LAION Presents The Largest Freely Available Image-Text Dataset With More Than 5 Billion CLIP-Filtered Image-Text Pairs, 14x Bigger Than LAION-400M
This Article Is Based On The LAION Article 'LAION-5B: A NEW ERA OF OPEN LARGE-SCALE MULTI-MODAL DATASETS'. All Credit For This Research Goes To The Researchers of This Project 👏👏👏 Please Don't Forget To Join Our ML Subreddit
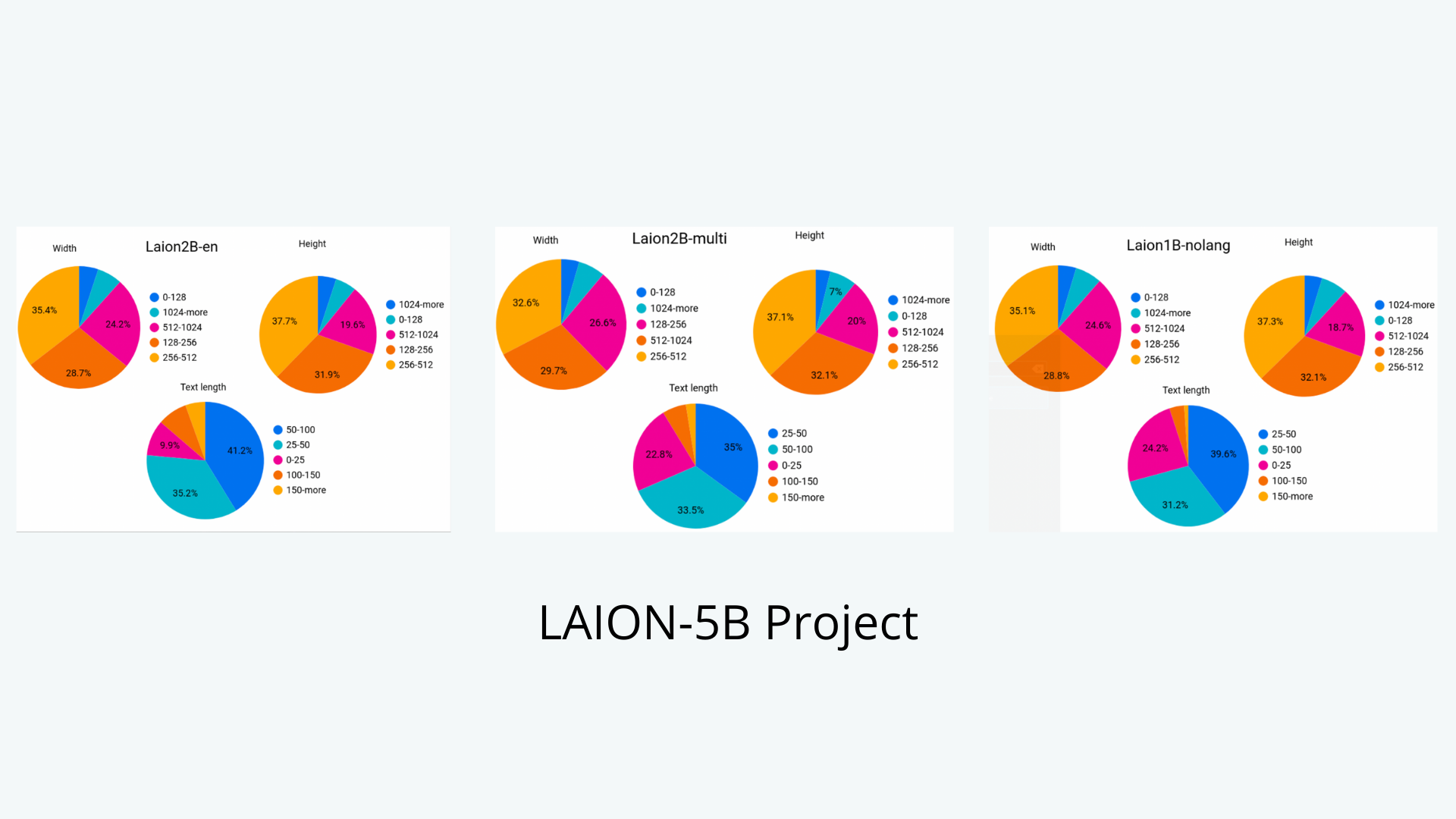
LAION-5B, an AI training dataset with over five billion image-text pairs, was recently released on the Large-scale Artificial Intelligence Open Network (LAION) blog. This dataset, which is 14 times larger than its predecessor LAION-400M, contains images and captions collected from the internet, making it the most prominent openly available image-text dataset. The dataset contains 2.32 billion photos with English text, 2.26 billion images with text from other languages, and 1.27 billion images with unambiguous text language. The image tags with alt-text values were found by processing files from the Common Crawl collection. The images were retrieved and filtered with CLIP to keep only those whose content matched the alt-text description.
In recent years, large training datasets have fueled a surge in multimodal AI models, particularly those trained on image and textual data. OpenAI published a study in 2021 called Contrastive Language–Image Pre-training (CLIP), which was trained on 400 million image-text pairs and achieved remarkable performance on several multimodal benchmarks with no fine-tuning. Although OpenAI made the CLIP code and model weights open-source, they did not make their dataset public. As a result, LAION decided to try to duplicate OpenAI’s dataset collection, which was released last year. This LAION-400M is a dataset with 413 million image-text pairs that have been utilized in various studies and experiments. Several nearest-neighbor indices of the data, a web demo using the data for semantic search, and replication of CLIP trained on the data were also included in the release.
A three-stage workflow was used to collect the new dataset, LAION-5B. To begin, a distributed cluster of worker machines analyzed Common Crawl datafiles to capture all html image tags with alt-text properties. The alt-text was subjected to language detection; if the language detection confidence was low, the language was reported as “unknown.” The raw photos were retrieved from the tagged URLs and fed to a CLIP model and the alt-text to generate embeddings for both. The two embeddings were given a similarity score, and pairs with low similarity were eliminated. Duplicates were deleted, and examples with text less than five characters long or had an image resolution that was too high. This dataset opens up multi-language large-scale training and study of language-vision models to the general public, previously only available to individuals with substantial proprietary datasets. The LAION research team released the dataset intending to democratize multimodal AI research. The dataset can be downloaded from the HuggingFace website.
Source: https://laion.ai/laion-5b-a-new-era-of-open-large-scale-multi-modal-datasets/
LAION released the following packages under the LAION-5B project:
- laion2B-en 2.32 billion of these contain texts in the English language
- laion2B-multi 2.26 billion contain texts from 100+ other languages
- laion1B-nolang 1.27 billion have texts where a particular language couldn’t be clearly detected.
Other References:
- https://www.infoq.com/news/2022/05/laion-5b-image-text-dataset/
Credit: Source link
Comments are closed.