Researchers at Stanford University Propose FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
In applications such as image classification and natural language processing, transformer models have emerged as the most often utilized architecture. Transformers have expanded in size and depth, but providing them with more context remains challenging due to the self-attention module’s time and memory complexity being quadratic in sequence length. A key question is whether improving attention speed and memory efficiency will aid Transformer models in overcoming their runtime and memory challenges for extended sequences.
Many approximate attention algorithms have attempted to lessen attention’s compute and memory demands. These methods include sparse approximation, low-rank approximation, and combinations of the two. Despite the fact that these strategies reduce compute requirements to linear or near-linear in sequence length, several of them do not show speedup when compared to standard attention and have yet to find widespread usage. One of the key reasons is that they are focused on FLOP reduction and tend to overlook memory access overheads.
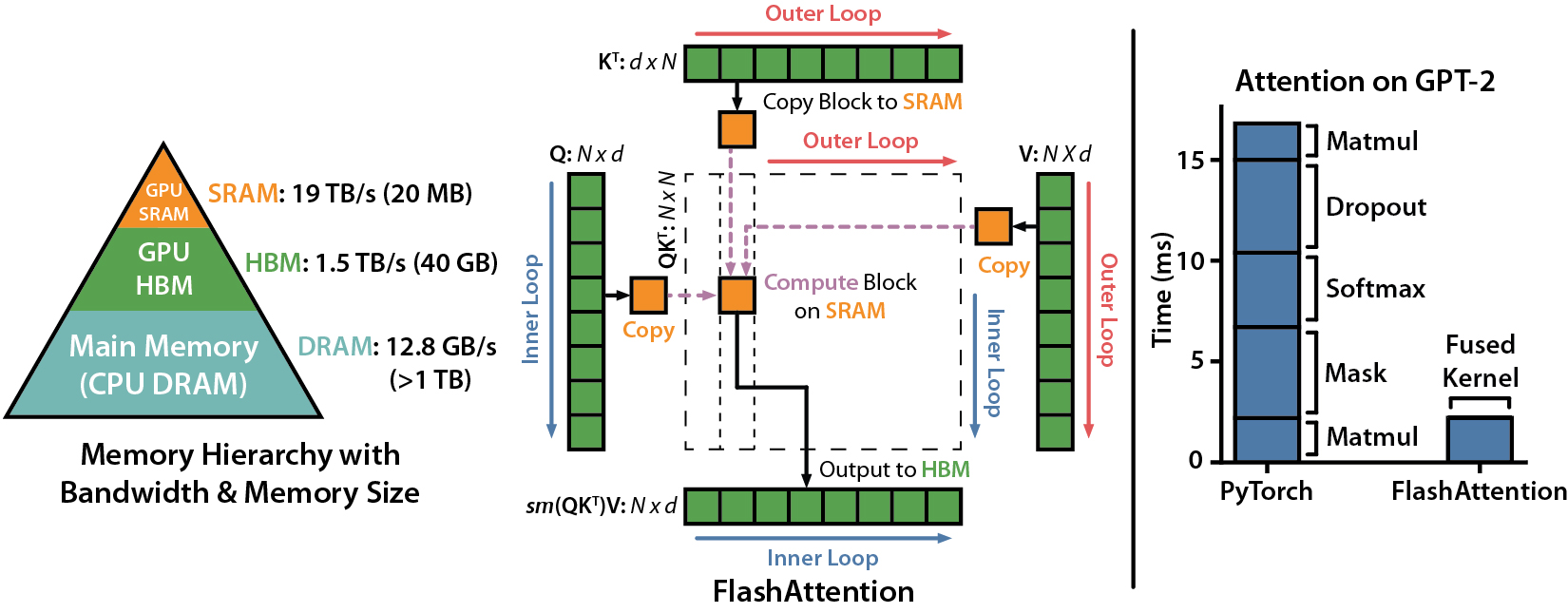
In a recent publication, Stanford University researchers suggested that making attention algorithms IO-aware—that is, carefully accounting for reads and writes to different levels of fast and slow memory—was a missing fundamental. On contemporary GPUs, computation speed has surpassed memory speed, and memory accesses are the bottleneck in most Transformers operations.
Please Don't Forget To Join Our ML Subreddit
IO-aware algorithms have proved crucial for memory-bound processes like database joins, image processing, numerical linear algebra, and more, where reading and writing data can account for a considerable amount of the runtime. Common Python deep learning interfaces, such as PyTorch and Tensorflow, do not, however, offer fine-grained memory access control.

FlashAttention is a novel attention method introduced by the researchers that compute accurate attention with considerably fewer memory accesses. The key goal was to keep the attention matrix from being read and written to and from high bandwidth memory (HBM). This necessitates computing the softmax reduction without access to the entire input and not storing the backward pass’s big intermediate attention matrix.
To solve these issues, the researchers used two well-known approaches. They rebuilt the attention computation to split the input into blocks and make multiple runs over each block, executing the softmax reduction progressively. The softmax normalization factor from the forward pass was also saved, allowing researchers to swiftly recompute attention on-chip in the backward pass, which was faster than the traditional method.
The researchers demonstrated that FlashAttention could be used to realize the potential of approximate attention algorithms by overcoming memory access overhead constraints. Researchers used block-sparse FlashAttention, a sparse attention algorithm that is 2-4 times faster than FlashAttention, as a proof of concept. Researchers demonstrated that block-sparse FlashAttention has better IO complexity than FlashAttention by a factor proportionate to the sparsity ratio.
Conclusion
FlashAttention is an IO-aware precise attention technique developed by Stanford University that leverages tiling to optimize memory reads/writes between GPU high bandwidth memory (HBM) and GPU on-chip SRAM. The researchers looked into FlashAttention’s IO complexity and discovered that it required fewer HBM accesses than normal attention and is best for a variety of SRAM sizes. By a large amount, FlashAttention trained Transformers faster than existing SOTA baselines. The IO-aware technique, according to the researchers, can go beyond attention. Transformers’ most memory-intensive computation is attention, but every layer in a deep network interacts with GPU HBM. The team expects that their effort will motivate other modules to build IO-aware implementations.
This Article is written as a summay by Marktechpost Staff based on the Research Paper 'FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness'. All Credit For This Research Goes To The Researchers of This Project. Check out the paper and github. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.