Salesforce AI Research Propose ‘ALPRO’: A New Video-And-Language Representation Learning (Pre-Training) Framework
This Article is written as a summay by Marktechpost Staff based on the Research Paper 'Align and Prompt: Video-and-Language Pre-training with Entity Prompts'. All Credit For This Research Goes To The Researchers of This Project. Check out the paper and github. Please Don't Forget To Join Our ML Subreddit
Consider how dynamic and diverse human contact is in the actual world. There appears to be no doubt that everyone interacts verbally within a busy world where video and language play vital interconnected roles on an ongoing basis. Examples include the football commentary a person enjoyed with friends over beers, the Jeopardy questions about The Matrix, and the untold recipes presented on the Hell’s Kitchen TV show.
In other words, video and linguistic content have become omnipresent in the Digital Age; they are all around us, continually, and 24 hours a day. And people appear to have little difficulty absorbing this torrent of video and text content.
Specifically, given the pervasiveness of video and language in the actual world, a fundamental scientific question arises: how artificial intelligence systems are designed that can simultaneously interpret video material and human language?
Numerous practical applications necessitate that the AI model simultaneously comprehends both modalities. Hence it is crucial to develop such a model. One example is content-based video search, which permits the search of many internet videos even in the absence of textual information. Another use is video categorization and recommendation, where the model can categorize videos by analyzing both video content and written descriptions. This will facilitate personalized video search and recommendation.
Vision-Language Pre-training (VLP) Techniques
Vision-language or video-and-language pre-training (VLP) techniques have recently emerged as an effective method for addressing this AI difficulty.
Using VLP approaches, neural networks are initially pre-trained on many web-based video-text pairs. Although some of these web data may be noisy, neural networks can acquire effective representations for downstream applications.
After pre-training, the parameters of the neural networks are employed as the initialization for fine-tuning.
Limitations and The Opportunity
Despite encouraging improvements, existing VLP models are limited in various ways, including: First, the video and text embeddings are not appropriately aligned. The cross-modal alignment can be modeled in multiple ways in the available research. Some work, for instance, maximizes the similarity between unimodal embeddings from the same video-text pair by taking the dot-product between them. The other work group passes the unimodal embeddings directly to the cross-modal encoder hoping that the cross-modal encoder will automatically capture the alignment relation. Nevertheless, since separate encoder networks produce these unimodal embeddings of videos and text, their embeddings lie in distinct feature spaces. As a result, neither approach is efficient at modeling cross-modal alignment.
Absence of fine-grained video data: Second, most visually-based pre-training assignments do not explicitly model fine-grained regional visual data. However, this information is essential for comprehending the video content. Some previous efforts (such as ActBERT) use object detectors to create pseudo-labels as supervision. Specifically, they apply Faster-RCNN to their video frames to generate object labels. Then, they oversee the pre-training models with these labels. The MSCOCO object detection dataset, for instance, contains fewer than a hundred distinct object classifications. This severely restricts the VLP model’s ability to learn the vast array of object and entity notions. In short, VLP models are plagued by imprecise detections and a limited number of object classes.
ALPRO (ALign & PROmpt)
ALign and PROmpt (ALPRO), a new video-and-language representation learning (pre-training) approach, has been proposed to address prior work limitations.
ALPRO follows the “pre-training-then-fine-tuning” paradigm utilized in the VLP techniques described previously but overcomes their drawbacks. The approach runs on poorly sampled video frames and achieves more efficient cross-modal alignment without explicit object detectors.
The ultimate objective of the novel strategy is to enhance the performance of subsequent tasks, such as video-text retrieval and video question answering (video QA). As proposed in ALPRO, enhanced pre-training technique results in enhanced video-language representations, contributing to enhanced performance on subsequent tasks.
The resulting pre-trained model in ALPRO achieves state-of-the-art performance across four public datasets for two classic tasks: video-text retrieval and video quality assurance. The strategy exceeds past work by a significant margin and is significantly more label-efficient than rival methods.
Method
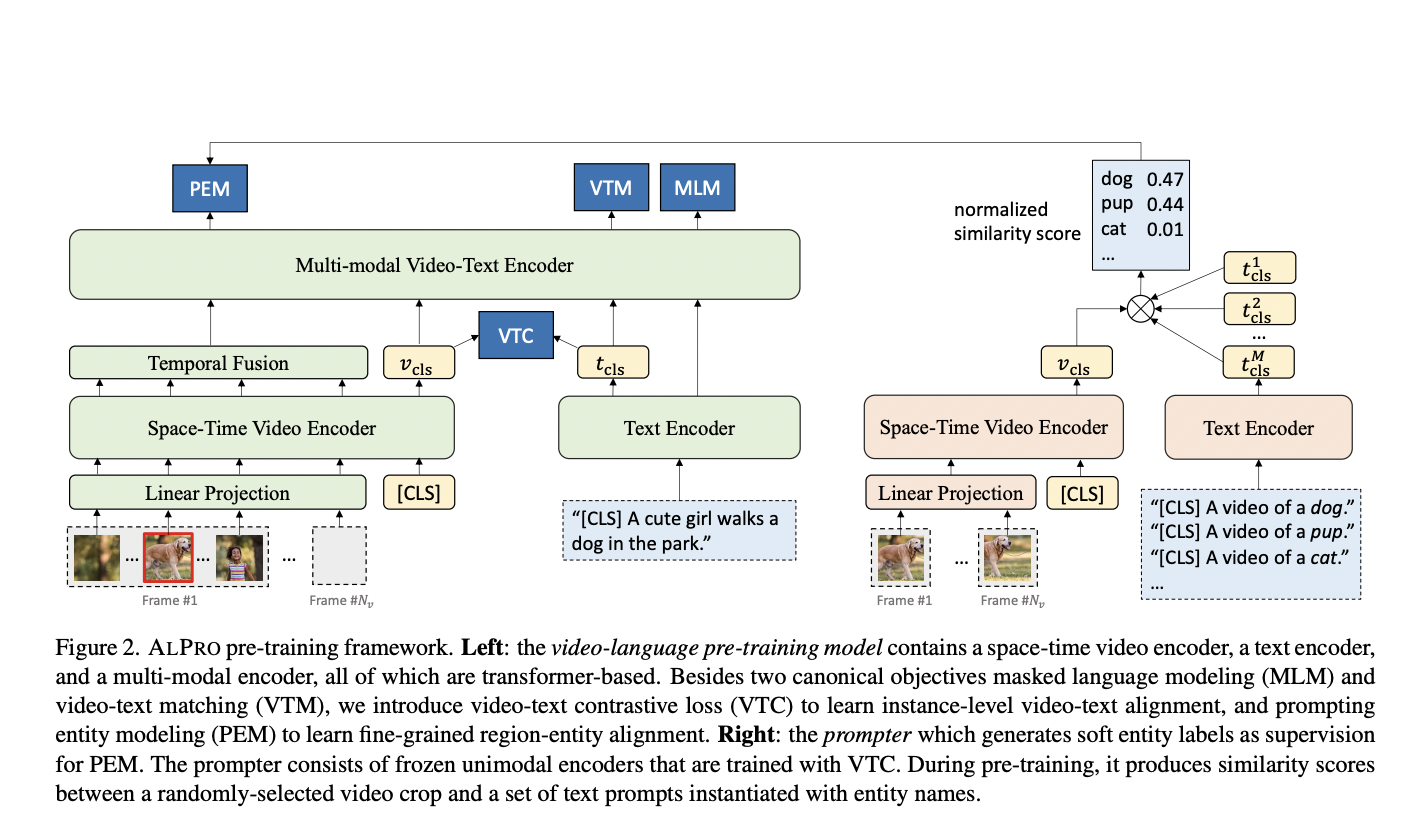
The unique ALPRO approach consists of two primary modules: a vision-language pre-training model and a prompter (see image above). The prompter creates soft entity labels for the supervision of the video-language model’s pre-training. Each module has its video encoder (TimeSformer) and text encoder (first six layers of BERT) for extracting features from video and text inputs. The pre-training model incorporates an additional multimodal encoder (the last six layers of BERT) to precisely capture the interaction between the two modalities.

Pre-Training Task 1: Contrastive Video-Text Object to Cross-Modal Alignment
- Before transferring features from unimodal encoders to the multimodal encoder, a video-text contrastive (VTC) has been applied for loss to align the features. This is accomplished by encouraging the embeddings of videos and text from positive pairs to be more comparable to negative ones. Before modeling their interactions, this ensures that the cross-encoder receives better matched unimodal embeddings.
Pre-training Task 2: Initiating Entity Modeling (PEM) to Capture Precise Video Data
- PEM is a new visually-grounded pre-training assignment that enhances the models’ ability to capture regional and local data. PEM relies precisely on a prompter module that provides soft pseudo-labels for up to a thousand distinct entity categories for random video cropping. Given the pseudo-label as the target, the pre-training model is then asked to predict the entity categories.
- In order to construct the pseudo-labels, the prompter compares the selected video crops to a list of so-called “entity prompts.” “A video of ENTITY” is an example of an entity prompt, where ENTITY is a noun that frequently appears in the pre-training corpus. Thus, more entity categories are extended by adding more entity prompts.

Comparison
As illustrated in the tables below, ALPRO achieves state-of-the-art performance on four standard video-language downstream datasets for the video-text retrieval and video QA tasks.
ALPRO outperforms the previous best retrieval model FiT on the widely used video-text retrieval dataset MSRVTT.
On video quality assurance, ALPRO gets equivalent results to VQA-T using QA-specific domain pre-training pairs.
ALPRO is far more label-efficient than ALPRO achieves its higher performance with only 5-10% of the pre-training data required by earlier methods.


Ethical Considerations
- The pre-training video-text corpus is compiled from the web to reduce exposure to inappropriate information. This content is typically generated without sufficient control by people. Consequently, ALPRO may be exposed to unsuitable video content or dangerous literature. It is also desired to pre-train and fine-tune ALPRO using production-specific multimodal data to relieve the issue.
- Similar to the primary concern, further analysis and training should be undertaken before deploying the technology. Since the pre-training video-text corpus was acquired from the internet, it is also susceptible to data bias. This bias may exist in object detection, text encoders, or video encoders.
- Due to meticulous optimization of the model architecture and data processing pipeline, training ALPRO requires a moderate amount of computational resources. The total cost of training is approximately several hundred A100 GPU hours. Pre-trained models are provided to prevent end-users from repeating pre-training efforts to promote eco-friendly AI systems.
- Privacy concerns: Pre-trained video-language data may contain identity-sensitive data, such as fingerprints. Alternative pre-training sources without human identities may be examined to address this issue (see, for instance, the work on self-supervised pre-training without humans [2]). Additionally, pre-processing the pre-training corpus may employ anonymity measures to avoid identifying leaks.
Conclusion
ALPRO (ALign and PROmpt) is a novel video-and-language pre-training system that provides a generic yet effective way of learning video-text representations. ALPRO adheres to the “pre-training-then-fine-tuning” paradigm utilized by other VLP systems but overcomes their limitations.
ALPRO achieves state-of-the-art performance on two classic tasks, video-text retrieval, and quality assessment, across four public datasets while being significantly more label-efficient than competing approaches.
Developing an AI model that can simultaneously reason about video and language is essential, as many practical applications require the model to comprehend both modalities. One example is content-based video search, which permits the search of many internet videos even in the absence of textual information. Another use is video categorization and recommendation, where the model can categorize videos by analyzing both video content and written descriptions. This will facilitate personalized video search and recommendation.
Credit: Source link
Comments are closed.