Meta AI Introduces the First Model Capable of Automatically Verifying Hundreds of Thousands of Citations at Once
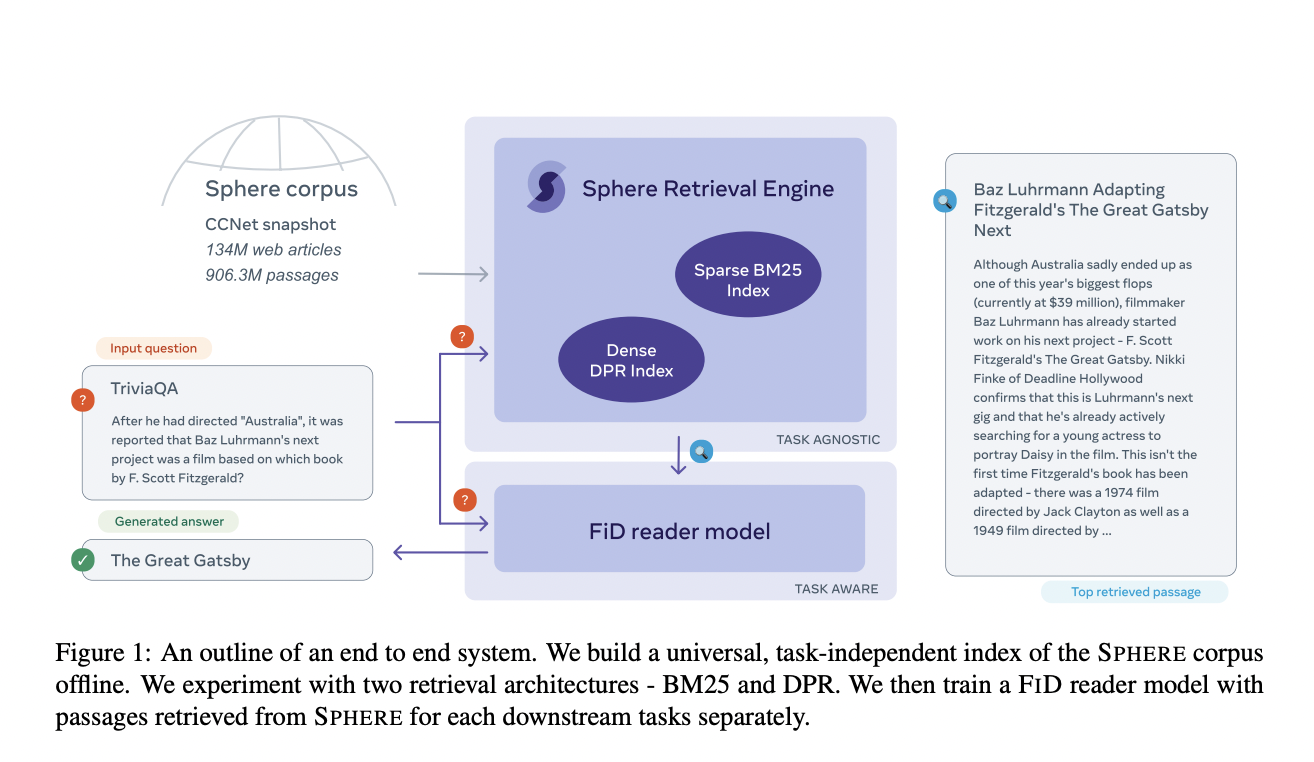
Wikipedia is the most used encyclopaedia of all time for research, background information, and other purposes. It has over 6.5 million articles. The question of how to verify the accuracy of the information always lingers in the background, despite how easily accessible it is. Although Wikipedia is crowdsourced, which mandates that facts be verified, all quotations, contentious assertions, and information about living individuals must include a citation. However, keeping up with the more than 17,000 new articles uploaded each month is challenging for volunteers due to the ever-increasing amount of material available. The discovery that a US teen wrote 27,000 entries in a language they did not speak in 2020 is one incident that shows that online encyclopaedias are not a perfect source of information. Although malicious attempts to edit Wikipedia articles occasionally occur, factual errors are typically the result of a well-meaning person making a mistake. This is the problem that Meta seeks to solve. A research team at Meta has developed Sphere, the first-ever model to automatically scan millions of citations at once to determine whether they genuinely support the related assertions. The team made an impressive dataset for this task which consists of 134 million public web pages; it was an order of magnitude larger and substantially more complex than anything previously used for this kind of research. Editors can manually assess the cases most likely to be problematic without having to trawl through thousands of properly cited assertions because it draws attention to citations that may be questionable. The model suggests a more trustworthy source and identifies the text that supports the argument if a citation appears irrelevant.
The team’s goal is to create a platform that will assist Wikipedia editors in systematically identifying citation problems and mass editing the text of the associated article. The team thinks that by teaching machines to comprehend the relationship between difficult text sections and the papers they mention, their model can aid the academic community in advancing AI toward better systems. Meta presented an example of an incomplete citation that the model discovered on the Wikipedia article for the Blackfoot Confederacy to demonstrate the capabilities of Sphere. The article mentions Joe Hipp, the first Native American to contend for the WBA World Heavyweight title, under the section on Notable Blackfoot individuals. Even if Hipp or boxing were not mentioned on the linked website, the model discovered a more appropriate citation in a 2015 story from the Great Falls Tribune by glancing through the Sphere database. Sphere’s extraordinary powers were displayed when it was discovered that the passage the model found does not explicitly reference boxing. The model’s ability to understand natural language allowed it to find a suitable reference. The AI model to automatically validate citations is not yet used by Wikipedia. However, researchers at Meta want to one day integrate it into the platform for the encyclopedia’s editors to utilise. These models have a bright future because they are the initial elements of possible editors that can assist in real-time document verification. The comparison also noted that in addition to suggesting citations, the system would recommend auto-complete text based on pertinent web-based documents and provide editing suggestions. Sphere is currently open-sourced on Github, and the scientists at Meta are thrilled about these technological developments because they think they will be the foundation for making machines that can comprehend our world.
This Article is written as a summary article by Marktechpost Staff based on the research paper1 and paper2. All Credit For This Research Goes To Researchers on This Project. Checkout the github. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.