Researchers at Borealis AI Propose PUMA: Performance Unchanged Model Augmentation for Training Data Removal
This Article is written as a summay by Marktechpost Staff based on the Research Paper 'PUMA: Performance Unchanged Model Augmentation for Training Data Removal'. All Credit For This Research Goes To The Researchers of This Project. Check out the paper. Please Don't Forget To Join Our ML Subreddit
As the protection of personal data becomes more important in many countries and territories, the appropriate protection regulations1 allow individuals to revoke their consent to their data being used for data analysis and machine learning (ML) model training.
While retraining ML models by eliminating tagged data points is a viable method, frequent data removal requests inevitably place huge computational strain on real-time ML infrastructures. Additionally, cumulative data loss causes rapid performance decline. As a result, removing data’s distinctive properties while maintaining model performance is a crucial and difficult research subject.
Recent research has sought to solve the problem of data removal. Those methods, on the other hand, usually focus on specific machine learning algorithms and are difficult to apply to deep neural networks, which currently dominate ML research and applications. Other researchers have proposed solutions such as assembling multiple ML models to create a data removal-friendly model and explicitly calculating the contribution of each training data point as an additive function to provide a single-model solution. Unfortunately, such approaches are prohibitively expensive; maintaining a large number of sub-models and tracking the model training process is both impractical in real-world scenarios.
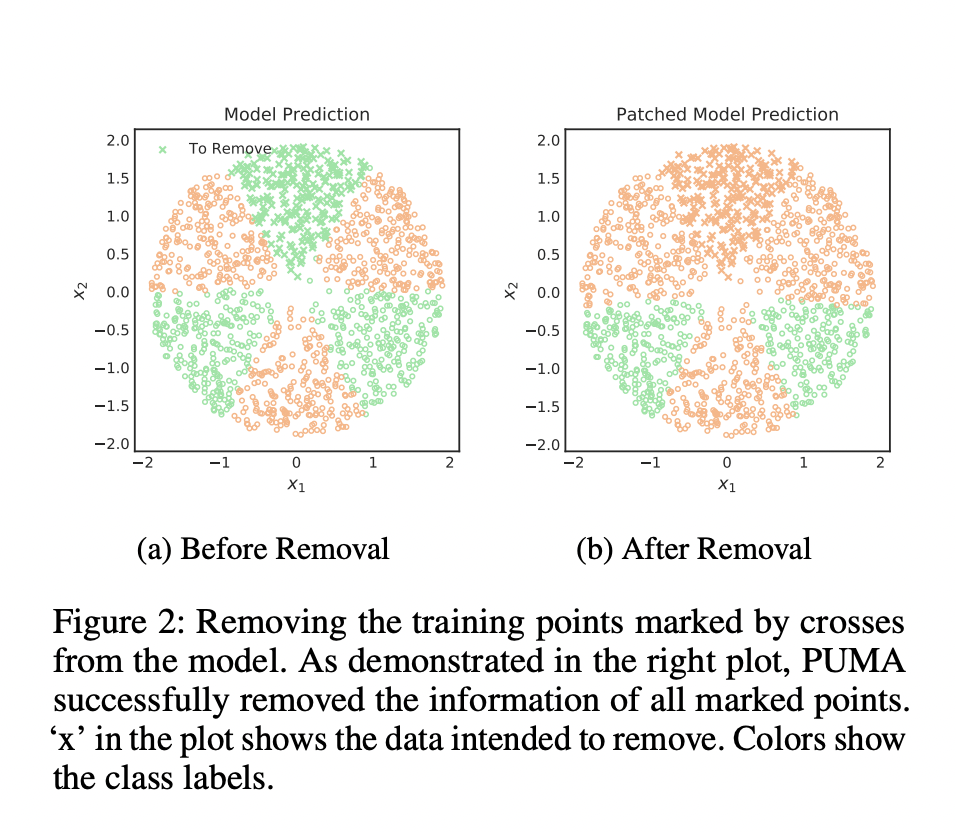
Researchers from Borealis AI recently proposed Performance Unchanged Model Augmentation (PUMA), a novel approach for rapidly erasing the distinctive characteristics of tagged data points from a trained model without incurring performance degradation.
In particular, the proposed PUMA framework models the impact of each training data point on the model in terms of numerous performance criteria. The remaining data points are then reweighted judiciously and ideally using a limited optimization to compensate for the detrimental impact of eliminating marked data.
By linearly patching the original model via reweighting while removing unique properties of marked data points, PUMA can preserve model performance. Researchers compared PUMA to previous data removal algorithms in the studies, demonstrating that PUMA can successfully trick a membership attack while also resisting performance reduction.
Conclusion
Researchers at Borealis AI have published PUMA, a revolutionary data removal approach that removes distinctive characteristics of marked training data points from a trained ML model while preserving the model’s performance against a set of performance criteria. PUMA has a substantial benefit over other approaches that require access to the model training process because it does not limit how the model is developed. Researchers discovered that PUMA outperforms baseline techniques in a variety of ways, including efficacy, efficiency, and performance preservation abilities, in a variety of studies.
Credit: Source link
Comments are closed.