CMU Researchers Propose Deep Attentive VAE: The First Attention-Driven Framework For Variational Inference In Deep Probabilistic Models
This Article is written as a summay by Marktechpost Staff based on the Research Paper 'DEEP ATTENTIVE VARIATIONAL INFERENCE'. All Credit For This Research Goes To The Researchers of This Project. Check out the paper, github and blog post. Please Don't Forget To Join Our ML Subreddit
Data is an essential element in Machine Learning, and understanding how it is distributed is crucial. Unsupervised approaches enable generative models to learn about any data distribution. They may produce unique data samples like fake faces, graphic artwork, and scenic panoramas. They are used in conjunction with other models to supplement the observed data set with unobserved information to define better the technique that creates the data of interest.
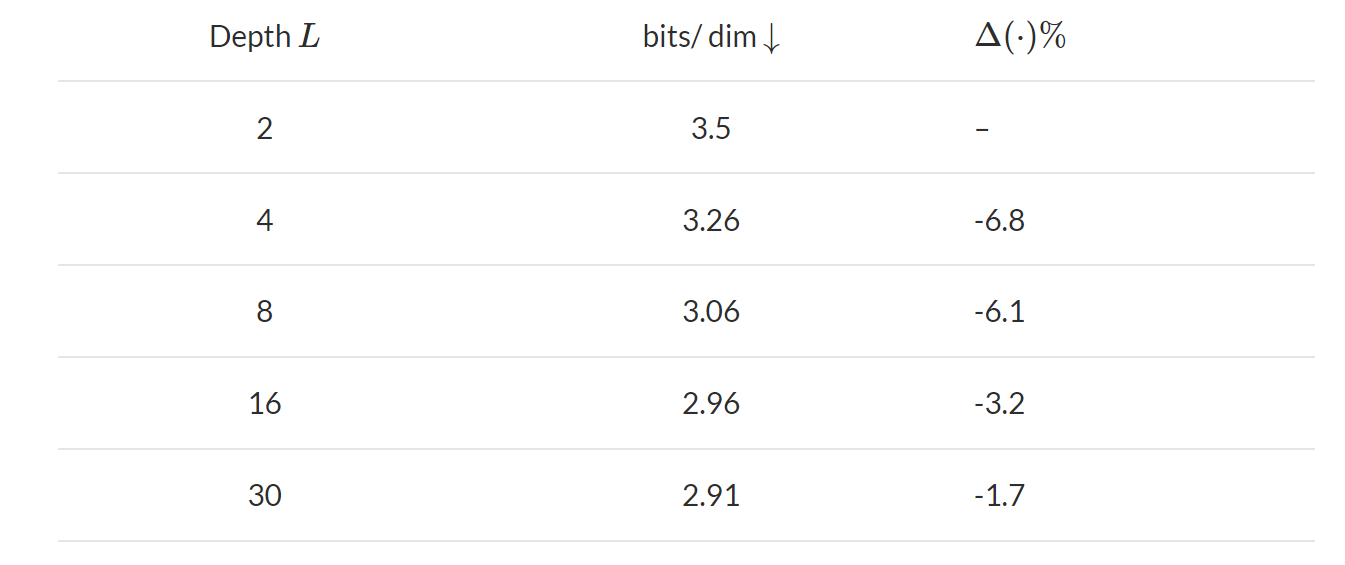
Despite promising developments, deep generative modeling is expensive. Recent models focus on increasing architectural depth to improve performance. However, as our analysis shows, the predictive benefits decrease as depth increases. As researchers shift toward Green AI, just expanding layers is no longer a feasible strategy.
Recent methods depend on increasing depth to enhance performance and produce results equivalent to fully generative, auto-regressive models while allowing for quick sampling via a single network assessment. However, as depth grows, the predictive improvements decline. After a certain point, they are even doubling the number of layers, resulting in a modest increase in the marginal likelihood. The explanation for this might be that the influence of latent variables from previous levels lessens as the context feature crosses the hierarchy and is updated with the most recent information from the following layers. Many early units collapse to their preceding counterparts and hence no longer be relevant to inference. The plausible reason is the local connectivity between the layers in the hierarchy.
Deep VAEs suffer from diminishing returns
The problem with such deep convolutional architectures is handling large 3D tensors. To solve this problem is by looking at the long sequence of tensors as couplings.
There are two types of couplings:
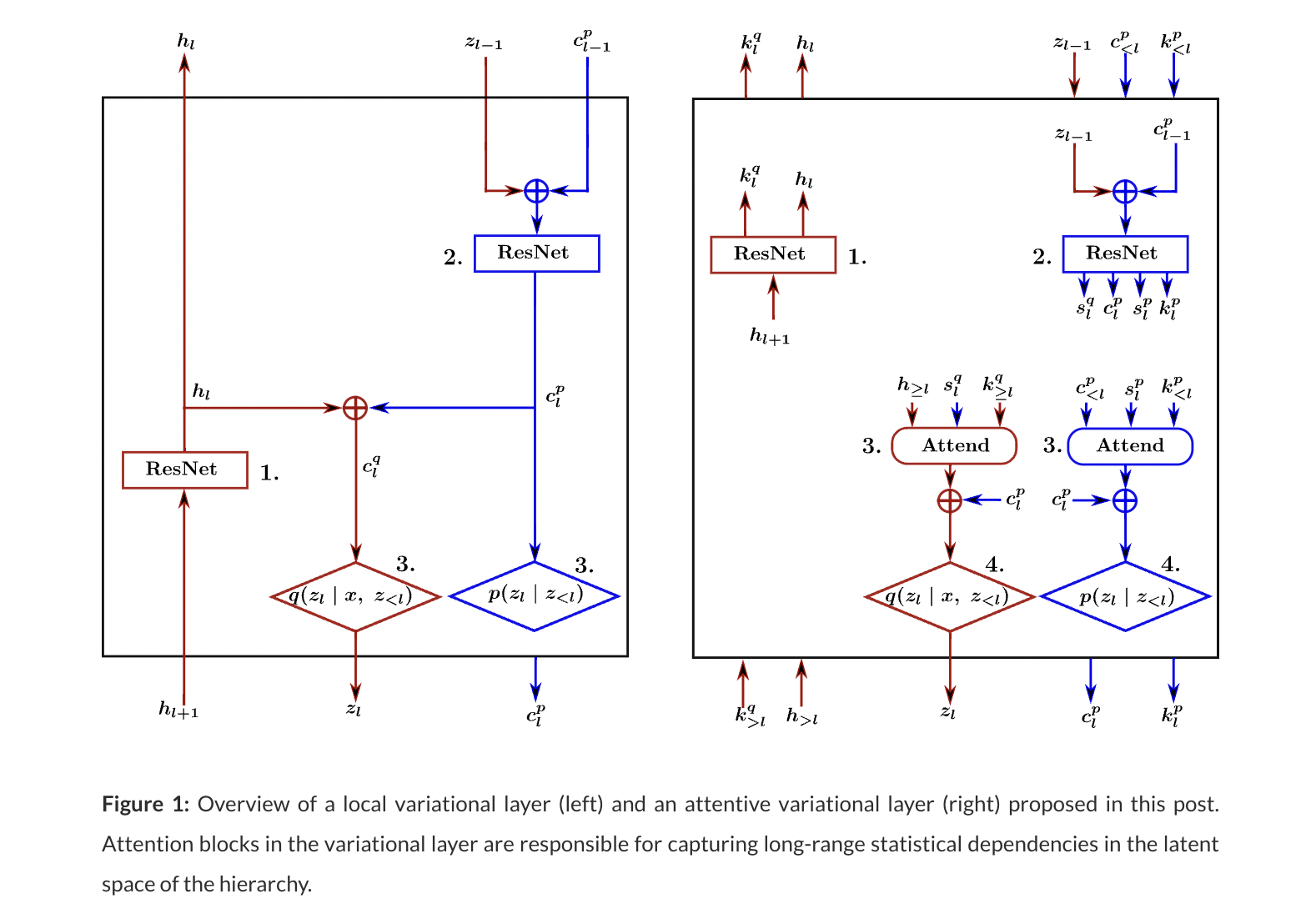
- Inter-Layer couplings: Depth-wise Attention
The network adopts a depth-wise attention technique to discover inter-layer relationships. To the levels of the variational hierarchy, two depth-wise attention blocks for constructing the context of the prior and posterior distributions are added.
- Intra-Layer couplings: Non-local blocks
Interlacing non-local blocks can exploit intra-layer dependencies with convolutions in the architecture’s ResNet blocks.
Attentive VAEs on various publicly available benchmark datasets of binary and natural pictures. Table 2 displays the performance and training time of cutting-edge, deep VAEs on CIFAR-10. CIFAR-10 is a collection of 3232 natural pictures. When compared to other deep VAEs, attentive VAEs attain state-of-the-art likelihoods. More crucially, they achieve it with many fewer layers. Fewer layers result in less training and sampling time. The rationale for this advancement is that attention-driven, long-distance connections between layers result in more significant usage of latent space.

The expressivity of existing deep probabilistic models can be enhanced. It can be achieved by selecting meaningful statistical connections between potentially distant latent variables. By describing both adjacent and distant interactions in the latent space, attention processes may generate more expressive variational distributions in deep probabilistic models. By eliminating the requirement for deep hierarchies, attentive inference minimizes the computing footprint.
Credit: Source link
Comments are closed.