Waymo and Google Researchers Propose a Simple Framework, called PolyLoss, to View and Design Loss Functions as a Linear Combination of Polynomial Functions
This Article Is Based On The Research 'POLYLOSS: A POLYNOMIAL EXPANSION PERSPECTIVE OF CLASSIFICATION LOSS FUNCTIONS'. All Credit For This Research Goes To The Researchers Of This Paper 👏👏👏 Please Don't Forget To Join Our ML Subreddit
We often design a deep learning model and prepare training data but don’t know the appropriate loss function to employ. A Loss Function is at the heart of any machine learning model, allowing us to assess how distant our model’s predictions are from the true values. We strive to reduce the loss function to increase the accuracy of our model. For classification models, we are all familiar with regularly used loss functions such as cross-entropy.
We should all consider loss functions in the same way that we consider model architecture or the optimizer, and it is essential that we do so. We can utilize generally used loss functions or create our own custom loss functions. PolyLoss, created by a team of Waymo and Google researchers, is a simple framework that redesigns loss functions as a linear combination of several polynomial functions. The team concluded that a decent loss function may take much more flexible forms and should not be limited to the most commonly used ones.
The key insight of the team was to decompose frequently used classification loss functions like cross-entropy loss into a set of weighted polynomial bases. Each polynomial basis is weighted by a polynomial coefficient, allowing us to simply modify the relevance of various bases for different applications. The PolyLoss becomes equivalent to the frequently used cross-entropy loss for a given value of the polynomial coefficient, although this coefficient assignment may not be optimal. According to the PolyLoss team, the four key takeaways are:

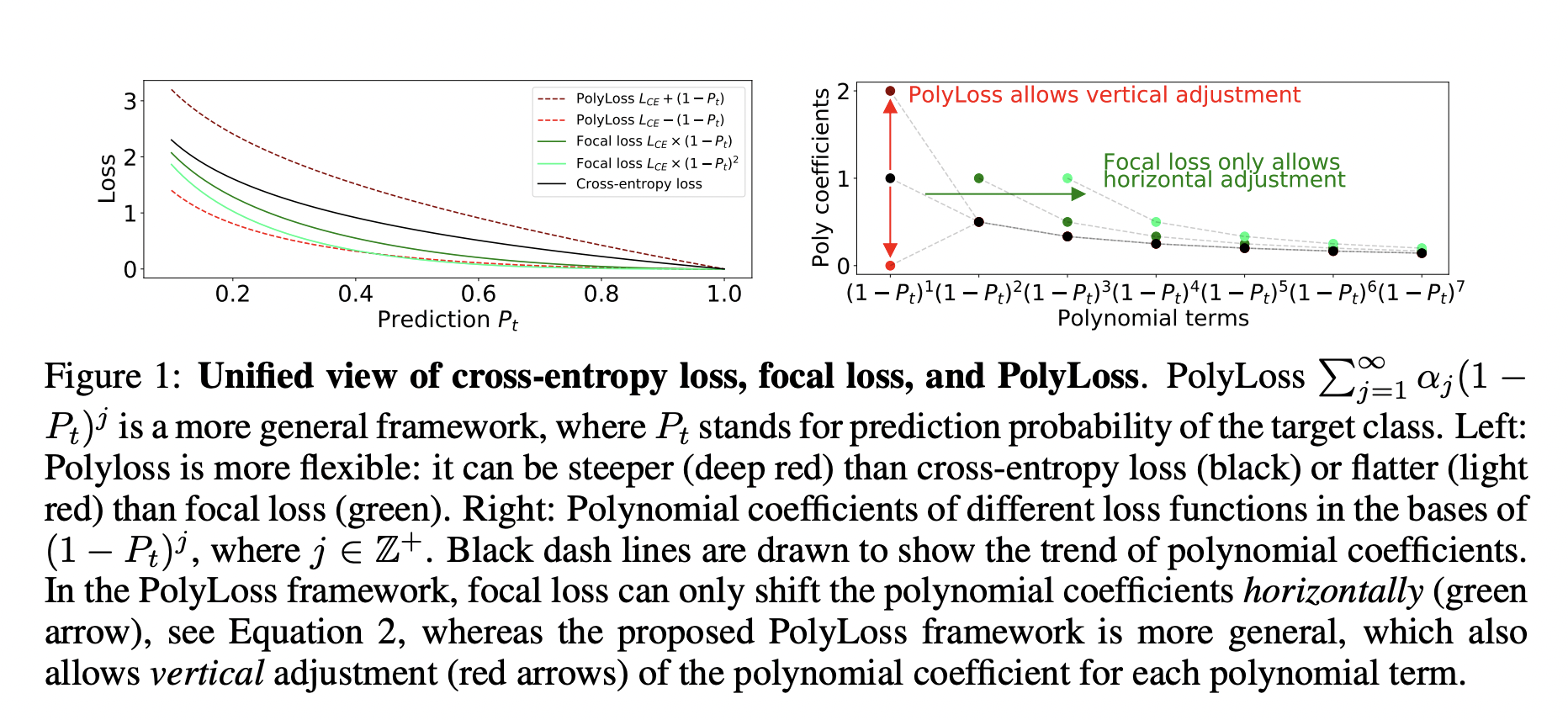
- Earlier loss functions – By horizontally shifting polynomial coefficients, the new framework helps explain cross-entropy and focal loss as a specific example of the PolyLoss family.
- New Loss Function Formulation – Vertically manipulating polynomial coefficients yields previously unknown polynomial loss functions.
- New discoveries – Existing loss functions, such as focal loss, are useful but not ideal for unbalanced datasets.
- New discoveries – Existing loss functions, such as focal loss, are useful but not ideal for unbalanced datasets.
- Extensive Experiments – PolyLoss was tested on various tasks, models, and datasets and has shown improvements on all fronts, as illustrated in the graphic below.

Finally, PolyLoss gives a unified view on typical loss functions for classification tasks. Under the polynomial expansion, the focal loss is defined as a horizontal shift of the polynomial coefficients in comparison to cross-entropy loss. This new discovery promotes the investigation of an additional dimension, namely vertically modifying the polynomial coefficients. The PolyLoss framework allows you to change the form of the loss function by modifying the polynomial coefficients. A simple and effective Poly-1 formulation has been presented in this context.
Poly-1 improves a number of models across numerous tasks and datasets by simply adjusting the coefficient of the leading polynomial coefficient with one more hyperparameter. Researchers believe that the Poly-1 formulation’s simplicity (one more line of code) and efficacy will lead to its use in more categorization applications than have been examined so far. PolyLoss demonstrates how a simple change can lead to significant improvements even on well-established state-of-the-art models. These findings will motivate researchers to go beyond the regularly utilized cross-entropy and focal loss functions, as well as the simplest Poly-1 loss initially proposed. We all should expect better loss functions in the near future.
Paper: https://openreview.net/pdf?id=gSdSJoenupI
Credit: Source link
Comments are closed.