Baidu AI Research Brings A Significant Upgrade To PaddleOCR’s Open-Source OCR System

This Article Is Based On The Research Article 'PaddleOCR, an Easy-to-Use and Open-Source OCR System, Rolls out Major Upgrade With Improved Accuracy and New Annotation Functions'. All Credit For This Research Goes To The Researchers of This Project 👏👏👏 Please Don't Forget To Join Our ML Subreddit
A significant enhancement has been made to PaddleOCR, the multilingual optical character recognition (OCR) toolkits. With over 80 different multi-language recognition models and an easy-to-use interface, PaddleOCR is an open-source OCR repository worth checking out.
OCRv3 PP-OCRv3 has a 5% to 11% increase in accuracy in English and multilingual scenarios. Annotation functions for tables, irregular text pictures, and essential information extraction tasks have been added to PPOCRLabelv2. “Dive into OCR,” a new interactive e-book, is now available.

OCR has become a vital technology enabler by transforming printed images into searchable digital information in the digital age. OA systems, online education, factory automation, and map creations are just a few examples of how it has been employed. PaddleOCR is a real-world OCR program.

Weighing in at just 17 ounces, this OCR system is small enough to fit in the palm of your hand. It recognizes more than 80 other multi-language models and the more commonly spoken languages such as English and Chinese. Automated annotation software Table and fundamental information annotation modes are supported by the PPOCRLabel. Stylized text is an easy way to generate many images close to the target scene image’s appearance.
It is easy to use and supports PIP installation. It also supports various operating systems, including Linux, Windows, and macOS. There are currently more than 21K stars on PaddleOCR’s GitHub page as of this writing. Developers can benefit from the multilingual, fantastic, leading, and practical OCR tools that enable them to train better models and put them into practice.
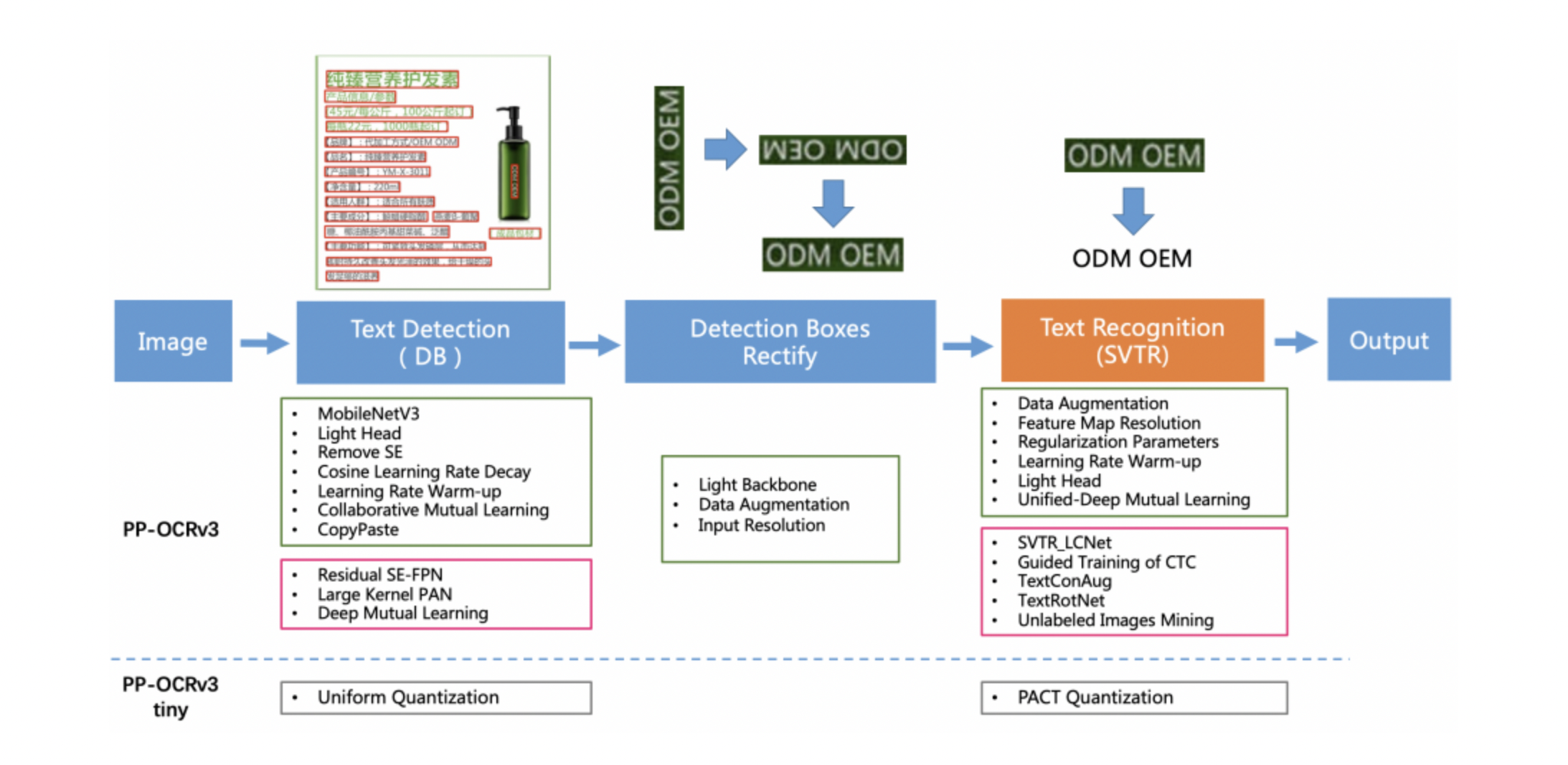
The PaddleOCR team has created an ultra-lightweight OCR device, dubbed PP-OCR, for use in the OCR business, focusing on accuracy and speed. On the back of PP-OCRv2, PP-OCRv3 receives an enhancement. PP-text OCRv3’s detection and recognition models can be optimized in nine ways.
At a similar rate of speed, compared to PP-OCRv2, the precision of English models has increased by 11%, while Chinese models have increased by 5%. The average recognition accuracy of eighty multilingual models has increased by more than 5%. There are no significant changes to the detection network.

PP-OCRv3 improves on the instructor and student models in a more holistic way. It is roughly 11 times more difficult to forecast accurately with SVTR inty (a lightweight text recognition network) than with PP-OCRv2, even if it has a higher recognition accuracy. CPUs take about 100 milliseconds to predict a single line of text.
PP-OCRv3 uses the following six optimization algorithms to speed up the recognition model, as indicated in the figure below.

To detect and re-recognize images automatically, PPOCRLabel has an integrated model of partial optical character recognition (PP-OCR). The new PPOCRLabelv2 has the following new capabilities:
- New ways to annotate tables, images with irregular text (such as seals and bends), and activities requiring the extraction of critical information;
- Box locking, batch processing, image rotation, and dataset segmentation
- Rotation of the box is now supported; it may also be installed via the WHL package.

“Dive Into OCR” is a textbook developed by the PaddleOCR community that integrates OCR theory and practice. PaddleOCR supports a wide range of cutting-edge OCR algorithms and produces industrial featured models/solutions, such as the OCR model, PP-OCR, and PP-Structure.
Source: http://research.baidu.com/Blog/index-view?id=168
Credit: Source link
Comments are closed.