Researchers from George Mason and Emory University Develop ‘RES’: a Robust Python Framework for Learning to Explain DNNs (Deep Neural Networks) with Explanation Supervision
The study on explainability or explainable AI is currently receiving a lot of attention as DNNs become accessible in a variety of application domains. Many explainability techniques that attempt to provide the local explanation of the DNNs prediction for a particular instance, such as techniques that provide saliency maps for understanding which sub-parts in an instance are most responsible for the model prediction, have been proposed in an effort to open the black box of DNNs.
While local explanation techniques have seen a rapid growth in research in recent years, the majority of attention has been placed on handling the generation of explanations rather than understanding whether the explanations are accurate or reasonable, what to do if they are, and how to modify the model to produce more accurate or reasonable explanations.
Explanation supervision strategies, which assist model builders in improving their models by utilizing supervision signals obtained from explanation procedures, have just begun to demonstrate some promising results. The implications include enhancing the intrinsic interpretability and generalizability of DNNs in a variety of data formats where correct human annotation labels can be supplied to each data characteristic.
Text data and attributed data are examples of these data types. However, there is still a lack of study on managing explanations on picture data, where the explanation is visualized using saliency maps. The inaccuracy of the human explanation boundary and the incompleteness of the human explanation region are just a couple of the inherent difficulties that come with regulating visual explanations.
In a recent paper, researchers from George Mason University and Emory University suggested a general paradigm for teaching DNNs to explain themselves under explanation supervision. The group put forth a unifying framework that permits explanation supervision on DNNs with labels for both positive and negative explanations and can be used with the many differentiable explanation techniques now in use.

Researchers created a robust model aim that can manage the supervision signal of noisy human annotation labels. In order to use the noisy human annotation labels as the supervision signal, they suggested a novel robust explanation loss that can manage the challenges of an imprecise border, an incomplete region, as well as an inconsistent distribution. An upper bound for the generalization error of using the suggested robust explanation loss for training the backbone DNN models has been established by researchers using a formal theorem.
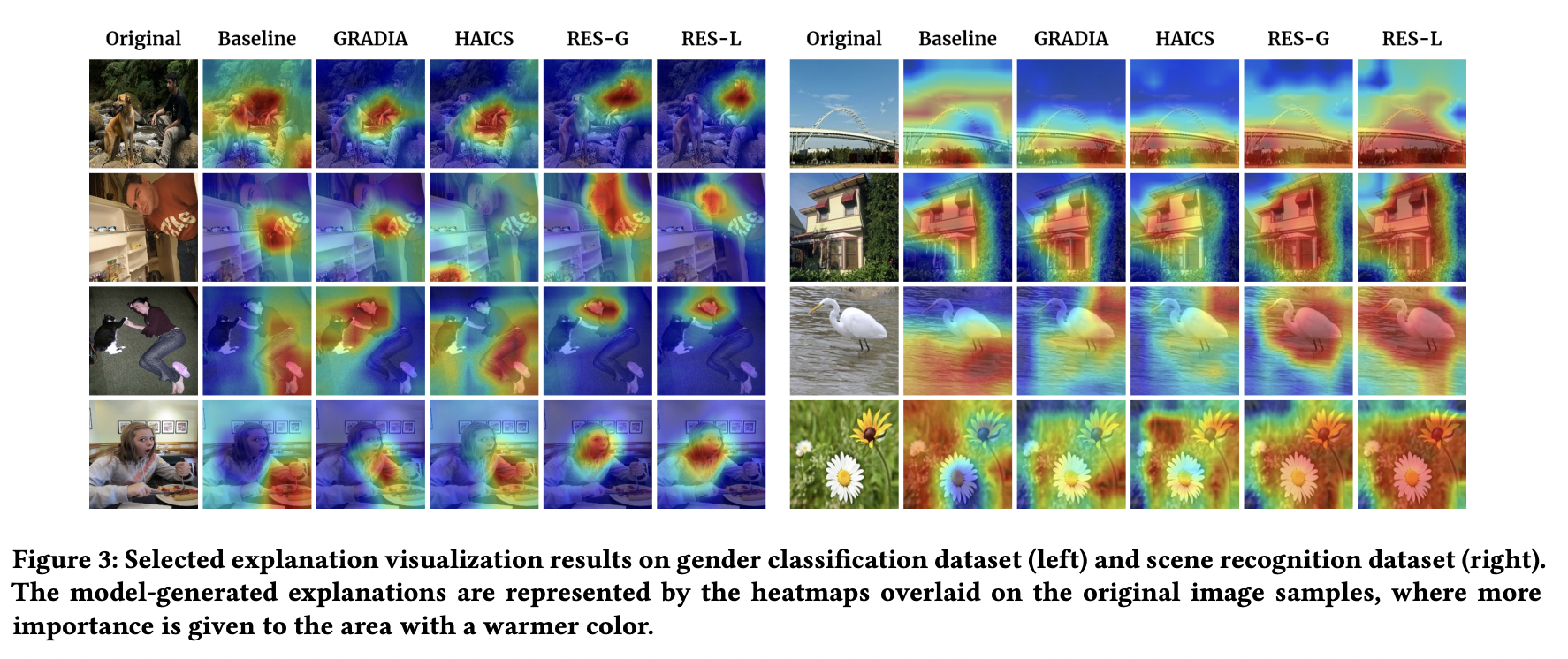
The group carried out extensive experimental quantitative and qualitative analyses to confirm the efficacy of the suggested paradigm. Numerous tests using two real-world picture datasets for scene recognition and gender categorization showed that the suggested framework significantly increased the predictability and explainability of the base DNNs. Additionally, qualitative evaluations were offered to show how effective the suggested framework is through case studies and user studies of the model explanation.
Conclusion
Researchers from George Mason University and Emory University recently collaborated to develop a novel explanation model objective that can handle the noisy human annotation labels as the supervision signal with a theoretical justification of the benefit to model generalizability. This work was published as a recent paper that proposed a generic framework for visual explanation supervision. Extensive tests on two real-world picture datasets show how the proposed framework improves the performance of the backbone DNNs model as well as the explainability of the explanation. The studies have shown the effectiveness of the suggested RES framework under a fairly small number of training samples, even though the additional data of human explanation labels may not be readily available. This could be advantageous for application domains where data samples are scarce and difficult to obtain.
This Article is written as a summary article by Marktechpost Staff based on the paper 'RES: A Robust Framework for Guiding Visual Explanation'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper and github. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.