Researchers From China Introduce Vision GNN (ViG): A Graph Neural Network For Computer Vision Systems
This Article is written as a summay by Marktechpost Staff based on the research paper 'Vision GNN: An Image is Worth Graph of Nodes'. All Credit For This Research Goes To The Researchers of This Project. Check out the paper, github. Please Don't Forget To Join Our ML Subreddit
Convolutional neural networks used to be the typical network architecture in modern computer vision systems. Transformers with attention mechanisms were recently presented for visual tasks, and they performed well. Convolutions and self-attention aren’t required for MLP-based (multi-layer perceptron) vision models to perform properly. As a result of these advancements, vision models are reaching new heights.
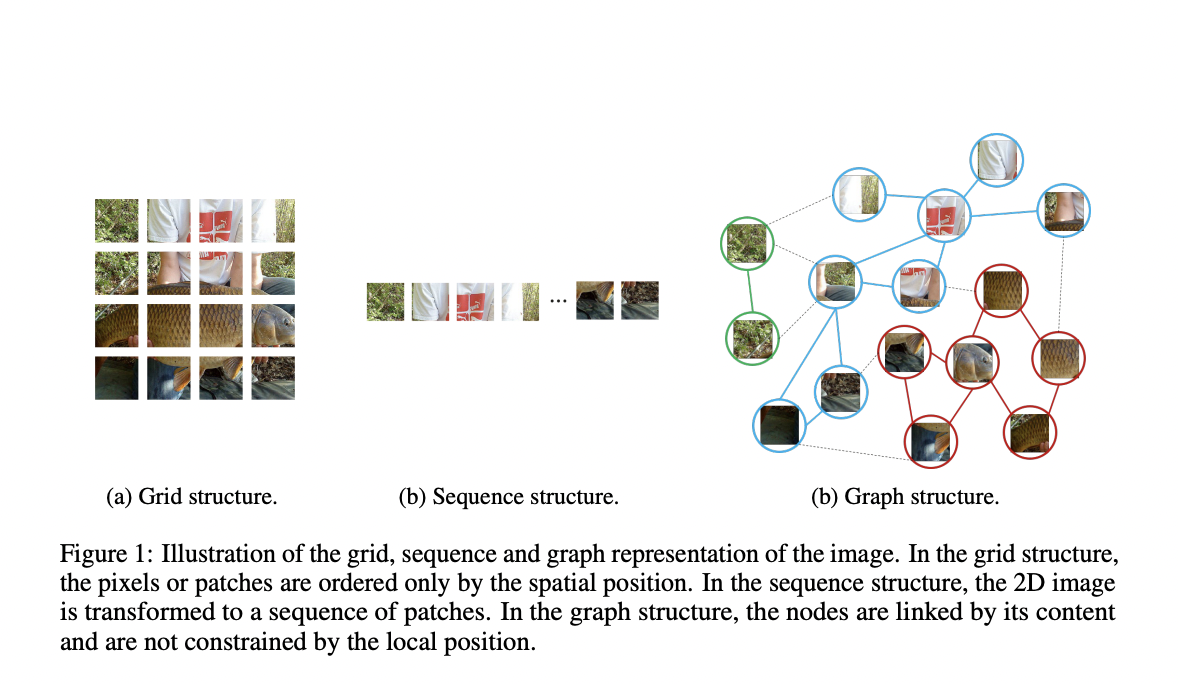
The input image is handled differently by different networks. In Euclidean space, image data is commonly represented as a regular grid of pixels. On the image, CNNs apply a sliding window and introduce shift-invariance and locality. The MLP vision transformer, which was released recently, treats the image as a series of patches.
Recognizing the items in an image is one of the most basic tasks of computer vision. The typically utilized grid or sequence structures in prior networks like ResNet and ViT are redundant and inflexible to process because the objects are usually not quadrate whose shape is irregular. An item can be thought of as a collection of parts, such as a human’s head, upper torso, arms, and legs. These sections are organically connected by joints, forming a graph structure. Furthermore, a graph is a generic data structure, with grids and sequences being special cases of graphs. Visual perception is more flexible and effective when an image is viewed as a graph.
Huawei researchers developed the vision graph neural network (ViG) for visual tasks based on the graph representation of pictures in a recent article. Rather than treating each pixel as a node, which would result in an excessive amount of nodes (>10K), the researchers separated the input image into patches and used each patch as a node. The researchers used the ViG model to convert and share information across all the nodes after generating the graph of image patches.

The GCN (graph convolutional network) module for graph information processing and the FFN (feed-forward network) module for node feature transformation are the two core cells of ViG. The ViG models were generated in both isotropic and pyramid ways using Grapher and FFN components.
The researchers ran a number of studies to demonstrate the ViG model’s efficiency on visual tasks such as image categorization and object detection. On the ImageNet classification task, Pyramid ViG outperformed the equivalent CNN(ResNet), MLP, and transformer models, achieving 82.1 percent top-1 accuracy. The team’s approach was the first to use graph neural networks to solve large-scale visual tasks successfully.
Conclusion
Huawei researchers attempted to examine encoding images as graph data and leveraging graph neural networks for visual tasks in a recent study. The image was separated into patches, which were then interpreted as nodes by the researchers. The researchers created vision GNN (ViG) networks with both isotropic and pyramid designs based on image graph representation and enhanced graph blocks. Extensive image recognition and object detection experiments show that the suggested ViG architecture is superior. The researchers anticipate that this ground-breaking work on vision GNN will serve as a foundation for general visual tasks.
Credit: Source link
Comments are closed.