AI2 Introduces Efficient Hierarchical Domain Adaptation for Pretrained Language Models
This Article Is Based On The Research Paper 'Efficient Hierarchical Domain Adaptation for Pretrained Language Models'. All Credit For This Research Goes To The Researchers 👏👏👏 Please Don't Forget To Join Our ML Subreddit
Many natural language processing (NLP) benchmarks have seen significant advancement thanks to pretrained language models (PLMs) trained on large general-domain corpora.
Sparse models that combine expertise have recently been presented as a way to improve training efficiency. Individual domains are often assumed to be unique in previous work, and models are created accordingly. Because the parameters grow linearly with the domains, this approach does not scale well across several domains. It also prevents sharing representations between related domains during training because each domain is modeled separately.
AI2 has developed a hierarchical structure to describe textual domains that may capture both domain-specific and general-domain information.

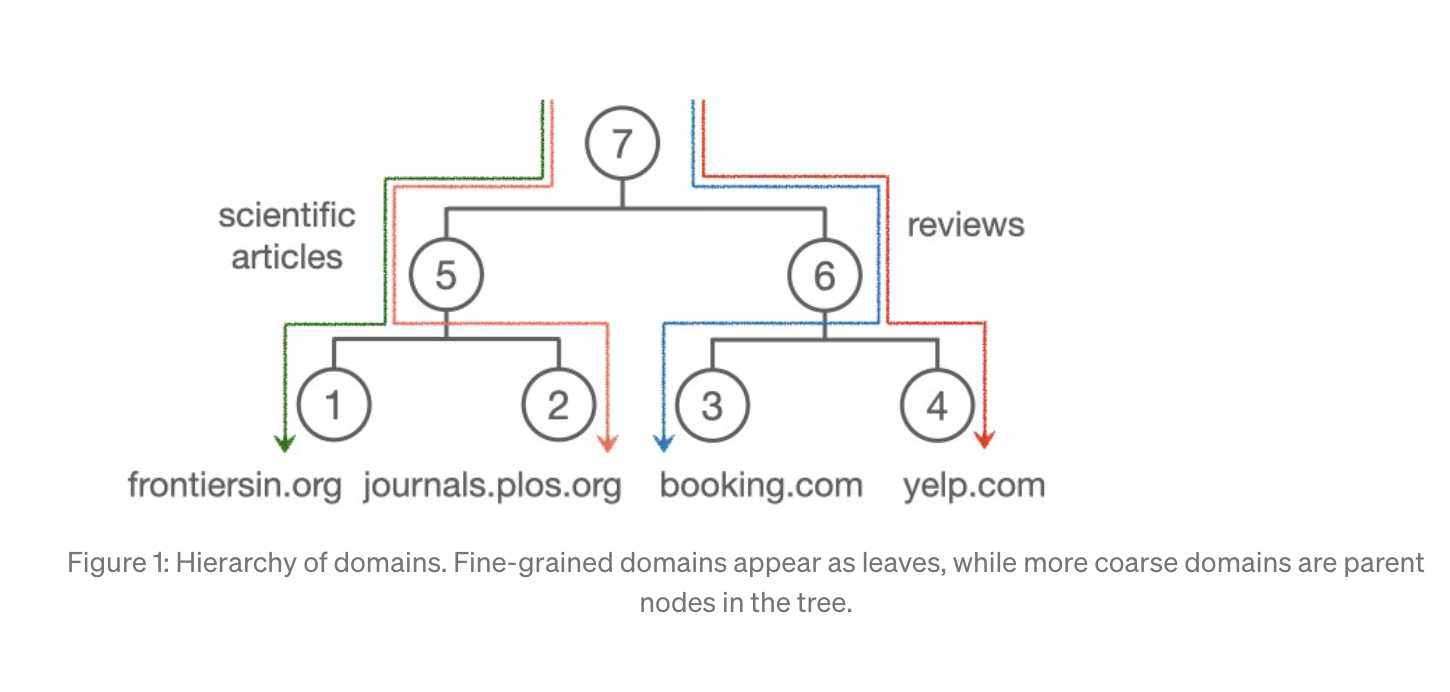
The study proposed in the paper “Efficient Hierarchical Domain Adaptation for Pretrained Language Models” is based on the hypothesis that domains overlap and have varying degrees of granularity. The leaf nodes in this tree are used to represent different domains. Domains grow more general as one gets closer to the tree’s base.

The researchers use the example of a sentiment model processing hotel reviews that would benefit from integrating data from restaurant ratings benefiting from cooking recipes. But combining hotel reviews and recipes could be harmful.
They aimed to model the relations between domains and selectively share information to allow positive transfer and avoid negative interference. For this, they used a data-driven approach to modeling domains that automatically clusters them in a tree using PLM representations. Then, they introduce an efficient method that specializes in a PLM in many domains leveraging their hierarchical structure.
Adapters, which are lightweight layers inserted after each transformer layer, show that parameters between related domains can be shared. Each node in the tree is coupled with a unique set of adapters that are only active in one domain. These adapters are incorporated into a frozen pretrained language model (PLM), such as GPT-2 [3]. For each discrete domain, the model is trained by activating a different path through the tree.
The researchers claim that they can easily specialize a PLM in N domains using their proposed technique while avoiding negative transfer from unrelated domains.
They gave used text from 30 of C4’s top 100 most high-resource websites, a corpus containing publicly available documentation.
They evaluate their model’s effectiveness in two different contexts:
- First, they create a tree structure manually, with websites serving as the leaves. The method outperforms previous techniques due to When tested in-domain, our technique surpasses previous work, which included single and multi-domain adapters added to GPT2.
- Furthermore, the findings show the method’s capability to generalize to held-out webpages better than the baselines.
The team applied this methodology to over 100 websites in a multi-domain context, containing publicly available documentation. They use representations from GPT-2 with a Gaussian Mixture Model (GMM) and hierarchical clustering to infer the hierarchical structure unsupervised.
When measured in-domain, empirical data reveal significant improvements over strong baselines. When tested on held-out webpages, an efficient inference-time technique can even average over numerous paths through the tree, enhancing generalization. The clusters model textual domains in this fashion and the GMM provides a mechanism for finding the nearest training websites to every held-out website.
Being an unsupervised technique, the proposed method can be applied generally. The team plans to use this ability in their future work to regulate and alter the created context of PLMs for downstream tasks.
Paper: https://arxiv.org/pdf/2112.08786.pdf
Github: https://github.com/alexandra-chron/hierarchical-domain-adaptation
Source: https://blog.allenai.org/efficient-hierarchical-domain-adaptation-using-pretrained-language-models-fdd04c001230
Credit: Source link
Comments are closed.