OpenAI Introduces Video PreTraining (VPT), A Novel Semi-Supervised Imitation Learning Technique
There is a tonne of freely accessible videos on the internet that one can use to learn. However, these videos, such as videos of a digital artist drawing a stunning sunset, don’t show the precise order in which the mouse was moved and the keys were pressed. To put it in another way, the absence of action labels creates a new problem because they don’t provide a record of how things were achieved.
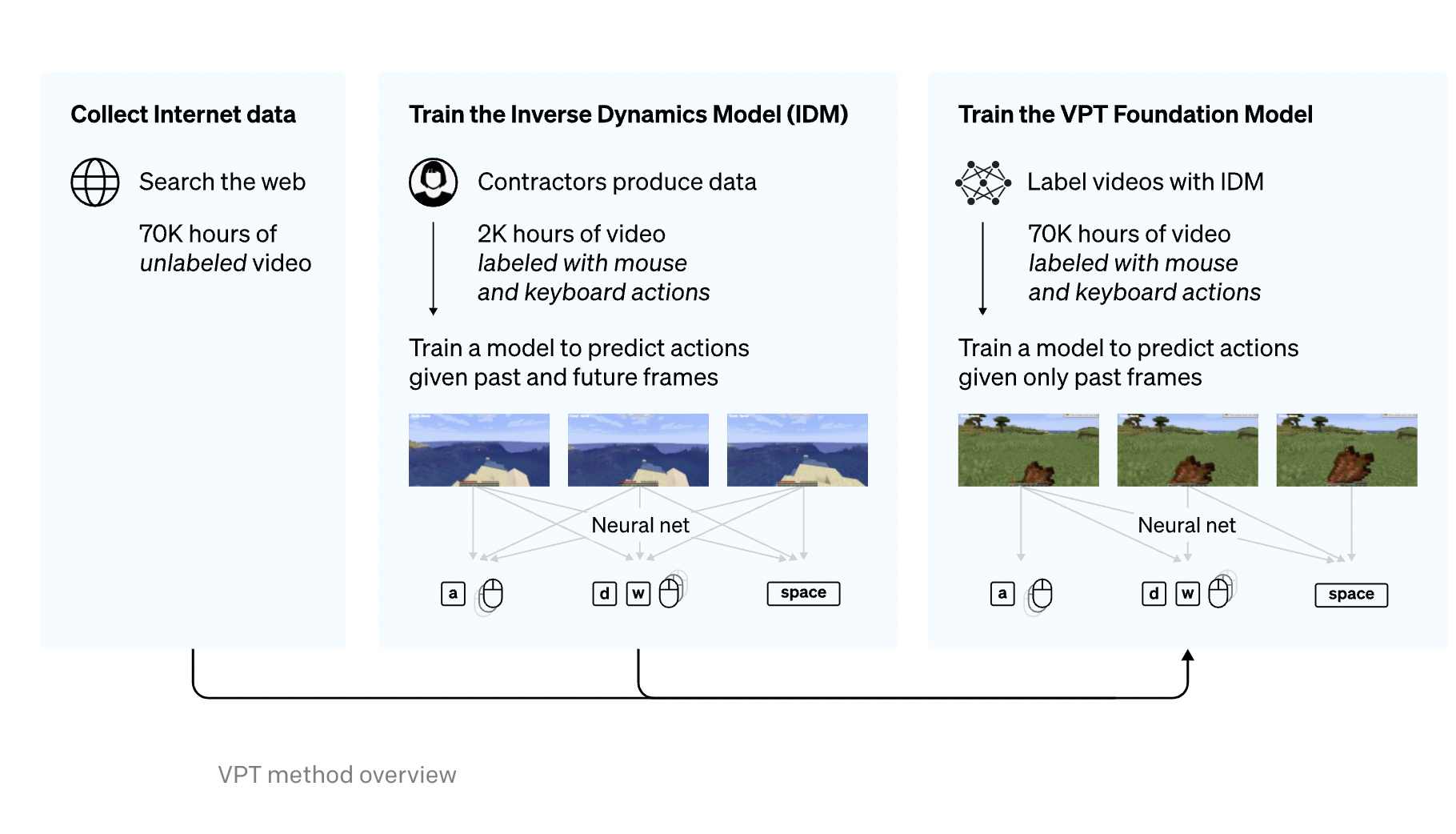
OpenAI team introduces Video PreTraining, a novel but straightforward semi-supervised imitation learning technique, to use the abundance of unlabeled video data readily accessible on the internet (VPT).
The researchers began by compiling a small dataset from contractors, recording both their video and their actions, in addition to their visual movements. They then use this information to train an inverse dynamics model (IDM), which predicts the actions taken at each video step.
The researchers state that this work is simpler and requires significantly fewer data. It is also possible to train the trained IDM to label a much bigger dataset of internet videos using behavioral cloning.
The researchers selected Minecraft to validate their method. They chose it because it has many freely available video data, is open-ended, and offers a wide variety of activities, like real-life applications like computer use. Their findings suggest that their model is more broadly applicable than earlier works in Minecraft that use simpler action spaces to ease exploration.
Their behavioral cloning model (the “VPT foundation model”) completes Minecraft tasks that are practically hard to complete using reinforcement learning from scratch. It was trained on 70,000 hours of IDM-labeled web video. It learns to cut down trees to gather logs, craft those logs into planks, and then craft those planks into a crafting table; for a human player of Minecraft, this process would take about 50 seconds or 1,000 consecutive game actions. The model also demonstrates other difficult actions players frequently take, like swimming, hunting, and devouring prey.
Foundation models are intended to be broadly competent over a wide range of tasks and to have a broad behavioral profile. It is usual practice to fine-tune these models to smaller, more focused datasets to include new knowledge or allow them to specialize on a narrower task distribution. The researchers observed a significant improvement in the foundation model’s ability to reliably perform early-game abilities after fine-tuning.
They suggest that training an IDM (as a step in the VPT pipeline) using labeled contractor data is considerably more efficient than training a BC foundation model directly using the same small contractor dataset.

Reinforcement learning (RL) is a potent tool for producing high, or even superhuman, performance when a reward function can be specified. However, most RL approaches use random exploration priors to overcome difficult exploration obstacles in many tasks. For instance, models are frequently rewarded for acting randomly through entropy bonuses. Since simulating human behavior is expected to be far more beneficial than random actions, the VPT model should be much superior before RL.
The team gave their model the difficult assignment of locating a diamond pickaxe. This feature is unique to Minecraft and is more challenging when utilizing the original human interface. A long and intricate series of smaller activities must be completed to craft a diamond pickaxe. They pay agents for each sequence component to make this task tractable.
The researchers discovered that an RL policy taught from a random initialization (the traditional RL method) hardly ever receives any reward and never learns to collect sticks or logs. Contrarily, fine-tuning from a VPT model not only learns to manufacture diamond pickaxes (which it does in 2.5 percent of 10-minute episodes of Minecraft), but it even has a human-level success rate at gathering all elements necessary to get to the diamond pickaxe. This is the first time a computer agent has been demonstrated that can create diamond tools in Minecraft, an activity that typically takes people over 20 minutes (24,000 actions).
VPT paves the way for enabling agents to learn to act by watching countless online films. VPT presents the intriguing prospect of directly learning large-scale behavioral priors in more than simply language, in contrast to contrastive approaches or generative video modeling, which would only produce representational priors.
This Article is written as a summary article by Marktechpost Staff based on the paper 'Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper, github and blog post. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.