Amazon AI Researchers Propose A New Model, Called RescoreBERT, That Trains A BERT Rescoring Model With Discriminative Objective Functions And Improves ASR Rescoring
This Article is written as a summay by Marktechpost Staff based on the Research Paper 'RESCOREBERT: DISCRIMINATIVE SPEECH RECOGNITION RESCORING WITH BERT'. All Credit For This Research Goes To The Researchers of This Project. Check out the paper and blog. Please Don't Forget To Join Our ML Subreddit
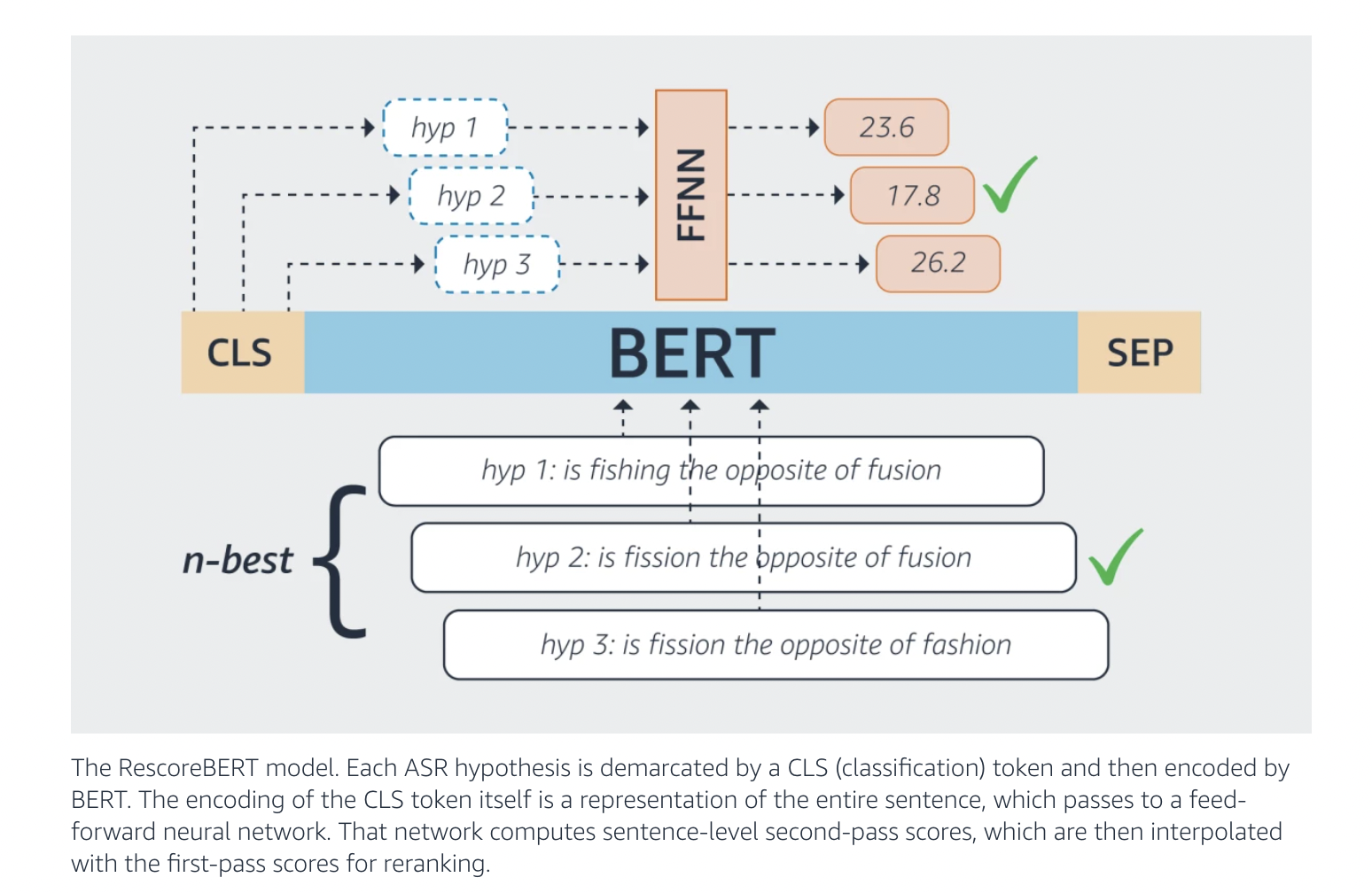
Automatic Speech Recognition (ASR) is an interdisciplinary subfield of computer science and computational linguistics that allows academics to create approaches for speech recognition and translation to text to improve searchability. Alexa, Siri, and Bixby are just a few of the many examples of ASR models in action. Because the amount of training data available for ASR models is restricted, the model may struggle to understand uncommon words and phrases. As a result, the hypotheses of the ASR model are frequently passed on to a language model, which represents the probabilities of sequences of words trained on considerably bigger textual data. To boost ASR accuracy, the language model reranks the hypotheses. Transformer-based bidirectional encoder representations are a transformer-based paradigm widely used in NLP. BERT can be utilized as a rescoring model by masking each input token and determining its log-likelihood from the remainder of the input. The results are then added together to generate a total score known as PLL (pseudo-log-likelihood). However, because this computation is quite time-consuming, it is not practicable for real-time ASR. Most ASR models employ a more efficient long-short-term memory (LSTM) language model for rescoring.
RescoreBERT is a novel model developed by Amazon Research that uses BERT’s power for second-pass rescoring. This year’s International Conference on Acoustics, Speech, and Signal Processing will feature their recently published work proposing this model and their experimental analyses (ICASSP). Compared to a typical LSTM-based rescoring model, RescoreBERT successfully lowers an ASR model’s error rate by 13%. Furthermore, the model remains efficient enough for commercial deployment due to the combined efforts of knowledge distillation and discriminative training. RescoreBERT was also deployed on the Alexa Teacher Model, a massive, pretrained, multilingual model with billions of parameters that encode language and primary patterns of Alexa interactions. The RescoreBERT model’s key component is a technique called rescoring. The second-pass language model trained from scratch on a small quantity of data can prioritize and accurately rerank the hypotheses of rare words thanks to the rescoring technique. Amazon’s prior work has been integrated to lower the computational expense of computing PLL scores. This is accomplished by feeding the output of the BERT model through a neural network trained to mimic the PLL scores awarded by a more significant “teacher” model. Because the distilled model is trained to match the teacher’s predictions of masked inputs, this process is known as MLM (masked language model) distillation. The distilled model’s output is interpolated with the original score to obtain a final score. This method minimizes latency by condensing PLL scores from a big BERT model to a much smaller BERT model.

The rescoring model cannot provide a lower score to the correct hypothesis as the first- and second-pass scores are linearly interpolated. It is also necessary to ensure that the correct hypothesis’ interpolated score is the lowest of all hypotheses. As a result, the researchers decided that taking first-pass scores into account when training the second-pass rescoring model would be helpful. On the other hand, the MLM distillation tries to distill the PLL scores and hence ignores the first-pass results. After MLM distillation, discriminative training accounts for the first-pass scores. RescoreBERT was trained to minimize ASR errors by using the linearly interpolated score between the first-pass and second-pass scores to rerank the hypotheses. Previously, the MWER (minimal word error rate) loss function was employed to minimize the expected number of word mistakes predicted using ASR hypothesis scores. The researchers developed a new loss function called MWED (matching word error distribution). The distribution of hypothesis scores is matched to the distribution of word errors for individual hypotheses using this loss function. It has been shown that MWED is a solid alternative to the normal MWER in improving the model’s English performance, but it cannot produce equivalent results in Japanese. The benefits of discriminative training are demonstrated by showing that RescoreBERT trained with a discriminative aim can improve WER by 7% – 12%, whereas BERT trained with MLM distillation can increase it by only 3% – 6%.
Credit: Source link
Comments are closed.