Instacart Introduces Griffin: An Extensible And Self-Serving Machine Learning Platform
Instacart provides grocery delivery and pickup services in the US and Canada. Customers can use the service to order goods from participating stores, and a personal shopper will conduct the shopping for them.
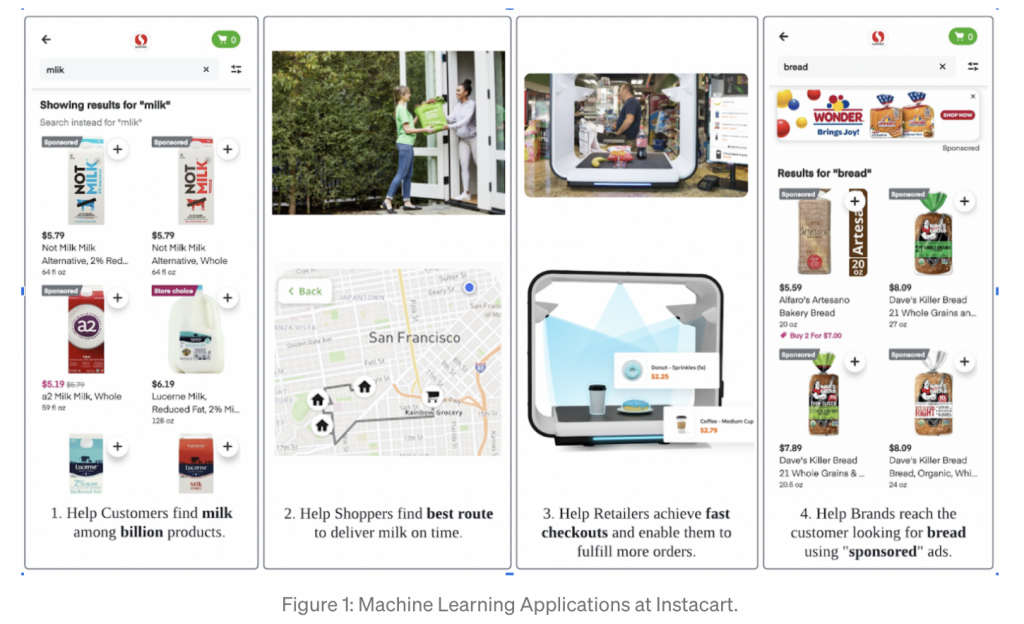
As one can imagine, the Instacart experience relies heavily on machine learning. Nearly every product and business innovation at the company is based on machine learning (ML), including helping users locate the ideal things in a catalog of more than 1 billion products and enabling 5,000+ brand partners to connect their products to potential customers.
In 2016, the company began creating its machine learning framework called Lore. Without having to worry about system specifics, Lore allowed machine learning engineers (MLEs) to create and train ML models.
However, the quantity, variety, and complexity of machine learning applications have grown as the organization has expanded. Due to its monolithic architecture, Lore turned into a bottleneck. In order to make room for additional features, they had to rework Lore’s core design.
Their recent development introduces Griffin, an extensible and self-serving machine learning platform based on microservice architecture, as a hybrid approach to solving this issue.
There are many different machine learning disciplines, and different machine learning tools and methods are developed for varied application scenarios. The team adopted a hybrid strategy for MLOps at Instacart to use numerous tools and satisfy various machine learning objectives.
To serve a variety of use scenarios, they combine third-party solutions (including Snowflake, AWS, Databricks, and Ray) with internal abstraction layers that offer consistent access to those solutions. This strategy enables them to deploy customized and varied solutions while keeping up with advancements in the MLOps industry.
Griffin was created to make it easier for MLEs (Machine Learning Engineers) to easily manage product releases, swiftly iterate on machine learning models, and closely monitor their production applications.
Instacart team developed the system using a few key system concerns based on these objectives:
- Scalability: At Instacart, the platform should be able to host thousands of machine learning applications.
- Extensibility: The platform should be adaptable to add new features and interface with other machine learning and data management backends.
- Generality: Despite the platform’s extensive connection with third-party solutions, it should offer a unified workflow and constant user experience.
As stated by the team, the platform has four basic components:
- MLCLI interface for using the platform to create machine learning applications and control the model lifecycle. MLCLI gives MLEs the ability to alter training, evaluating, and inferring tasks in their applications and carry them out inside containers (including, but not limited to, Docker). This creates a consistent interface and eliminates problems brought on by variations in the execution environment.
- Workflow Manager & ML Launcher: This pipeline orchestrator uses Airflow to schedule containers and ML Launcher, a proprietary abstraction, to containerize job execution.
- Feature Marketplace: They created a feature management platform for data that supports batch and real-time feature engineering using platforms like Snowflake, Spark, and Flink. It controls feature computation, offers feature storage, supports feature discoverability, enables feature versioning, stops offline/online feature drift, and permits feature sharing. With the help of the hybrid solution, they balanced latency and storage costs for scalability.
- Training & Inference platform to carry out the tasks: To adopt open-source frameworks like Tensorflow, Pytorch, Sklearn, XGBoost, FastText, and Faiss, they created a training and inference platform that is framework-independent. They standardize package management, metadata management, and code management to accommodate the variety of frameworks and to assure trustworthy model deployment in production. They state that it is now possible to triple the number of machine learning applications in a year thanks to the platform’s ability to let MLEs adapt the model architecture and inference procedure.
The team believes that these aspects make up their extensible platform in their own right and allow the creation of specific solutions for various use cases, such as real-time recommendations.
This Article is written as a summary article by Marktechpost Staff based on the Instacart article 'Griffin: How Instacart’s ML Platform Tripled ML Applications in a year'. All Credit For This Research Goes To Researchers on This Project. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.