Snap and Northeastern University Researchers Propose EfficientFormer: A Vision Transformer That Runs As Fast As MobileNet While Maintaining High Performance
This Article is written as a summay by Marktechpost Staff based on the research paper 'EfficientFormer: Vision Transformers at MobileNet Speed'. All Credit For This Research Goes To The Researchers of This Project. Check out the paper, github and ref blog. Please Don't Forget To Join Our ML Subreddit
In natural language processing, the Transformer is a unique design that seeks to solve sequence-to-sequence tasks while also resolving long-range dependencies. Vision Transformers (ViT) have demonstrated excellent results on computer vision benchmarks in recent years. On the other hand, they are usually times slower than lightweight convolutional networks because of the large number of parameters and model architecture, such as the attention mechanism. As a result, deploying ViT for real-time applications is difficult, especially on hardware with limited resources, such as mobile devices.
Many studies have worked on relieving the latency bottleneck of transformers. For example, some works have tried to lower the computational cost by building new architectures or operations by replacing linear layers with convolutional layers (CONV), merging self-attention with MobileNet blocks, or introducing sparse attention. In contrast, others use network searching algorithms or pruning. Existing work has improved the computation-performance trade-off. However, they don’t demonstrate if these sophisticated vision transformers will be able to run at MobileNet speeds and become the standard for edge applications.
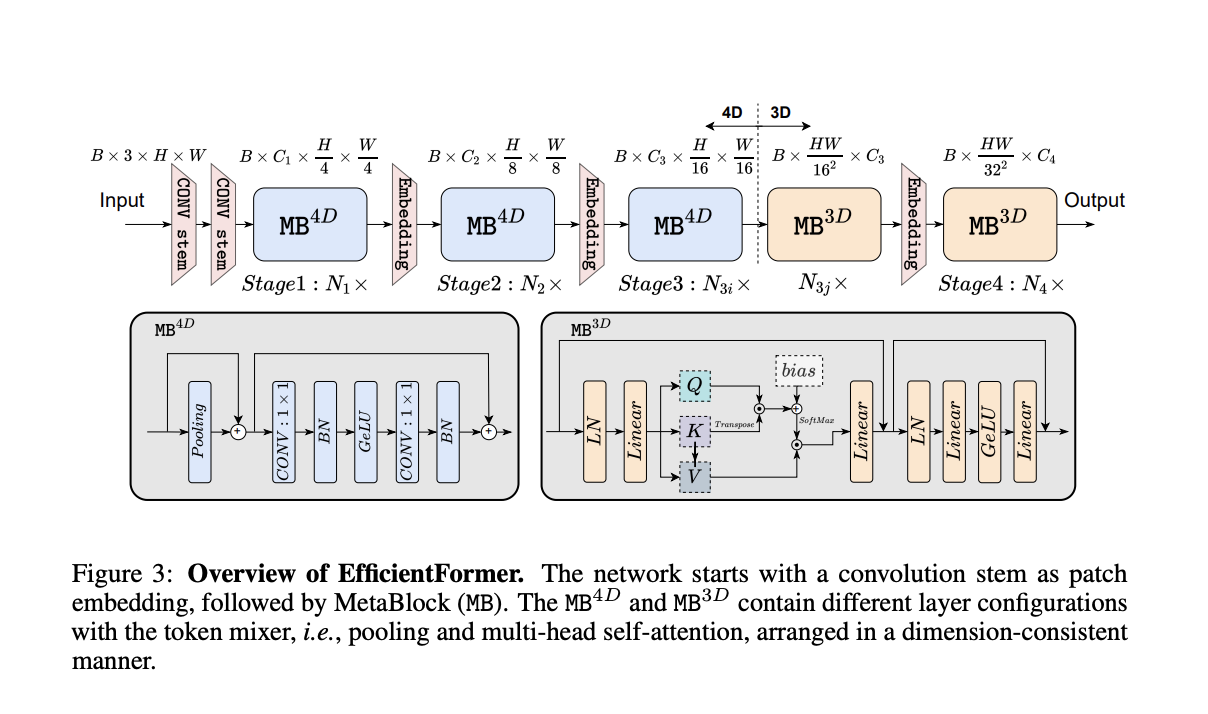
Snap Inc. and Northeastern University collaborated on a new study that answers this fundamental question and suggests a new ViT paradigm. The researchers address the difficulties in their work “EfficientFormer: Vision Transformers at MobileNet,” which revisits the design ideas of ViT and its variants through latency analysis and identifies inefficient designs and operators in ViT.

Because the iPhone 12 is widely used, and the results are easily replicable, they employed it as the testbed and the freely available CoreML as the compiler. They offer a simple yet effective latency-driven slimming strategy to generate a new family of models, called EfficientFormers, starting with a supernet using the new design paradigm. Instead of MACs or the number of parameters, they focus on inference speed.
According to researchers, their fastest model, EfficientFormer-L1 achieves 79.2% top-1 accuracy on the ImageNet-1K classification task, with 6.4% lower latency and 7.4% higher top-1 accuracy than MobileNetV2 (averaged over 1 000 runs). The findings suggest that vision transformers can be adopted easily, irrespective of their latency. Their largest model, the EfficientFormer-L7, exceeds ViT-based hybrid designs with an accuracy of 83.3 percent and only 7.4 ms latency. Using EfficientFormer as the backbone of image detection and segmentation benchmarks, they report better results.
As a whole, their research reveals that ViTs are capable of achieving ultra-fast inference speeds and high performance simultaneously. The team hopes that their work will serve as a solid foundation for future work on the deployment of vision transformers.
Credit: Source link
Comments are closed.