Google AI Introduces A Method For Automating Inter- And Intra-Operator Parallelism For Distributed Deep Learning
This Article Is Based On The Research Paper 'Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning'. All Credit For This Research Goes To The Researchers 👏👏👏 Please Don't Forget To Join Our ML Subreddit
The memory capacity of single accelerators has swiftly overtaken the rapidly rising size of deep learning models in recent years. Earlier models, such as BERT (with a parameter size of 1GB), may scale across accelerators quickly by utilizing data parallelism, which duplicates model weights across accelerators while splitting and distributing training data. Recent huge models, such as GPT-3 (with a parameter size of 175GB), can only be scaled through model parallelism training, which involves partitioning a single model across many machines.
While model parallelism solutions allow for the training of significant models, they are more challenging to implement since they must be tailored to the target neural networks and computing clusters. Megatron-LM, for example, splits weight matrices by rows or columns and then synchronizes the results across devices using a model parallelism technique. Different operators in a neural network are divided into several groups, and the input data is divided into micro-batches that are run in a pipelined method.
Model parallelism sometimes necessitates considerable work from system specialists to determine the best parallelism strategy for a given model. However, most machine learning (ML) researchers find that doing so is excessively time-consuming, as their primary goal is to run a model, with model performance being a secondary concern. As a result, there is still the possibility of automating model parallelism so that it may be applied to huge models with ease.

A method for automating the complex process of parallelizing a model is “Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning.” Alpa can turn any JAX neural network into a distributed version with an efficient parallelization approach that can be run on a user-provided device cluster with just one line of code. Alpa’s code is open-sourced to the rest of the scientific community.
Existing ML parallelization algorithms can be classified into inter-operator parallelism and intra-operator parallelism. Separate operators are assigned to different devices in inter-operator parallelism, which is sometimes expedited by a pipeline execution schedule (e.g., pipeline parallelism). Individual operators are split and executed on multiple devices with intra-operator parallelism, including data parallelism, operator parallelism, and expert parallelism. Collective communication is often used to synchronize the results across devices.
The variability of a typical compute cluster readily correlates to the difference between these two techniques. The inter-operator parallelism requires less communication bandwidth because it only transmits activations between operators on separate accelerators. However, due to its pipeline data reliance, it suffers from device underutilization, with some operators idle while waiting for outputs from other operators. Intra-operator parallelism, on the other hand, avoids the data reliance issue but necessitates more communication across equipment.
The GPUs within a node in a GPU cluster have better communication capabilities, allowing for intra-operator parallelism. The inter-operator parallelism is favored since GPUs on separate nodes are frequently connected with significantly lower bandwidth (e.g., ethernet).
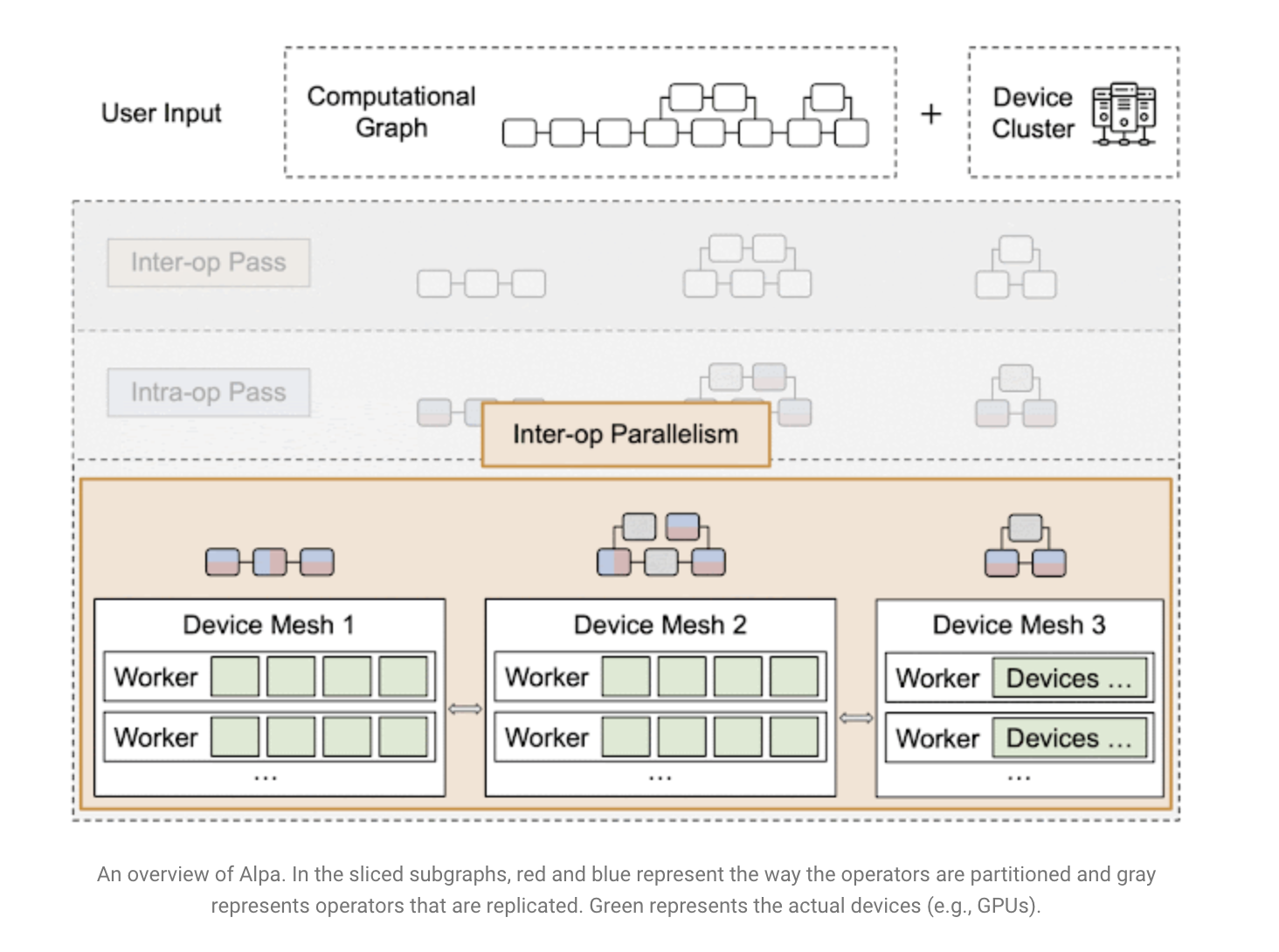
Alpa as a compiler performs several passes when provided a computational graph and a device cluster from a user by exploiting heterogeneous mapping. The inter-operator pass divides the computational graph into subgraphs and the device cluster into submeshes (i.e., a partitioned device cluster). It determines the most efficient way to assign a subgraph to a submesh. The intra-operator pass then uses the inter-operator pass to discover the optimum intra-operator parallelism strategy for each pipeline step. Finally, the runtime orchestration pass creates a static plan that arranges computation and communication while executing the distributed computational graph on the actual device cluster.

Intra-operator parallelism divides a tensor on a device mesh. A typical 3D tensor in a Transformer model with a specified batch, sequence, and hidden dimensions is depicted below. The batch dimension is divided into device mesh dimension 0 (mesh0), the concealed size is divided into device mesh dimension 1 (mesh1), and the sequence dimension is copied to each processor.

A set of parallelization algorithms are defined for each operator in a computational graph using Alpa’s tensor partitions. Because one tensor might be the output of one operator and the input of another, defining parallelization techniques on operators can lead to potential conflicts on tensor partitions. Re-partitioning between the two operators is required in this instance, which incurs additional communication costs.

The intra-operator pass is based on an Integer-Linear Programming (ILP) problem using the partitions of each operator and re-partition costs. To enumerate the partition techniques, a one-hot variable vector was created for each operator. The goal of the ILP is to reduce the total cost of computation and communication (node cost) and to re-partition communication costs (edge cost). The ILP solution corresponds to a single way to split the original computational graph.

The inter-operator pass slices the computational graph and device cluster for pipeline parallelism. The pipeline stages indicate a submesh running a subgraph, and the boxes represent micro-batches of input. The horizontal axis indicates time, while the vertical axis depicts the pipeline step at which a micro-batch is performed. The inter-operator pass’ aims to reduce overall execution latency, which is the sum of all workload execution on the device, as shown in the diagram below.

Alpa employs a Dynamic Programming (DP) technique to reduce overall latency. After flattening the computational graph, it is sent into the intra-operator pass, which profiles the performance of all feasible partitions of the device cluster into submeshes. The runtime creates and delivers a static sequence of execution instructions for each device submesh when the inter-and intra-operator parallelization techniques are complete.
RUN a specific subgraph, SEND/RECEIVE tensors from other meshes, or DELETE a specific tensor to free memory are examples of these instructions. Without further coordination, the devices may execute the computational graph by following the instructions. Alpa was tested using eight AWS p3.16xlarge instances, each with eight 16 GB V100 GPUs, totaling 64 GPUs. The effects of increasing the number of GPUs while increasing the model size were investigated.
Three models: (1) the regular Transformer model (GPT); (2) the GShard-MoE model, which is a transformer with a mixture of expert layers; and (3) Wide-ResNet, which is a radically different model with no current expert-designed model parallelization method were tested. The cluster’s performance is measured in Peta-floating-point operations per second (PFLOPS).
For GPT, Alpa produces a parallelization approach comparable to the best current framework, Megatron-ML, and equals its performance. Alpa surpasses the best expert-designed baseline on GPU (i.e., Deepspeed) by up to 8 times for GShard-MoE. Wide-ResNet results indicate that Alpa can find the best parallelization approach for models that professionals haven’t researched.
Designing an appropriate parallelization strategy for distributed model-parallel deep learning has been challenging and time-consuming. Alpa is a novel framework for automated model-parallel distributed training that utilizes intra- and inter-operator parallelism. Alpa will hopefully democratize distributed model parallel learning and speed up building big deep learning models.
Paper: https://arxiv.org/pdf/2201.12023.pdf
Code: https://github.com/alpa-projects/alpa
Source: https://ai.googleblog.com/2022/05/alpa-automated-model-parallel-deep.html
Credit: Source link
Comments are closed.