Stanford AI Researchers Open-Source Diffusion-LM: A Novel And Controllable Language Model Based on Continuous Diffusions, Which Enables New Forms of Complex Fine-Grained Control Tasks
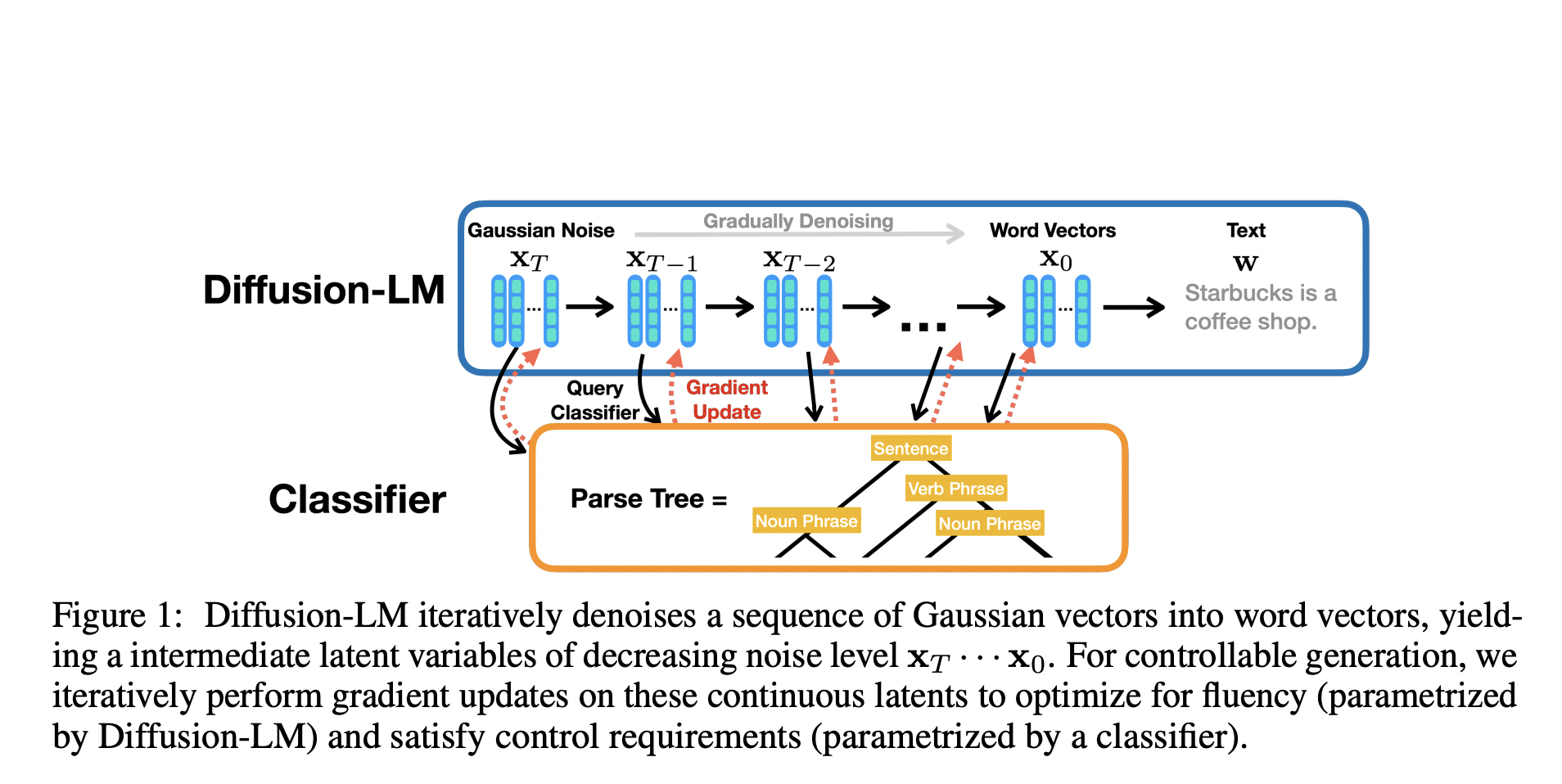
Language Models often behave in an unprecedented manner. Furthermore, natural language generation continues to face significant difficulties in controlling the behavior of language models without retraining. Gaining control over simple sentence properties (like sentiment) has allowed for some advancement in this area. However, the progress in intricate, fine-grained controls like syntactic structure has been little to nonexistent. Stanford University academics have developed an open-source Diffusion Language Model to solve this issue. This language model employs a plug-and-play control strategy, where the language model is fixed, and the generated text is controlled by a third-party classifier that judges how closely an output matches the intended parameters. Many elements of the desired output, like the necessary parts of speech, the syntax tree, or sentence length, are controllable by the user.
When evaluated over five controlled text creation tasks, this non-autoregressive generative language model outperforms prior approaches like GPT-3. Several existing generative language models are autoregressive. They can anticipate the word that will come next in a sequence, add it to the existing sequence, and then utilize the modified sequence as input for future predictions. These models can produce language identical to that written by humans, and they can produce text to address various issues, from interactive conversation to question-and-answer scenarios. However, the user has little to no control over the generated output in these existing systems regarding factors like desired sentence length, structure, or sentiment. The fine-tuning of the LM to allow it to accept an extra control input has been suggested as a potential solution to this issue. However, this update can be computationally demanding and may not be generalized to accommodate numerous control parameters. The alternative strategy uses a plug-and-play method, which maintains the LM’s settings at a fixed value and directs the generation using an external classifier that gauges how closely the output is aligned with the intended parameters. Autoregressive model steering has proven to be difficult, nevertheless. Instead of attempting to direct an autoregressive LM, the Stanford researchers paved a new path for language development by creating a diffusion model.

While these models have demonstrated excellent performance in computer vision and other continuous domains, their potency has not been examined in areas like text production. Diffusion-LM, in the opinion of the researchers, is the original diffusion model for text production. The model underwent two adjustments. The first consists of an embedding function that converts words into vectors in the diffusion model’s continuous latent space. After that, a “rounding” technique was created to convert these vectors back to discrete words. The model creates text by treating a random vector in latent space as a noisy rendition of the output sentence’s embedding. The denoised embedding is then given to an outside classifier at each step, which creates a gradient update of the embedding for the following step in the iteration. The rounding method converts the final embedding into the text after completing the iterations. The team has found that the Diffusion-LM is slower compared to other models for both training and runtime decoding. The researchers are enthusiastic about the additions that the community can make. Hence, they have open-sourced the code currently accessible on Github.
This Article is written as a summary article by Marktechpost Staff based on the paper 'Diffusion-LM Improves Controllable Text Generation'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper, github and reference post. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.