AI Researchers Develop ‘CogView2’ For Text-To-Image System That Achieves Significant Speedups 10x Faster Than CogView
This Article Is Based On The Research Paper 'CogView2: Faster and Better Text-to-Image Generation via Hierarchical Transformers'. All Credit For This Research Goes To The Researchers 👏👏👏 Please Don't Forget To Join Our ML Subreddit
Natural language processing and Computer Vision have become hot study disciplines in recent years, thanks to the rise of artificial intelligence and deep learning. Many scholars have focused their attention and study on text to image as a fundamental topic in the discipline. Text to an image is the process of creating a realistic image from a text description, which requires processing ambiguous and partial information in natural language descriptions. Text to picture is a driving force behind multimodal learning and cross-modal generation, with applications as diverse as cross-modal information retrieval, photo editing, and computer-aided design. Large-scale pretrained transformers, such as DALL-E and CogView, have substantially advanced text-to-image generation. These models are prone to the flaws like – Slow generation, Expensive high-resolution training, and Unidirectional.
With its startlingly hyper-realistic graphics, OpenAI’s recently released state-of-the-art DALL-E-2 model has gotten global mainstream media attention. Slow generation speeds and pricey high-resolution training costs limit high-performance autoregressive models like DALL-E-2 and 2021’s CogView. Furthermore, these models’ unidirectional token generation mechanism differs from that used by vision transformers (ViTs), which limits their application to classic visual tasks like picture categorization and object recognition.
A pre-trained Cross-Modal general Language Model (CogLM) has been generated for efficient text and image token prediction. CogView2 hierarchical text-to-image system generates images with comparable resolution and quality at speeds up to 10x quicker than CogView when fine-tuned for fast super-resolution.


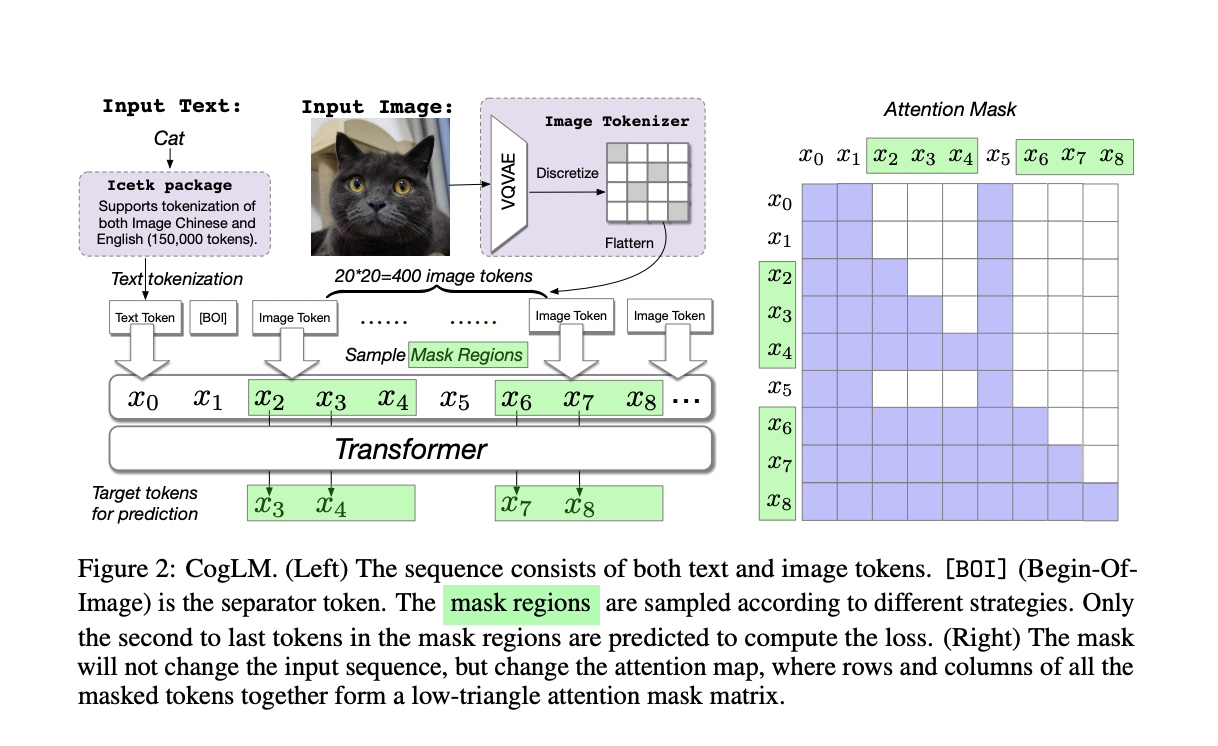
The General Language Model (GLM) recommends that direct mask prediction be replaced with block-wise auto-regressive generation in NLP. The cross-modal generic language model is a more simple and general language model for both text and image data, based on the analysis above (CogLM). However, for photos, a portion of its design is unnecessary. The sizes of the masked picture patches, for example, are set. Thus there is no need for power to fill blocks of indeterminate length as in NLP. Furthermore, GLM inserts a sentinel token for each mask region to predict its initial token, lengthening the sequence and limiting the use of 2D local attention.
The project seeks to provide a general and straightforward language model that blends autoregressive generation and bidirectional context-aware mask prediction for both text and image data. In the pretraining stage, the researchers use a unified tokenizer (ICE Tokenizer, Icetk) for Picture, Chinese, and English to capture bilingual text and image tokens. They expand the model up to six billion parameters using a transformer with Sandwich LayerNorm as the CogLM backbone. An innovative and versatile masking method is created and implemented to increase model performance and enable fine-tuning for various downstream tasks.
The team also offers the CogView2 system, which would allow for interactive text-guided image editing and quick super-resolution. Their hierarchical generation mechanism is summarized as follows:
- First, the pre-trained CogLM is used to generate a batch of low-resolution images (2020 tokens in CogView2) and then (optionally) filter out the bad samples using the perplexity of CogLM image captioning, which is the CogView post-selection approach.
- A direct super-resolution module fine-tuned from the pretrained CogLM maps the resulting images directly into 6060-token images. Local attention is used to save money on training, which is implemented by the proprietary CUDA kernel. This process frequently results in high-resolution photos with irregular textures and a lack of details.
- Another iterative super-resolution module fine-tuned from the pretrained CogLM refines these high-resolution images. Most tokens are re-masked and re-generated using a local parallel autoregressive (LoPAR) method, significantly faster than a traditional autoregressive generation.
The researchers ran 30 million text-image pairs through comprehensive tests and compared the proposed CogView2 to popular benchmarks like DALL-E-2 and XMC-GAN.

The results show that fine-tuning the CogLM on the MS-COCO dataset significantly improves performance on the FID metric. The resulting CogView2 text-to-image system can generate images with better quality and resolutions ten times faster than CogView and achieve results comparable to current state-of-the-art DALL-E-2 baselines.
Plug-in Improved Techniques for Transformers
Cluster Sampling
The sampling approach over the projected token distribution is critical in an auto-regressive generation. The most prevalent strategies, top-k or top-p (nucleus) sampling, have an incomplete truncation problem.
VQVAE, p Truncation with top-k sampling, where the embeddings of some tokens are quite similar, is used to learn the vocabulary of picture tokens. A vocabulary of 20,000 tokens is utilized to express frequent patterns at a more acceptable resolution, which is three times greater than the previous efforts, compounding the situation. In icetk, for example, there are roughly 42 tokens that are fundamentally “white” and only display tiny changes when connected to other tokens. Although the sum of the probability of these “white” tokens may be significant enough, top-k sampling could filter out the majority of them. The issue is depicted in Figure 5.

Textual Attention is Prioritized
In CogLM’s enormous training data, most text-image combinations are marginally meaningful. Even if the model perfectly fits the data, it should still have a reasonable chance of producing irrelevant images. The explainability of the attention operation is explained to boost the relevance. A constant c is applied to all attention scores from picture tokens to text tokens. This technique consumes minimal time but significantly increases the linguistic significance of the images generated. In actuality, c will not affect the image quality.
Local Awareness
One of the essential features of visual data is its locality. Before ViTs, visual computing was dominated by local processes like convolution. Even in the ViTs, the exchanges between local tokens receive the most attention. It was discovered that fine-tuning the pre-trained CogLM with local and textual attention is often compatible with the pretraining global attention weights. However, utilizing a high-level framework like Pytorch, 2D local attention cannot be implemented efficiently. A CUDA kernel is created that supports both 2D local attention and 2D auto-regressive local attention, and cross-resolution local attention. Local attention with a kernel size of 9 X 9 is employed in the super-resolution modules, which is 40 X times faster and uses 1% less memory than global attention on a 4,096 sequence with a hidden size of 64 per head.
Overall, the work uses hierarchical transformers to help autoregressive text-to-image models overcome slow generation and high complexity difficulties and bridge the gap between text-to-image pretraining and visual transformers.
Paper: https://arxiv.org/pdf/2204.14217.pdf
Github: https://github.com/thudm/cogview2
Credit: Source link
Comments are closed.