Amazon AI Researchers Proposed ‘DQ-BART’: A Jointly Distilled And Quantized BART Model That Achieves 16.5x Model Footprint Compression Ratio
This Article is written as a summay by Marktechpost Staff based on the paper 'DQ-BART: Efficient Sequence-to-Sequence Model via Joint Distillation and Quantization'. All Credit For This Research Goes To The Researchers of This Project. Check out the paper and post. Please Don't Forget To Join Our ML Subreddit
Sequence-to-sequence (seq2seq) models that have already been trained, like BART and T5, have done very well in various natural language processing tasks, like text summarization, machine translation, answering questions, and extracting information. But these large-scale language models that have already been trained have hundreds of millions of parameters—work done at AWS AI Labs during an internship. Equal contribution trained a BART model with 400 million parameters, while T5 pushed the limit to 11 billion parameters.
The constant growth of model sizes means that many computing and memory resources are needed during inference. This makes deployment very hard, especially in real-time and resource-limited situations. This makes researchers want to make big models that have already been trained smaller and faster while keeping their strong performance. Quantization approaches have been getting a lot of attention lately because they reduce model footprints by using less bits for weight values without changing the carefully designed model architecture. Most previous work on quantizing transformers was done with BERT-based transformers. But there hasn’t been enough research on efficiently quantizing encoder-decoder transformers. It is possible to achieve 8-bit quantization for a seq2seq transformer without a significant drop in performance. Still, low-bit quantization was hard for this model (4-bit performance in Table 2 in their work) because quantization errors tend to pile up in seq2seq models. Also, their work didn’t try to quantify large-scale language models that had already been trained, nor could it be used for any NLP tasks other than machine translation. For BERT compression, much research has been done on model distillation, which moves knowledge from a large teacher model to a smaller student model.

Recent improvements to sequence-to-sequence pretrained language models like BART (bidirectional autoregressive Transformers) have significantly performed many NLP tasks. A typical BART model might have hundreds of millions of parameters. The success of these models, on the other hand, requires a lot of memory and processing power.
This can make it impossible to use BART on devices with limited resources, like cell phones or smart home appliances. Scientists from Amazon Web Services’ AI Labs presented a paper at ACL 2022 that solves this problem by using distillation and quantization to reduce the size of a BART model to less than 1/16th of its original size without much loss in performance.
A plan with two parts
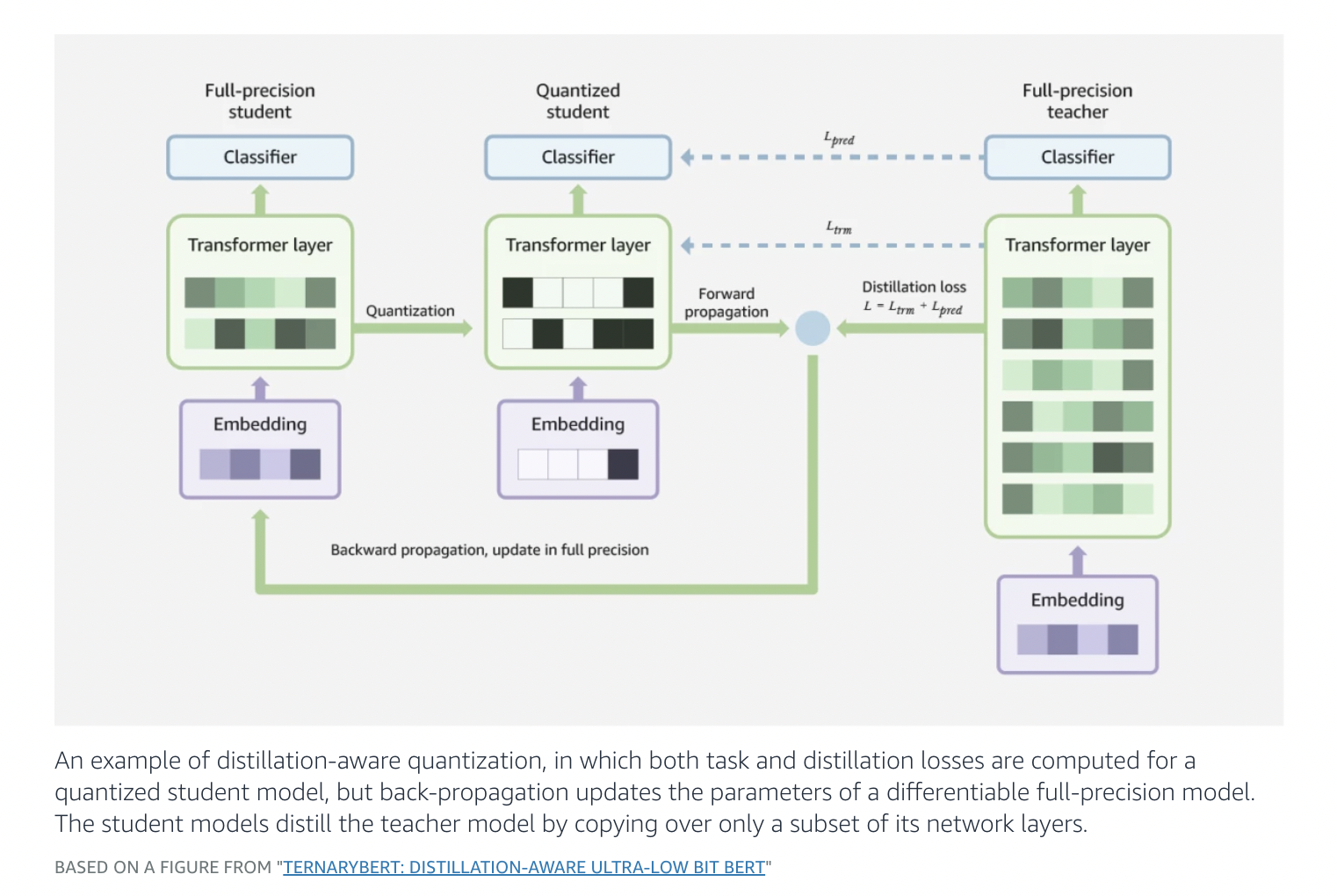
Quantization, which maps high-precision values to a limited menu of lower-precision values, and distillation, in which a smaller, more efficient student model is trained to imitate a larger, more powerful teacher model, are both common ways to reduce neural networks’ memory footprints.
The researchers start by fine-tuning a BART model, also called a “teacher model,” on a specific NLP task, like answering questions or summarizing text. The weights of particular layers of the trained teacher model are then copied to a student model. This is the process of distillation, which makes the model footprint smaller.
Distillation-aware quantization is the next step. The student model is quantized, which makes a low-precision model. The full-precision student model is also kept on hand because it’s needed for the next step.
The quantized student model then processes the dataset used to train the teacher model. Its outputs are evaluated using two metrics: the standard task-based loss, which measures how far the results differ from the ground truth, and a distillation loss, which measures the difference between the quantized-and-distilled student model and the teacher model.

Then, these losses are used to change the parameters of the full-precision student model, not the quantized one. This is because the standard algorithm for updating a neural network uses gradient descent, which needs model parameters that can change continuously. In a quantized model, the parameters have discrete values, so they can’t be changed.
Once the full-precision student model has been updated to minimize its error on the training set and its difference from the teacher model, it is quantized again to reduce the amount of memory it uses.
Experiments
The researchers tested how well their simplified and quantified BART model summarized text and answered long-form questions against three different benchmarks. They also looked into how distillation-aware quantization would work on a more complicated model like mBART, a multilingual model made to translate phrases between languages, such as English and Serbian.
Their first analysis found that combining distillation and quantization gave better compression than quantization alone. There was no performance decline for the long-form question task and just a slight performance decline for the summary test. They also found that the model can be shrunk to almost 1/28th of its original size. But at this compression rate, the model’s performance isn’t consistent; the right amount of compression should be figured out for each task.
For the mBART task, the team found that the distillation-aware approach was good at reducing the size of the model’s footprint when using eight-bit quantization. However, when the number of quantization bits was lowered to two, its performance started to drop more significantly. The researchers think this drop in performance was caused by errors in distillation and quantization that have built up over time. These errors may be more severe for the complex problem of machine translation.
Conclusion
In future work, the researchers want to learn more about the multilingual mBART model and test other compression methods, such as head pruning and sequence-level distillation. As the current study mainly was about memory footprints, they also want to look into the effects of latency.
Transformer-based, pre-trained seq2seq language models like BART have greatly improved state of the art in several NLP tasks. Yet, these large-scale models are hard to make when resources are limited. DQ-BART, a BART model that is both distilled and quantized, was used to solve this problem. Even though language generation tasks are complex, empirical results show that a 16.5x model footprint compression ratio was achieved with little drop in performance on three generative benchmarks. The trade-off between performance and efficiency for seq2seq models was shown with up to a 27.7x compression ratio. Also, distillation and quantization were looked for mBART on a machine translation task and pointed out the difficulty of combining low-bit quantization with distillation for deeper models on cross-lingual tasks. The method is the first to use quantization and distillation on language models that have already been trained. This is also the first work to try to distill and quantify seq2seq-trained models for language generation tasks.
Credit: Source link
Comments are closed.