Harvard Researchers Introduce A Novel ViT Architecture Called Hierarchical Image Pyramid Transformer (HIPT) That Can Scale Vision Transformers To Gigapixel Images Via Hierarchical Self-Supervised Learning
Tissue phenotyping is a basic challenge in computational pathology (CPATH), which tries to characterize objective, histopathologic aspects inside gigapixel whole-slide images (WSIs) for cancer diagnosis, prognosis, and response-to-treatment assessment in patients.
A gigapixel image is a digital recreation with an extremely high resolution created by merging numerous detailed photographs into a single item. It contains billions of pixels, far exceeding the capacity of a typical professional camera.
Unlike natural images, whole-slide imaging is a difficult computer vision domain with image resolutions as high as 150000 x 150000 pixels. Many methods use the three-stage, weakly supervised framework based on multiple instance learning (MIL), namely tissue patching at a single magnification objective (“zoom”), patch-level feature extraction to construct a sequence of embedding instances, and global pooling of instances to construct a slide-lev
Although this three-stage procedure achieves clinical-grade performance on many cancer subtyping and grading tasks, it has a few design flaws. Patching and feature extraction are usually limited to context regions of [256 x 256]. Despite their ability to detect fine-grained morphological features such as nuclear atypia or tumor presence, [256 x 256] windows have limited context in capturing coarser-grained features such as tumor invasion, tumor size, lymphocytic infiltrate, and the broader spatial organization of these phenotypes in the tissue microenvironment, depending on the cancer type.
Due to the high sequence lengths of WSIs, MIL requires only global pooling operators, unlike other image-based sequence modeling systems such as Vision Transformers (ViTs). As a result, Transformer attention cannot be used to learn long-range correlations between phenotypes like tumor-immune location, which is an important prognostic trait in survival prediction.
In a recent publication, Harvard researchers looked into the difficulty of constructing a Vision Transformer for slide-level representation learning in WSIs to address these issues. The researchers emphasized that while modeling WSIs, visual tokens would always be at a fixed scale for a particular magnification objective, in contrast to natural images that ViTs actively explore.
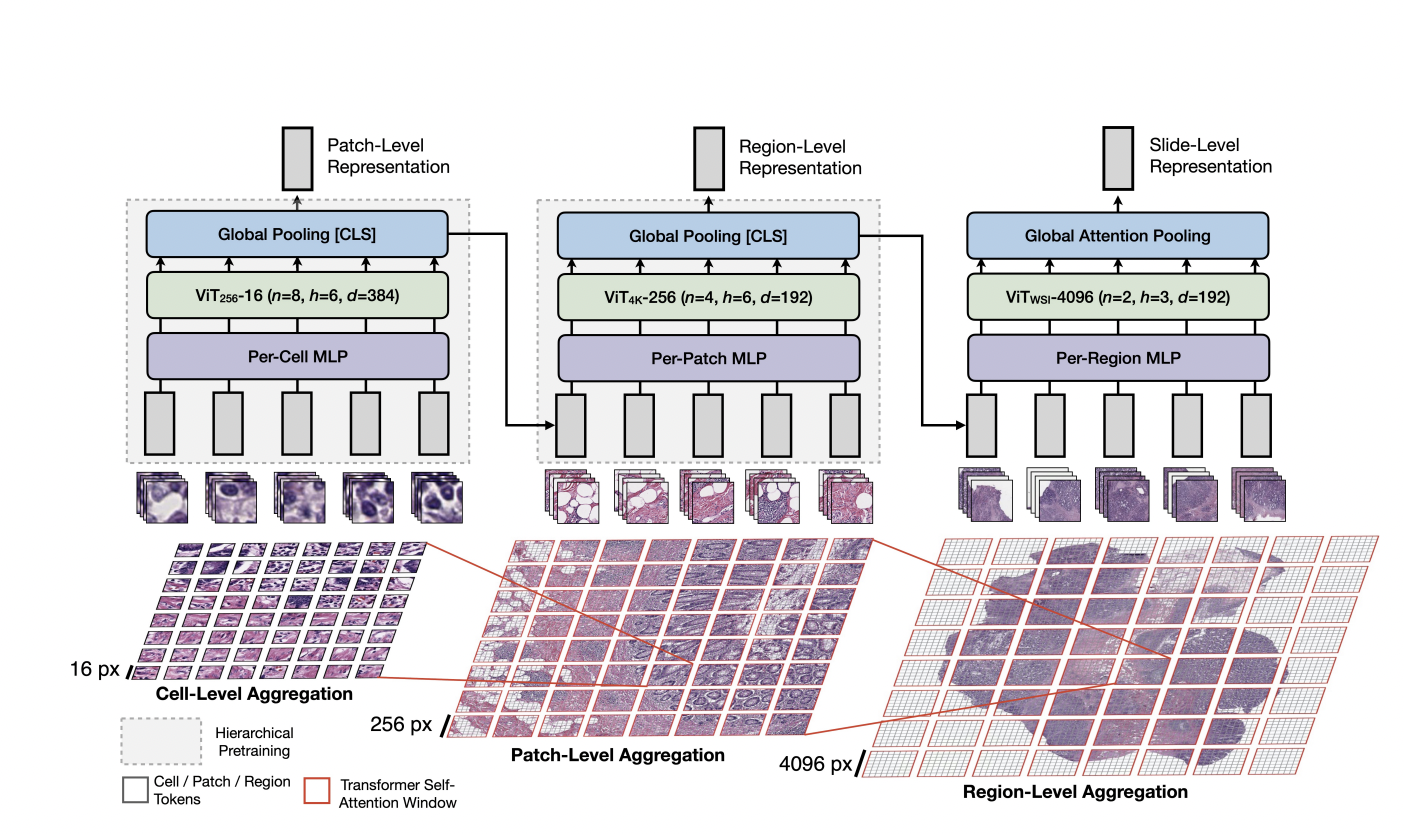
The researchers developed the Hierarchical Image Pyramid Transformer, a Transformer-based architecture for hierarchical aggregation of visual tokens and pretraining in gigapixel pathological pictures (HIPT). The researchers used a three-stage hierarchical architecture that performs bottom-up aggregation from [16 x 16] visual tokens in their corresponding 256 x 256 and 4096 x 4096 windows to eventually build the slide-level representation, similar to how long document representations are learned in language modeling.
In two ways, the work pushes the bounds of both Vision Transformers and self-supervised learning. HIPT decomposed the issue of learning a good representation of a WSI into related representations, all of which can be learned through self-supervised learning, and used student-teacher knowledge distillation (DINO) to pretrain each aggregation layer with self-supervised learning on regions as large as 4096 x 4096.

The strategy outperformed standard MIL procedures, according to the researchers. The distinction is most noticeable in context-aware tasks like survival prediction, where a bigger context is valued in describing broader prognostic aspects in the tissue microenvironment.
The team outperformed various weakly-supervised architectures in slide-level classification using K-Nearest Neighbors on the model’s 4096 x 4096 representations — a significant step toward self-supervised slide-level representations. Finally, the researchers discovered that multi-head self-attention in self-supervised ViTs learns visual ideas in histopathological tissue, similar to self-supervised ViTs on natural images that can execute semantic segmentation of the scene architecture.
Conclusion
The study is a significant step toward self-supervised slide-level representation learning, as it shows that pre-trained and fine-tuned HIPT features outperform weakly supervised and KNN evaluations, respectively. Though DINO was utilized for hierarchical pre-training with traditional ViT blocks, the team plans to investigate other pre-training methods such as mask patch prediction and efficient ViT designs in the future. The concept of pretraining neural networks based on hierarchical relationships in massive, heterogeneous data modalities in order to obtain a patient- or population-level representation can be applied to various fields.
This Article is written as a summary article by Marktechpost Staff based on the paper 'Scaling Vision Transformers to Gigapixel Images via Hierarchical Self-Supervised Learning'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper, github. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.