In A Latest ML Research, CMU Researchers Explains The Connection Between MBRL And The World Of BOED By Deriving An Acquisition Function
This Article Is Based On The Research Paper 'An Experimental Design Perspective on Model-Based Reinforcement Learning'. All Credit For This Research Goes To The Researchers 👏👏👏 Please Don't Forget To Join Our ML Subreddit
Reinforcement Learning is all about an agent perceiving and interpreting its environment, taking actions, and learning through trial and error. To achieve this feat, the agent must explore the environment. This task is easy for domains where environments are easy to simulate, for example, in games like Go or environments where agents can play millions of games in a few days to discover the complete environment. However, this becomes a humongous task when it comes to real-world applications. For example, RL-based methods for regulating nuclear fusion power generation plasmas are promising. Still, the United States has only one operational tokamak, and its resources are in high demand. Even the most data-efficient RL algorithms require thousands of samples to solve even modestly complicated problems prohibitively expensive in plasma control and many other applications.
The problem lies with how RL works. Reinforcement learning has suffered for years from a curse of poor sample complexity. State-of-the-art model-free reinforcement learning algorithms routinely take tens of thousands of sample transitions to solve straightforward tasks and millions to solve moderately complex ones. In such a constrained environment, the critical question that researchers need to ask themselves is, “Which of the following data points would we collect from any place in the state-action space to best enhance our task solution?“
Traditionally agents chose actions and executed entire episodes to collect data. Researchers aim to solve this problem by studying the setting where the agent collects data sequentially and makes queries to the transition function with free choice of both the initial state and the action, essentially teleporting between states as it wishes. They refer to this setting as transition-query reinforcement learning (TQRL). TQRL is a slightly more informative form of access to the real environment. The goal is to optimize the objective while minimizing the number of samples from the ground truth required to reach good performance.

In a typical RL model for decision-making issues, the agent begins with no understanding of how its actions affect the world. The agent may then query multiple state-action pairs to explore the environment and select the optimum behavior policy. In the plasma control job, for example, the states represent different physical structures of the plasma, and potential actions include injecting power or adjusting the current. Initially, the agent does not know how its activities affect the plasma’s conditions. As a result, it must swiftly explore the space to ensure the physical system’s effective and safe operation, a necessity reflected in the associated reward function.
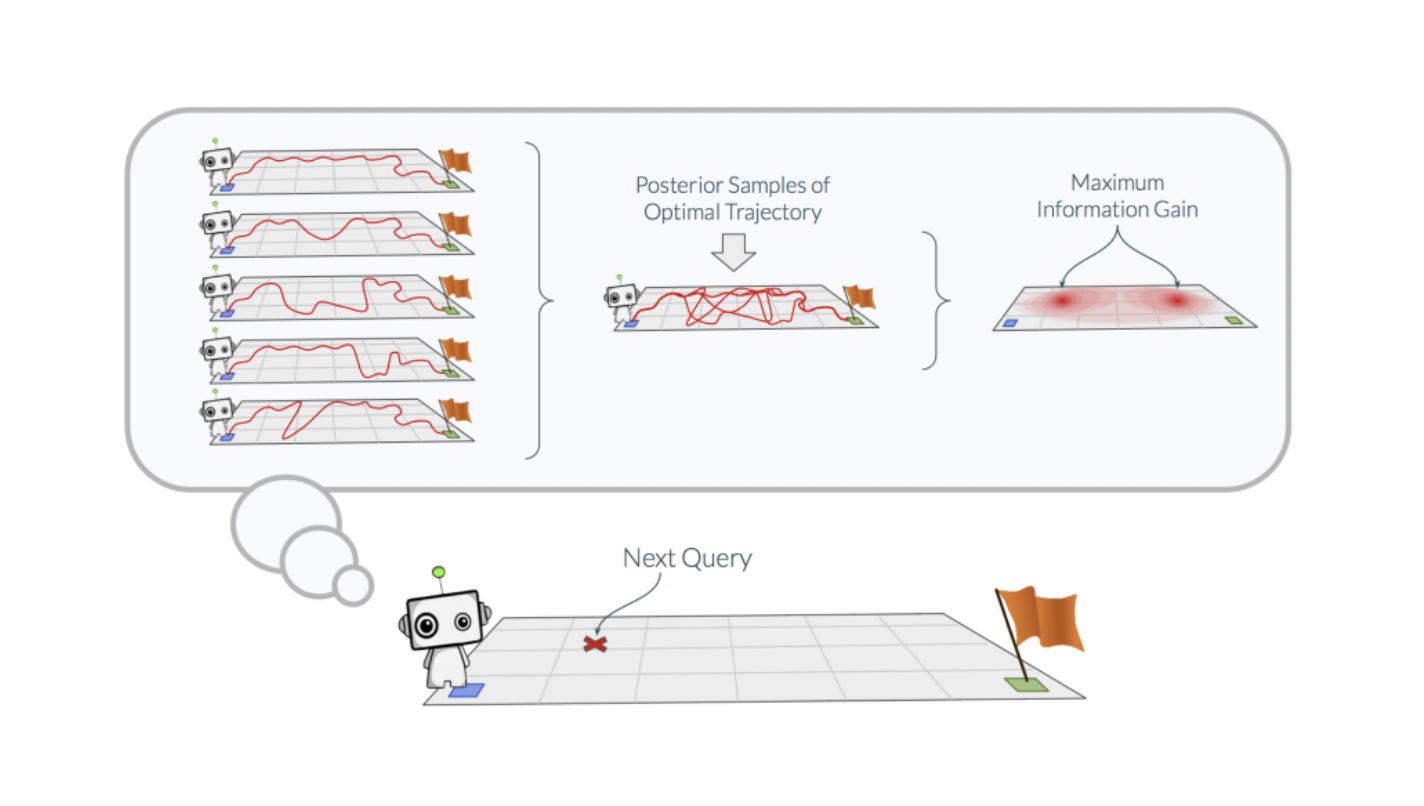
Indeed, there may be areas of the state space that the best strategy is unlikely to traverse. As a result, we only need to estimate the optimum policy in the areas of the state space that the ideal policy visits, as indicated in the graphic below.

The novel concept here is inspired by BOED and Bayesian algorithm to effectively choose data points, allowing the agent to choose queries sequentially. It quickly finds a good policy. Researchers give a simple greedy procedure which they call BARL (Bayesian Active Reinforcement Learning) for use in their acquisition function to acquire data given some initial dataset. Several experiments prove that BARL significantly improved model accuracy and reduced data requirements which means it selected the correct data points while making queries. Researchers aim to extend these techniques to high dimensionality data which is necessary for many real-world applications.
Paper: https://arxiv.org/abs/2112.05244
Source: https://blog.ml.cmu.edu/2022/05/06/barl/
Credit: Source link
Comments are closed.