Google AI Introduces The Auto Arborist Dataset: A Multiview Urban Tree Classification Dataset That Consists Of ~2.6M Trees And >320 Genera
Researchers and policymakers can quantify ecosystem services, such as the improvement of air quality, carbon sequestration, and benefits to public health, track damage from extreme weather events, and target plant species to increase robustness to climate change, disease, and infestation with urban forest monitoring, which measures the size, health, and species distribution of trees in cities over time.
Even the most basic information regarding the location and tree species is lacking in many urban areas. Since conducting a tree census to gather this information is expensive, it is usually only done by large cities. In addition, urban social disparity, including socioeconomic and racial inequality, is primarily a result of a lack of access to green space.
Monitoring urban forests permits the measurement of this inequity and its reduction goal, which is a crucial component of the environmental justice movement. But machine learning might significantly reduce the expenses associated with tree censuses by employing a combination of street-level and aerial data. The absence of extensive labeled datasets has been a significant obstacle to attempts to develop automatic urban tree species detection using aerial or street-level photos.
Google AI researchers have introduced the Auto Arborist Dataset, a multiview urban tree classification dataset that, at ~2.6 million trees and >320 genera, is two orders of magnitude larger than those in prior work. This new dataset will enable more accurate models for tree species classification and help to improve our understanding of the distribution of trees in urban areas.

The Dataset for Auto Arborists
Researchers used online tree censuses offered by several localities as a starting point for curating Auto Arborist. They checked that the data for each tree census under consideration included GPS coordinates and genus/species designations and was open to the public. Following this, the data were processed into a standard format, typical data entry errors (such as flipped latitude/longitude) were fixed, and the ground-truth genus names (and their usual misspellings or alternate names) were mapped to a common taxonomy. To avoid taxonomic complications brought on by hybrids and subspecies, as well as genus names are more widely accepted than species names, they have decided to concentrate on genus prediction (instead of species-level prognosis) as their primary objective.

The researcher then searched an RGB aerial image centered on the tree and all street-level photographs collected within 2-10 meters of it using the geolocation information provided for each tree. They finally filtered these images to increase the likelihood that the tree of interest is visible from each photograph and to protect user privacy. The elimination of photos containing persons judged by semantic segmentation and manual blurring, among other measures, was required for the latter problem.

Dataset Obstacles
A fundamental difficulty for computer vision is a generalization to new areas. Researchers need standards that completely capture real-world complexity, including geographic domain shift, long-tailed distributions, and data noise, to develop computer vision systems that truly handle real-world problems on a global scale. Although these models frequently achieve near-perfect accuracy on benchmarks, they perform differently when used outside the training distribution.
Being successful in places not included in the training set is one of the biggest hurdles for urban forest monitoring. Vision models must deal with distribution changes, where the test distribution from a new city differs from the training distribution. Geographically (for example, there is more Douglas fir in western Canada than in California) and according to the size of the city, genus distributions can vary (LA is much larger than Santa Monica and contains many more genera). The long-tailed, fine-grained nature of tree taxa, many of which are extremely rare, can make it challenging for even human experts to distinguish between them.
Comparison and evaluation
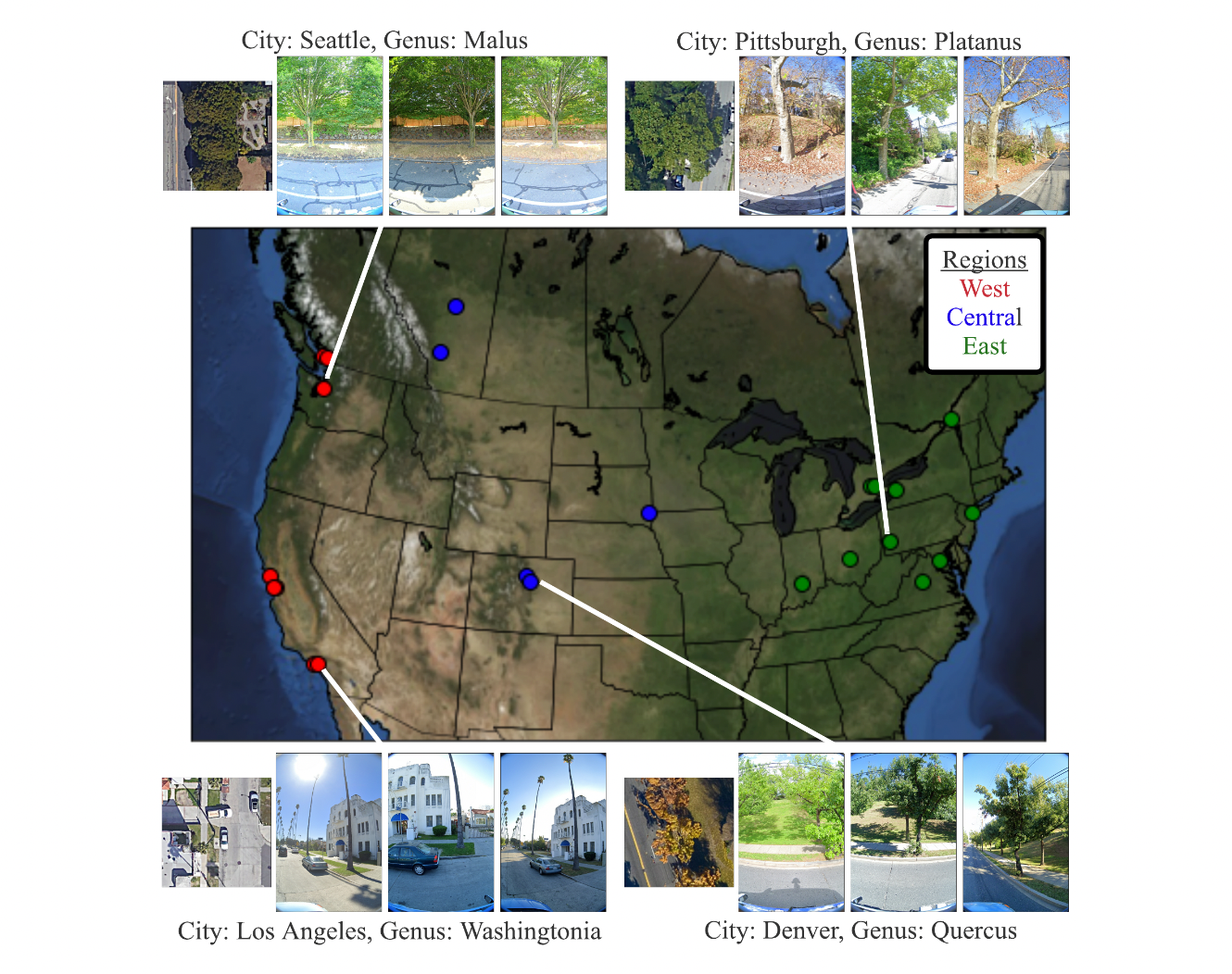
Researchers created a benchmark to assess the dataset’s performance in the long tail of the distribution and domain generalization.
At three levels, they produced training and test splits. To determine how successfully a city generalizes itself, it first split into each town (depending on latitude or longitude). Second, the group training sets at the city level into the West, Central, and East regions, holding out one city from each. The training sets from the three locations are then combined. They provide accuracy and class-averaged recall for frequent, familiar, and rare species on the associated held-out test sets for each of these divides.
This Article is written as a summary article by Marktechpost Staff based on the paper 'The Auto Arborist Dataset: A Large-Scale Benchmark for Multiview Urban Forest Monitoring Under Domain Shift'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper, blog post and github. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.