Microsoft Introduce ‘AdaTest’: a Process for Adaptive Testing and Debugging of NLP Models Inspired by the Test Debug Cycle in Traditional Software Engineering

This Article is written as a summay by Marktechpost Staff based on the Research Paper 'Adaptive Testing and Debugging of NLP Models'. All Credit For This Research Goes To The Researchers of This Project. Check out the paper, blog and Github. Please Don't Forget To Join Our ML Subreddit
Platform models are large-scale models that serve as foundations for various applications. The ability of computers to interpret natural language has considerably improved due to recent advancements in these platform models. However, many real-world examples demonstrate that NLP models are far from ideal. Because debugging NLP models is challenging, significant problems affect practically every primary open-source and commercial NLP model, making them difficult to fix. Currently, there are two methods for debugging NLP models: user-driven and automated. User-driven approaches are flexible and can test any aspect of a model’s behavior, but they are labor-intensive and rely on highly varied human abilities to imagine errors. On the other hand, automated methods are quick and may cover a great input area. However, due to a lack of human direction, they can only assess if a model is accurate or wrong in minimal cases.
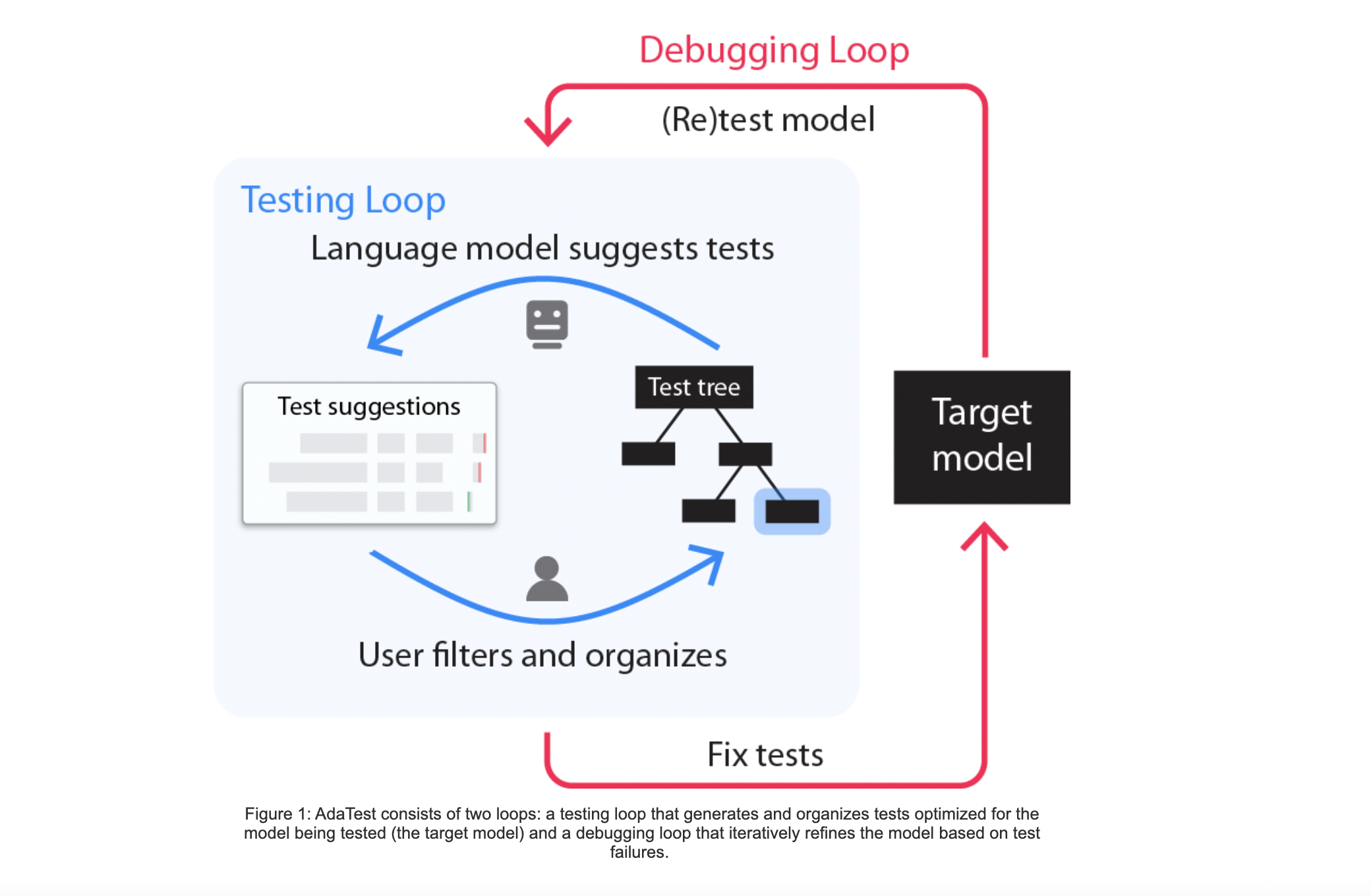
Microsoft Research investigated the possibility of combining the synergistic strengths of both user-driven and automated approaches, keeping the user in charge of defining what the model under test should do while leveraging the abilities of modern generative language models to generate at scale tests within a specific category of model behavior. Adaptive Testing and Debugging, or AdaTest for short, is the name given by the researchers to this human-AI team approach. AdaTest, an open-source tool, provides considerable productivity advantages for experienced users while being simple enough to empower a wide range of non-experts with no programming experience. With AdaTest, a large language model is given the duty of creating many tests to detect faults in the model. At the same time, a person leads the language model by picking appropriate tests and grouping them into semantically relevant subjects. Because the tests represent distinct types of labeled data, they may be used to discover issues and correct them in an iterative debugging loop akin to traditional software development.
AdaTest has a track record of commercial model failures, particularly when it comes to sentiment analysis. The team illustrates how the tool detects and fixes issues by identifying circumstances in which a model might regard comments from specific groups more adversely regarding sentiment analysis. The tool comprises an inner testing loop for finding bugs and an outer debugging loop for fixing them. A series of unit tests are run on distinct identities in the testing loop, each labeled separately. AdaTest leverages GPT-3, a large language model, to produce many comparable proposed tests to identify flaws when the basic model is proven to be failure-free. Only the top few failed, or near-failing tests are reviewed out of hundreds of created tests, with the rest being disregarded. The language model prompt for the subsequent proposals includes these user-filtered checks. The language model starts with tests that do not fail and gradually works its way up to produce greater failures as the testing loop is repeated.

AdaTest has also been tested to see if it helps professionals and non-experts write better tests and detect faults in models. Experts in machine learning and natural language processing were requested to test two models: a commercial sentiment classifier and GPT-2 for next word auto-complete. Participants were randomly allocated to either CheckList or AdaTest for each topic and model. AdaTest provided a fivefold improvement across all models and people in the trial, according to the researchers. Non-experts were also asked to put the Perspective API toxicity model to the test for content moderation, identifying non-toxic statements that were expected to be toxic for political opinions. AdaTest improved results by up to tenfold. The user studies revealed that anyone could use AdaTest. Such simple tools are critical for enabling model testing by people from all backgrounds, as testers with various lived experiences and perspectives are required to test different perspectives adequately. Once many bugs have been detected, model testers enter the outer debugging loop, where the discovered bugs are corrected, and the model is retested. The retesting stage of the debugging loop is crucial because once the tests have been utilized to repair the model, they are no longer test data but training data. Running the debugging loop on a substantial open-source model, RoBERTa demonstrates the importance of a test-fix-retest cycle. AdaTest’s effectiveness in a typical development environment was also assessed. According to the research, the tool can contribute significant bug-fixing value with a fraction of the effort required by standard methodologies.
AdaTest was established to encourage collaboration between humans and large language models, enabling us to use the benefits provided by both fully. Humans supply the issue specification that the language model lacks, while the language model creates quality tests on size and scope that humans are incapable of. Model testing and debugging are linked in the debugging loop to successfully address defects, bringing model development closer to the iterative nature of traditional software development. Human-AI collaboration is a viable path for machine learning advancement, and we expect this synergy to grow as large language models’ capabilities improve. The paper ‘Adaptive Testing and Debugging of NLP Models’ will also be presented at the 2022 Association for Computational Linguistics (ACL).
Credit: Source link
Comments are closed.