet-like, Mobile-oriented, Transformer-based, and MLP-only deep learning models. It is demonstrated that it consistently and reliably achieves state-of-the-art outcomes compared to model-specific approaches.
- USI compares the speed and accuracy of recent deep learning models and identifies efficient backbones along the Pareto curve.

The team demonstrates how knowledge distillation and certain “current gimmicks” enable the proposed USI schema to train any backbone to state-of-the-art outcomes without hyperparameter tuning or model-tailored methodologies.
Knowledge distillation (KD) is a technique that uses a high-performing large-scale teacher model to train a smaller target student model, effectively transferring knowledge from the large complex model to a simple and smaller model that can be deployed on less powerful hardware, such as mobile devices, with only minor performance degradation.

When training deep neural networks on ImageNet, the proposed USI uses KD for classification, which has several advantages: 1) The predictions of the teacher model contain more valuable information than the plain (single-label) ground truth; 2) The approach can handle better photos with many objects; 3) KD predictions handle powerful augmentations better, and 4) Label smoothing is no longer required. As a result, when KD is applied to ImageNet, the optimization process becomes more robust and successful.
The team applies several modern methods to enable USI to train any backbone to high outcomes.
They advocate adopting a range (0.8 to 0.9) of a model’s maximum allowable batch size for optimizing training speeds, for example, because the maximal batch size of different backbones differs. They also recommend selecting a teacher model with a favorable speed-accuracy trade-off because their approach is robust to varied teacher and student-types.
The team tested USI on various deep learning architectures, comparing its ImageNet top-1 accuracy to previous state-of-the-art models.

The findings of the experiment reveal that:
- USI significantly outperforms prior results for CNN architectures.
- In the case of transformer designs, USI outperforms the DeiT method on two notable models, the ViT-S and LeViT-384.
- Compared to previously published results, USI exhibits considerable gains in mobile-oriented and MLP-based systems.
The researchers further demonstrate that the suggested USI schema produces better speed-accuracy trade-offs, is more durable, and allows systematic speed-accuracy comparisons to consistently identify efficient computer vision backbones.
Paper: https://arxiv.org/pdf/2204.03475.pdf
Github: https://github.com/Alibaba-MIIL/Solving_ImageNet
Credit: Source link
Comments are closed.