Huawei Noah Lab Develop A New Reinforcement Learning RL-Based Method That Can Automatically Recognize Critical Operators And Generate Common Operator Sequences Generalizable To Unseen Circuits

In logic synthesis, pre-mapping, technology mapping, and post-mapping optimizations are used to find equivalent representations of large-scale integrated circuits. LS is a sequential decision-making problem that may be expressed as a Markov decision process (MDP) and addressed using reinforcement learning (RL) algorithms.
Based on Logic Synthesis, a research team from Huawei Noah’s Ark Lab evaluates current RL-based LS approaches and finds that the learned policy of the RL algorithms is state-agnostic and provides a permutation invariant operator sequence. The team offers a unique RL-based method for automatically recognizing essential operators and producing common operator sequences that may be used in circuits that have never been seen before.
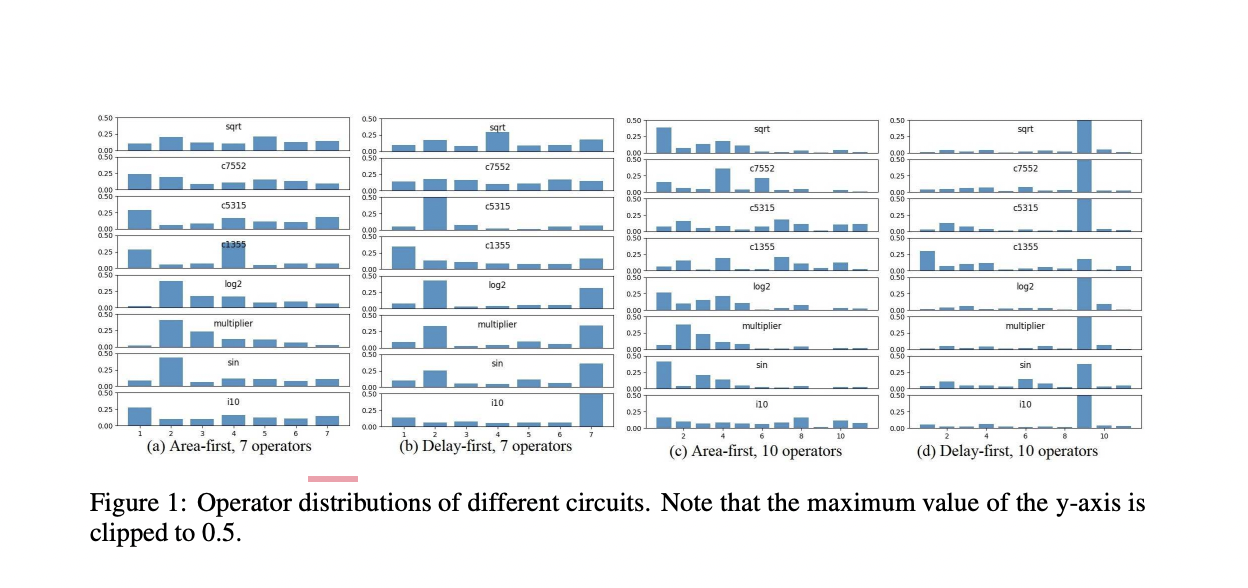
The main goal of RL-based LS is to learn a control strategy that specifies which operator to apply in various states, where the conditions are feature vectors in the current And-Inverter-Graph (AIG) circuit representation. The researchers discovered that:
1) The RL policy’s decisions are independent of circuit features.
2) The permutation of these operators has no effect on ultimate performance after extensive experimentation on the RL-based logic synthesis approach.
The researchers conclude that extracting circuit details is unnecessary.

The team developed a novel method for automatically recognizing critical operators and generating a familiar sequence for various circuits based on these findings. The procedure is divided into two parts: It first learns a shared policy for a set of rotations, then uses that policy to find the best-performing typical sequence. The standard series can then be utilized to optimize previously undiscovered circuits without the need for additional online learning or changes, saving time.
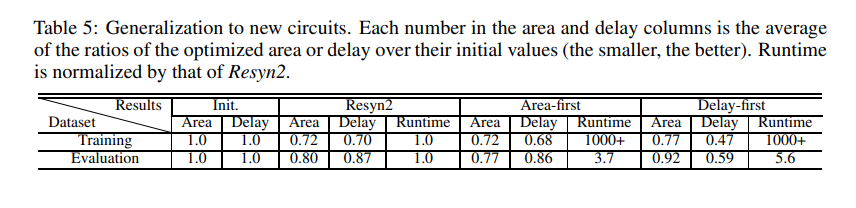
On the EPFL benchmark, the researchers tested their approach’s runtime efficiency and capacity to generalize to unknown circuits to demonstrate its effectiveness.

The proposed method can find a standard sequence, performs well in delay deduction, and dramatically reduces runtime. Because of its superior trade-offs between latency, space, and runtime also have a practical advantage for industrial applications.
This Article is written as a summay by Marktechpost Staff based on the Research Paper 'Rethinking Reinforcement Learning based Logic Synthesis'. All Credit For This Research Goes To The Researchers of This Project. Check out the paper. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.