New AI Research From Deepmind Explains How Few-Shot Learning (FSL) Emerges Only When The Training Data Is Distributed In Particular Ways That Are Also Observed In Natural Domains Like Language
This Article is written as a summay by Marktechpost Staff based on the Research Paper 'Data Distributional Properties Drive Emergent In-Context Learning in Transformers'. All Credit For This Research Goes To The Researchers of This Project. Check out the paper. Please Don't Forget To Join Our ML Subreddit
The capacity of large transformer-based language models to do few-shot learning is intriguing. These models can be generalized from a few samples of a new topic that they haven’t been trained on before. Previous research in the field of meta-learning has shown how neural networks can execute few-shot learning from a few examples without the requirement for weight updates – this is also known as in-context learning because the output is conditioned on the context.
To do this, the Deepmind researchers created a training program that specifically encourages in-context learning, a technique known as meta-training. The capacity for in-context learning in transformer language models, on the other hand, is emergent. Few-shot learning isn’t directly addressed in the model’s transformer architecture or learning aim.
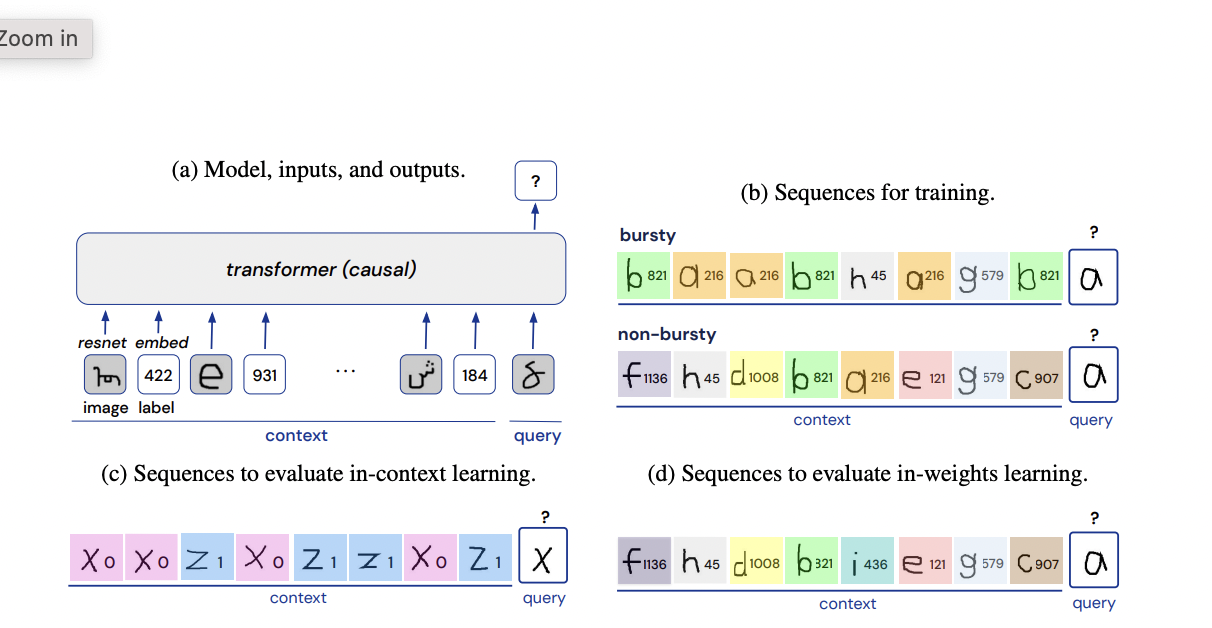
The discovery that many natural data sources, including natural language, deviate from normally supervised datasets due to a few significant traits inspired this idea. Natural data, for example, is ‘bursty’ in terms of time. That is, rather than tending to appear in clusters, a given entity (word, person, item, etc.) may have a distribution that is not uniform across time.
Natural data frequently displays a highly skewed marginal distribution across entities, with a long tail of uncommon items following a power-law distribution. Finally, in natural data, the meaning of entities is frequently dynamic rather than fixed. That is to say, a single entity can have several interpretations, and multiple entities can map to the same interpretation in a context-dependent manner.
Few-shot meta-training, on the other hand, entails training a model directly on specifically designed data sequences in which item classes only recur and item-label mappings are only stable within episodes — not across episodes. Naturalistic data, such as language or first-person experience, combines the features of both forms of data. Items recur, and the relationship between an entity and its interpretation is fixed to some extent, just as it is in supervised training.
At the same time, natural data has a skewed and long-tailed distribution, which indicates that some items frequently recur while others recur seldom. Importantly, these unusual things are frequently bursty, which means they’re more likely to appear numerous times within a particular context window, similar to a sequence of meta-training data.
DeepMind researchers experimented with the distributional features of the training data and examined the effects on in-context few-shot learning in a recent publication. Experiments were carried out on data sequences taken from a conventional image-based few-shot dataset. The team supplied each model with input sequences of photos and labels during training.
Recurrent models like LSTMs and RNNs, unlike transformers, were unable to learn in context when trained on the same data distribution. It’s worth noting, though, that transformer models trained on the incorrect data distributions still didn’t show in-context learning. As a result, attention alone is insufficient — architecture and data are both essential for the formation of in-context learning.
In-context learning develops in a transformer model only when it is trained on data with both burstiness and a large enough number of rarely occurring classes, according to the findings. Researchers also looked at two other types of dynamic item interpretation seen in real-world data: having multiple labels per item and within-class variance. The researchers discovered that both treatments on the training data skewed the model toward in-context learning.
Conclusion
The researchers believe their findings could lead to more research into the significance of non-uniformity in human cognitive development. Because children learn statistical qualities of the language quickly, these distributional features can assist infants in developing the ability to learn quickly. This knowledge could also aid researchers in designing and collecting datasets for in-context learning in domains other than language, which is still a work in progress.
Credit: Source link
Comments are closed.