Stanford and TRI AI Researchers Propose the Atemporal Probe (ATP), A New ML Model For Video-Language Analysis
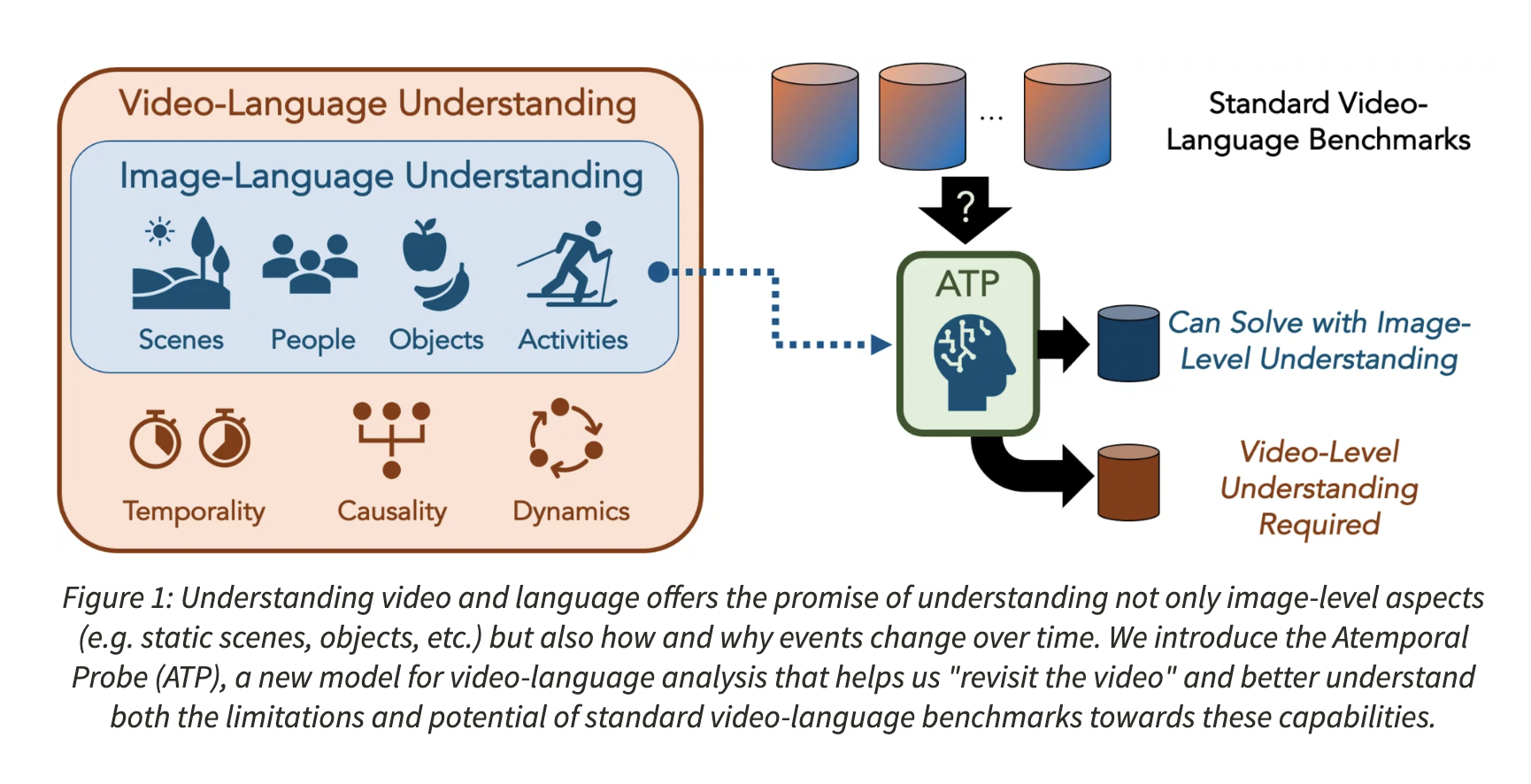
The idea that information provided through videos is better understood is based on the observation that information is seen throughout numerous images instead of only one. However, why is comprehending via video superior to an understanding with a single image? This fundamental query has previously received considerable attention in the field of action recognition on edited footage. With its continued study, Stanford hopes to provide a precise response in partnership with Toyota Research Institute (TRI). Understanding the complex temporal and causal linkages of events in movies and language is the primary goal of the research. Understanding these occurrences will make it possible to create interactive agents that can absorb information about social dynamics and visual concepts from their surroundings. The team wants to expand the work beyond the existing contexts of language and video because the natural language can describe more profound, more complicated, and dynamic event attributes.
Standard baselines often include selecting a random frame or average data across frames to evaluate “image-constrained” or atemporal knowledge of films. However, as films are thought to be intrinsically noisy, linked collections of frames, this might not be a typical sample. Because of various factors, including camera motion blur, odd camera viewpoints, etc., several investigations demonstrated that not all frames provide clear semantic information. This leads to the conclusion that typical methodologies may not represent the limit of image-level understanding. Actual video-level understanding starts at this point. The team introduced Atemporal Probe (ATP), a novel method for video-language analysis built on the advancements in the recent image-language foundation. The strategy aims to respond more thoroughly to the earlier posed question. ATP learns to select a single image-level input from a weakly sampled series of video frames. The architecture of ATP includes several bottleneck constraints, allowing this choice to be made without consideration of time. The baseline accuracy of multimodal models confined by image-level comprehension is considerably more tightly bound by ATP.

The researchers are eager to work towards their long-term objective of developing interactive agents that learn about intricate global events through video and language. The shortcomings and possibilities of the present video-language benchmarks were examined by using ATP to perform everyday tasks, such as video question answering and text-to-video retrieval. Surprisingly, it was shown that even when compared to recent large-scale video-language models and in situations designed explicitly to benchmark more excellent video-level knowledge, an understanding of event temporality is sometimes not required to obtain suitable or cutting-edge performance. The potential in-the-loop applications of ATP for enhancing dataset construction and the effectiveness and precision of video-level reasoning models were also investigated. The planned ATP model design and the team’s study findings were also published in a paper recently.
This Article is written as a summary article by Marktechpost Staff based on the paper ' Revisiting the “Video” in Video-Language Understanding'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper, project, and blog. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.