Researchers Introduce VideoINR: A Model For Learning Video Implicit Neural Representation for Continuous Space-Time Super-Resolution

This Article is written as a summay by Marktechpost Staff based on the paper 'VideoINR: Learning Video Implicit Neural Representation for Continuous Space-Time Super-Resolution'. All Credit For This Research Goes To The Researchers of This Project. Check out the paper, github, and project. Please Don't Forget To Join Our ML Subreddit
Humans observe the visual world as continuous and streaming data. On the other hand, the recorded videos are stored with low spatial resolutions and frame rates. Recording and storing significant amounts of video data is expensive over long periods. Hence this situation requires current computer vision systems to process low-resolution and low-frame rate videos.
Many academics are investigating strategies to recover low-resolution video to high-resolution video in space and time, as it is critical to delivering videos in high-resolution and high-frame-rate formats for the best user experience.
By converting pixel information into learned features inside a neural network, machine-learning-based image synthesis systems such as autoencoders and Generative Adversarial Networks (GANs) can achieve better image compression efficiency than traditional pixel-based codecs.
Free-2 Min AI NewsletterJoin 500,000+ AI Folks
Given a low-resolution and low frame rate video as input, many strategies use Space-Time Video Super-Resolution (STVSR) based methodologies to simultaneously boost spatial resolution and frame rate. These systems are capable of converting video content into learned features and then displaying them at (fixed) resolutions. Upsampling and frame interpolation are also possible with STVR systems, allowing for improved detail and the output of videos at higher frame rates than when they were originally shot. Researchers are also working on techniques to do super-resolution in a single stage rather than two. However, these methods can only super-resolve to a set space and time scale ratio.
Researchers at Picsart AI Research (PAIR), USTC, UC San Diego, UIUC, UT Austin, and the University of Oregon propose a unique Video Implicit Neural Representation (VideoINR) as a continuous video representation. This enables simultaneous sampling and interpolating of video frames at any frame rate and spatial precision.
The recent development of implicit functions for 3D shape and image representations utilizing Local Implicit Image Functions (LIIF) and a ConvNet influenced their study. Pixel gradients across frames with low frame rates are difficult to compute, unlike photographs, where interpolation in space can rely on the gradients between pixels. To execute interpolation, the network must grasp the motion of the pixels and objects, which is difficult to model using either 2D or 3D convolutions.

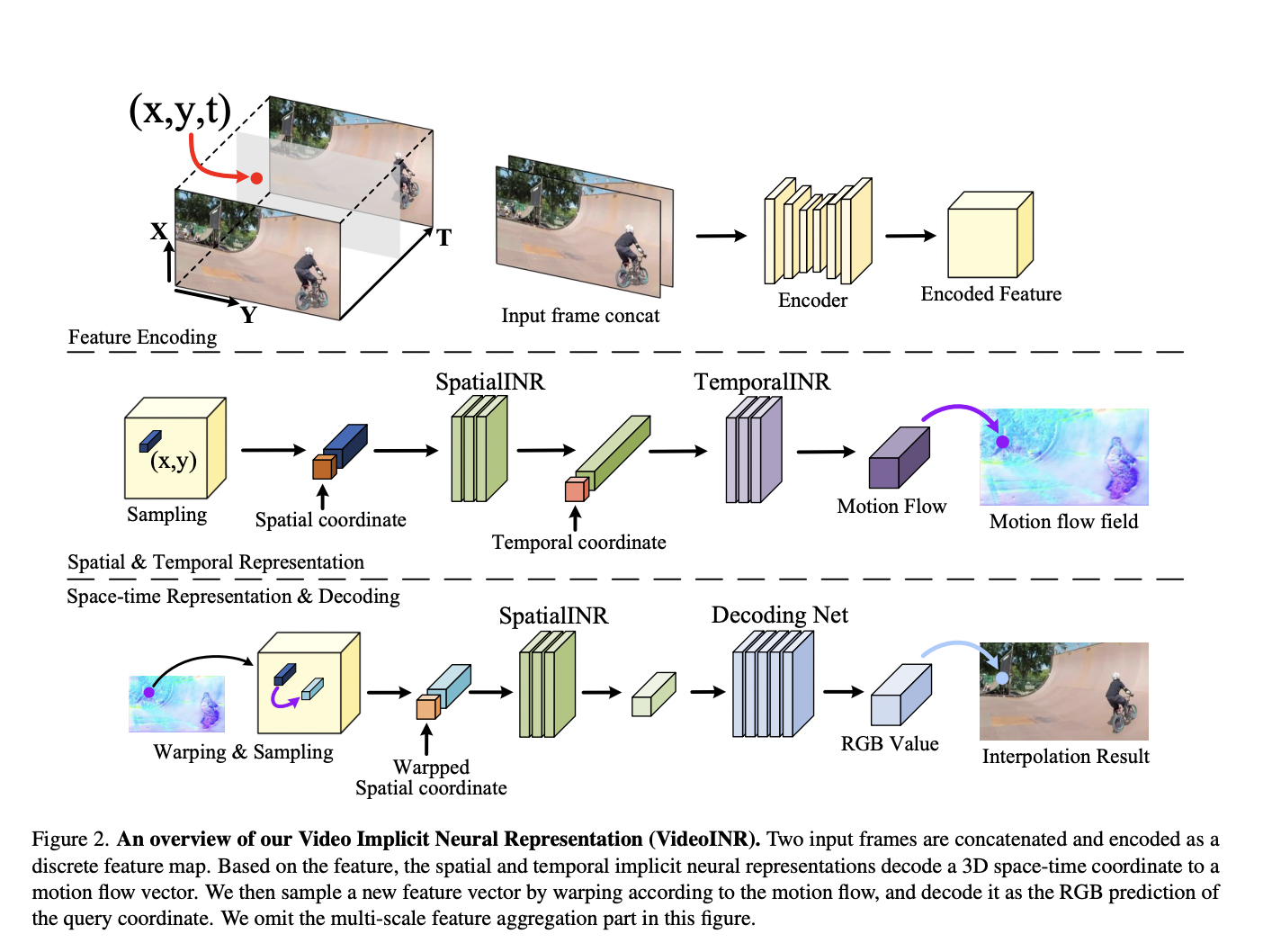
Two low-resolution image frames are concatenated and passed to an encoder in the STVSR job, which produces a feature map with spatial dimensions. Over the created feature map, VideoINR acts as a continuous video representation. It starts by defining a continuous spatial feature domain’s spatial implicit neural representation, from which a high-resolution picture feature is sampled according to all query coordinates.
Rather than employing convolutional procedures to accomplish temporal interpolation, temporal implicit neural representations are learned to output a motion flow field first, given the high-resolution feature and the sampling time as inputs. This flow field can decode the high-resolution feature and warp it to the target video frame. An encoder generates a feature map from the input frames, which VideoINR may then decode to any spatial resolution and frame rate. Since all the procedures are differentiable, the motion at the feature level can be taught end-to-end without any extra supervision besides the reconstruction error.
The researchers used their experiments’ datasets from Vid4, GoPro, and Adobe240. Their findings reveal that, in addition to extrapolating out-of-distribution frame rates and spatial resolutions, VideoINR can represent video in arbitrary space and time resolutions on the scales within the training distributions. Instead of decoding the entire video each time, the continuous learned function gives the flexibility to decode only a certain region and time scale as needed.
On in-distribution spatial and temporal scales, VideoINR performs competitively with state-of-the-art STVSR approaches and greatly outperforms other methods on out-of-distribution scales.
The researchers also discovered that VideoINR did not work well in some situations. In most of these scenarios, very big motions must be handled, which is still a challenge for video interpolation. The team intends to work on resolving this problem in future work.
Credit: Source link
Comments are closed.