Meta AI Team Introduces LegoNN: A New ML Framework For Building Modular Encoder-Decoder Models
Nowadays, computer programs can translate text from one language to another using a process known as machine translation (MT), sometimes known as automated translation. MT uses a machine translation engine to compare and contrast many sources and target languages.
Learning several implicit functions is necessary to train end-to-end models for automated speech recognition (ASR) and machine translation (MT). While an ASR model integrates phoneme recognition, speech modeling, and language generation, an MT model implicitly performs both word translation and language generation. These fully differentiable models are practical and have a clear conceptual foundation. They pass up chances to exchange logical operations common to several activities, like their decoders. This results in wasting computing resources during training and generally less comprehensible architectures.
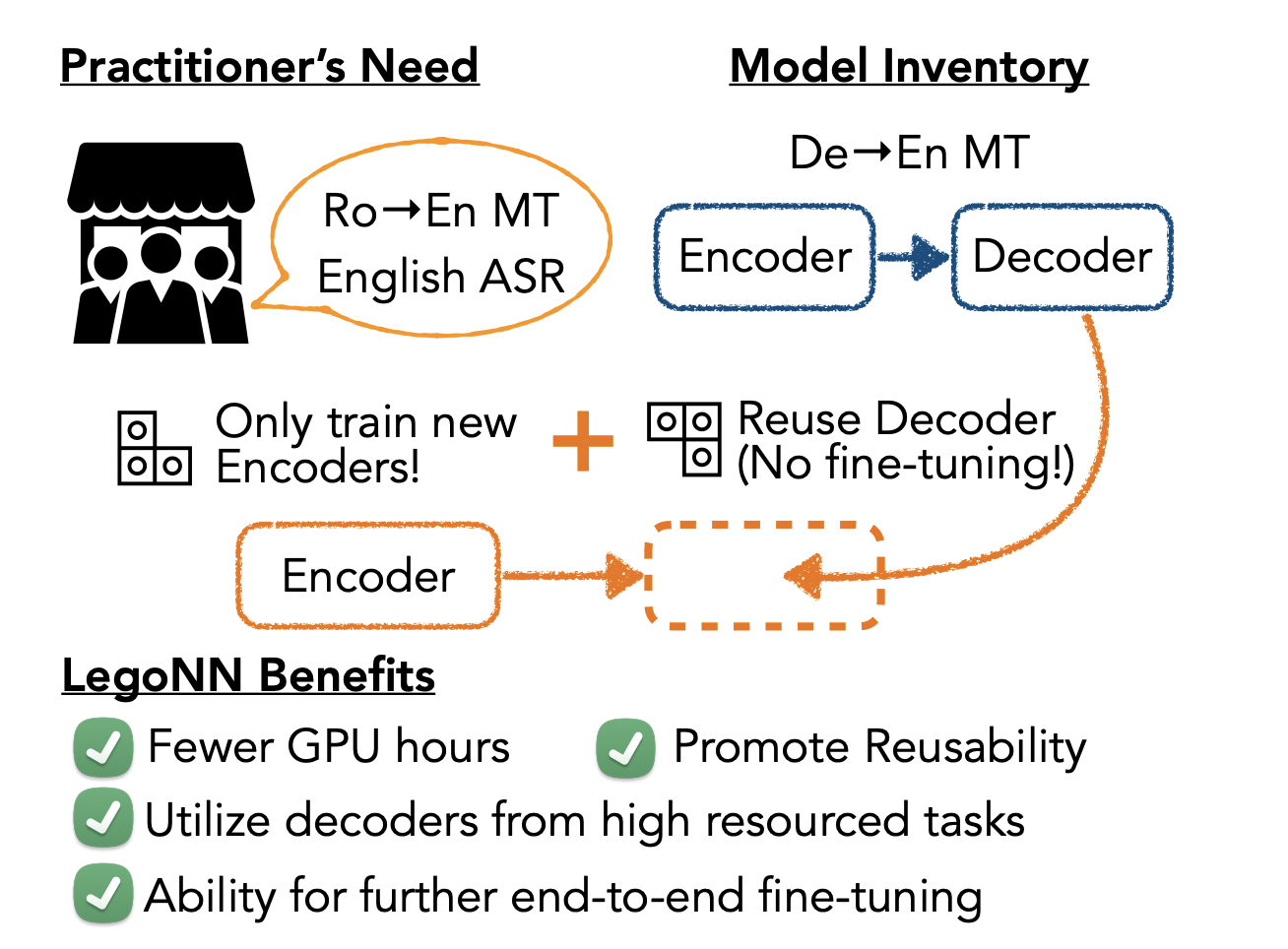
When designing software, modularity principles are used to create systems that are reusable within other programs and have modules with interpretable interfaces. Inspired by this, Meta AI researchers have developed LegoNN, a method for building encoder-decoder models with decoder modules that can be reused across diverse sequence generation tasks like MT, ASR, or Optical Character Recognition.
According to the researchers, modularity in AI models helps construct systems for under-resourced jobs by using shareable components from more resourced tasks and reduces computational resources by reusing components. Further, interpretable interfaces make it possible to track how well each encoder or decoder module is doing and how that affects the performance from beginning to end as a whole.
In the LegoNN encoder-decoder system, encoders produce a series of distributions over a discrete vocabulary derived from the final output labels, giving encoders an interpretable interface (e.g., phonemes or sub-words). The researchers enforce this modularity by adding an extra Connectionist Temporal Classification (CTC) loss on the encoder outputs during training.

Ingestor layers (ING) to the decoder modules so they can accept these distributions as inputs. For this, they tested two distinct ingestor layer types:
- A gradient-isolating Beam Convolution (BeamConv) layer
- A differentiable Weighted Embedding (WEmb) layer allows gradient flow throughout the whole network.
In their paper, “LegoNN: Building Modular Encoder-Decoder Models,” they propose a modality agnostic encoder for the sequence prediction task. These encoders use an output length controller (OLC) unit to adapt any input modality to a sequence of encoder representations that match the expected input length of another. Given that LegoNN decoder modules can be trained for one MT task and then reused for another MT task with a different source language or a sequence generation task with the same target language, like ASR or OCR.
Their research demonstrates how LegoNNs may be used to share trained decoders and intermediary modules between many tasks and domains without having to train separately for each task and requiring fine-tuning processes. The combined LegoNN model maintains the end-to-end differentiability of each distinct system, leaving space for future adjustments.
The results of their trials demonstrate that performance can be preserved while still achieving modularity. The performance of LegoNN models is comparable to nonmodular designs on the industry-standard large-scale En-De WMT and Switchboard ASR benchmarks (V-A). The team seamlessly combined a decoder module from a German-English (De-En) WMT system with other pre-trained encoder modules from various MT and ASR systems without any joint training or fine-tuning. By doing so, they showed that the value of modularity and achieving generation performance that is equal to or better than that of the Europarl English ASR task and the Romanian-English (Ro-En) WMT task (V-C).
The team also built an ASR system out of modules that have been trained independently on three different tasks. The systems were trained without fine-tuning and nearly no performance deterioration to show the adaptability of reusing LegoNN modules.
The Ro-En WMT baseline model is improved by 1.5 BLEU points after being fine-tuned for a few thousand steps, and LegoNN models made up of several tasks and domains can reduce the WER for the Europarl English ASR job by up to 19.5%.
In their future work, they plan to explore zero-shot learning scenarios for voice translation, which rely on a combination of ASR and MT modules, and combine the adaptability of LegoNN models with the outstanding performance of encoder pre-training techniques like BERT.
This Article is written as a summary article by Marktechpost Staff based on the paper 'LegoNN: Building Modular Encoder-Decoder Models'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper, ref. post. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.