AI Researchers From China Introduce a New Vision GNN (ViG) Architecture to Extract Graph Level Feature for Visual Tasks

Visual perception is more adaptable and practical when an image is viewed as a graph. In computer vision, several networks handle the input image in various ways. Fig. 1 illustrates the grid, sequence, and graph representations of the image. In this research, the image is processed more flexibly than the standard grid or sequence representation. In order to extract graph-level features for visual tasks, this work proposes to represent the image as a graph structure and introduces a new Vision GNN (ViG) architecture.
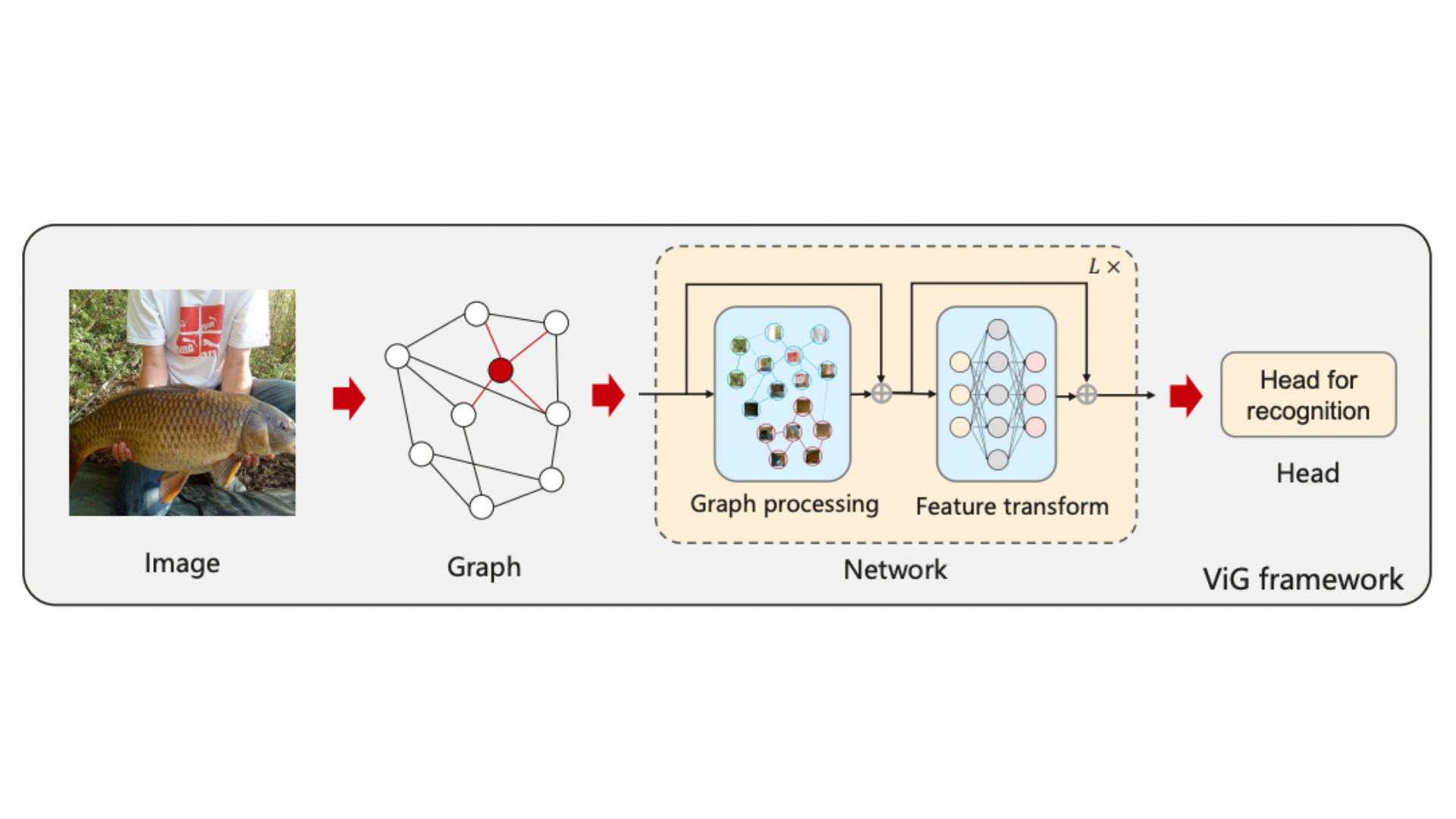
This research partitions the input image into several patches and views each patch as a node. The ViG model converts and shares information across all the nodes after creating the graph of image patches. The primary cells of ViG include Graph Convolutional Network (GCN) module and Feed Forward Network (FFN) module. GCN is utilized for processing information of graph, and FFN is used for feature transformation of the node. Fig. 2 showcases the proposed framework of the ViG model.
This research creates two different network architectures for ViG, namely an isotropic architecture and a pyramid architecture, to conduct a thorough comparison with other varieties of neural networks. This research adds a positional encoding vector to each node feature to express the position information of the nodes. The popular benchmark dataset ImageNet ILSVRC 2012 is utilized to classify the images. The dataset has 120M training images and 50K validation images that fall within 1000 categories.
This framework uses dilated aggregation in the Grapher module for all ViG models. GELU is utilized as the nonlinear activation function. The data augmentation techniques include repeated augment, mixup, cutmix, and random augment. RetinaNet and Mask R-CNN are used as the detection frameworks for the COCO detection challenge, with the Pyramid ViG serving as the backbone. All models are trained on 8 NVIDIA V100 GPUs, and the networks are built using PyTorch and MindSpore.
Free-2 Min AI NewsletterJoin 500,000+ AI Folks
The isotropic ViG-Ti model achieves top-1 accuracy of 73.9 percent, which is 1.7 percent better than the DeiT-Ti model with a similar computational cost. The results of the pyramid ViG series prove that the graph neural network has the potential to be a fundamental part of computer vision systems and performs well on visual tasks.
This work uses the isotropic ViG-Ti as the base architecture and conducts an ablation study of the proposed method for the ImageNet classification task. The results demonstrate that the top-1 accuracies of various graph convolutions are superior to those of DeiT-Ti compared to the representative variants, demonstrating the adaptability of ViG architecture. Additionally, the FC layers in the Grapher module and the FFN block’s feature transformation are introduced in this research.
In the object detection task, pyramid ViG-S outperforms representative backbones of various types. It can be seen from the visualization that the suggested model can choose the content-related nodes as the first-order neighbors. In the shallow layer, low-level and local characteristics like color and texture are frequently used to select the neighbor nodes. Thus, it demonstrates how the ViG network may gradually connect the nodes through its content and semantic representation and assist in improving object recognition. This work overcomes the over-smoothing problem caused by using graph convolution directly.
As a result, the authors have suggested a novel network to explore the picture representation as graph data and utilize graph neural networks for visual tasks. Based on it, the ViG network is created, including both isotropic and pyramid architectures, by dividing the images into patches and considering them as graph nodes. Numerous object detection and picture recognition investigations support the efficiency of the suggested ViG architecture.
This Article is written as a research summary article by Marktechpost research staff based on the research paper 'Vision GNN: An Image is Worth Graph of Nodes'. All credit for this research goes to researchers on this project. Checkout the paper, github. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.