Google Researchers Propose ALX: An Open-Source Library For Distributed Matrix Factorization Using Alternating Least Squares, Written In JAX
Matric Factorization is an algorithm for matrices in linear algebra. It divides the matrices into a product of matrices, even though the simplicity of Matric Factorization can perform high-level problems of recommender systems. Furthermore, in collaborative filtering, matrix Factorization algorithms work by decomposing the user-item interactions into the product of two rectangular matrics as user and item.
One type of algorithm in Matric Factorization is Alternating Least Square (ALS), which helps learn the parameters of Matric Factorization. Research needs to be done on large-scale problems because of the high efficiency and scaling linearity in both the number of rows and columns and non-zeros of ALS, and it can help through those problems. Even though ALS has high efficiency, a single machine implementation can not be sufficient for a real-world Matric Factorization. Thus, Researchers need an extensive distribution system. Because of the inherently sparse nature of the issue, most distributed implementations of matrix factorization that use ALS rely on off-the-shelf CPU devices.
Recent resounding learning successes have created a new wave of research and progress on hardware accelerators. New computation and model weights strategies have been explored as the data for training sets and model sizes grow. Moreover, to make this adequate, domain-specific hardware acceleration has been considered. Furthermore, Tensor processing units (TPUs) are notable hardware accelerators. A pod of the current generation TPU v3 can provide 100+ petaflops of computing and 32 TiB of high-bandwidth memory, distributed across 2048 individual devices connected in a 2D toroidal mesh network over high-speed interconnects.

TPUs are highly attractive for methods based on Stochastic Gradient Descent (SGD), and it does not clear that the high-performance implementation of ALS can be developed for a large-scale cluster of TPU devices. TPUs can afford domain-specific speedups, which can help deep learning, involving many dense matric factorizations. Traditional data-parallel applications benefit from significant speedups.
So, now the problem is how to make an ALS design that can efficiently use the TPU architecture and scale the matric factorization problems.
As the distributed implementations of matric factorization are off-the-shelf CPU devices, a high-performance implementation can be devised on a large-scale cluster of hardware accelerators. So, the facts that help with these problems are,
- A TPU pod has enough distributed memory to store massive sharded embedding tables.
- TPUs are devised for workloads that can benefit from data parallelism, which can help solve large batches of the system of linear equations.
- TPU chips are interconnected directly with dedicated, high bandwidth, and low latency interconnect, which helps with storing large distributed embedding tables in TPU memory.
- In TPU, Since any node failure can lead to failure in the training process, traditional ML workloads require a highly reliable distributed setup, which requires a cluster of TPUs to fulfill.
So to solve the problems using these facts, researchers at Google have designed a new method that has implemented matric factorization using ALS, which shows high performance in speed and scalability. They discussed different design choices for the architecture. The researchers proposed an open-source library called ALX for distributed matrix factorization using Alternating Least Squares. This new software is written in JAX and will allow more efficiently solve large problems with fewer resources than before!

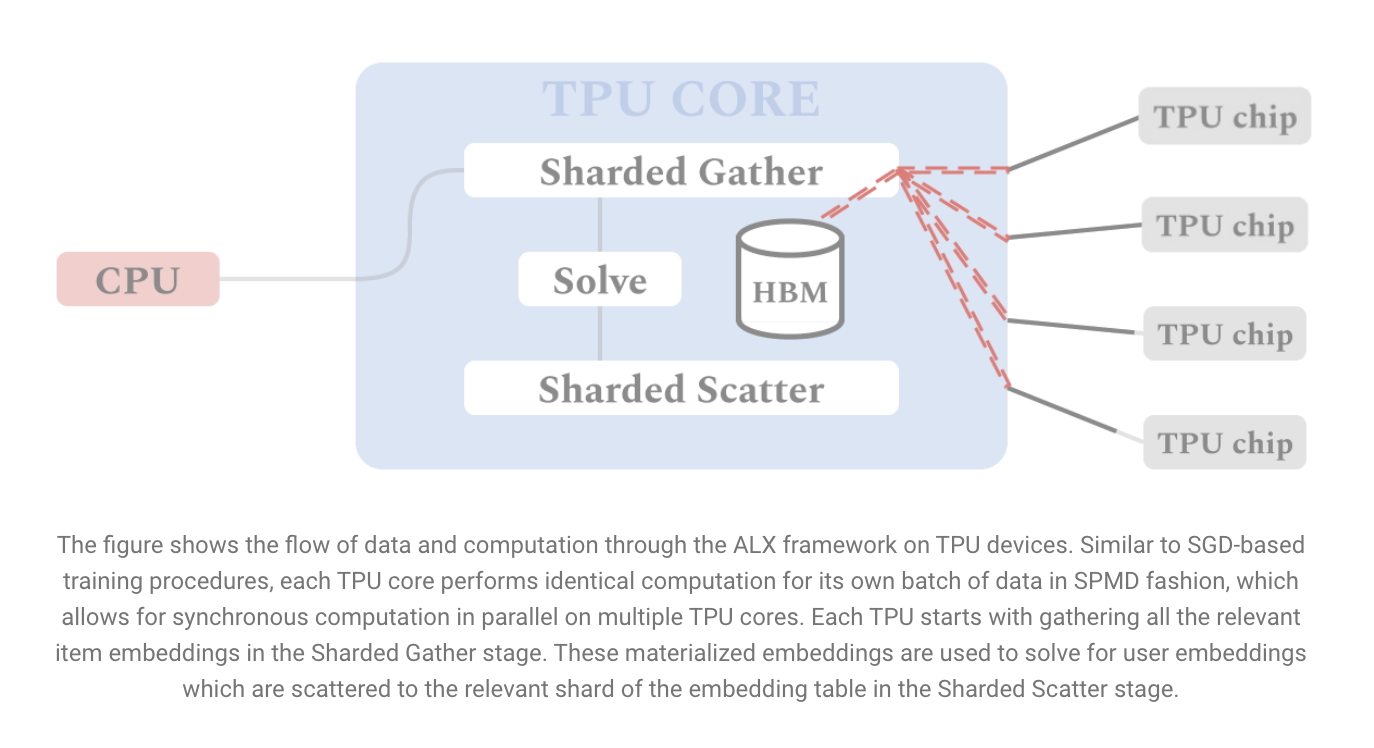
The method researchers proposed uses both model and data parallelism. Any future improvement in matrix factorization should be evaluated based on scalability. Each TPU core saves a slice of the embedding table and trains on a different data slice in mini-batches. To further study large-scale matrix factorization algorithms and demonstrate their implementation’s scalability, they also built and released a real-world weblink prediction dataset called WebGraph. WebGraph dataset is a large-scale weblink pedication dataset. This dataset helps with the scaling properties of ALX. Increase the size of real-world problems. After evaluating the result of ALX, it is shown that all the variants of the WebGraph dataset with scaling analysis demonstrate the high parallel efficiency of the proposed implementation.
Paper: https://arxiv.org/pdf/2112.02194.pdf
Code: https://github.com/google-research/google-research/tree/master/alx
WebGraph Dataset: https://www.tensorflow.org/datasets/catalog/web_graph
Source: https://ai.googleblog.com/2022/04/large-scale-matrix-factorization-on-tpus.html
Reference: https://towardsdatascience.com/prototyping-a-recommender-system-step-by-step-part-2-alternating-least-square-als-matrix-4a76c58714a1
Credit: Source link
Comments are closed.