In A Latest Computer Vision Paper, Researchers Propose A Novel Framework To Leverage The Representation And Generalization Capability Of Pre-Trained Multi-Modal Models Towards Improved Open-Vocabulary Detection (OVD)

Open Vocabulary Detection attempts to generalize beyond the restricted number of base classes designated during the training phase. At inference, the objective is to recognize novel classes defined by an unbounded or open vocabulary. Due to the difficulty of the OVD problem, several types of weak supervision for novel categories are commonly utilized, such as additional image-caption pairs to increase the vocabulary, image-level labels on classification datasets, and pretrained open-vocabulary classification models like CLIP.
The intrinsic mismatch between the region and image-level signals is one of the critical issues with extending vocabulary using image-level supervision (ILS) or pretrained models learned using ILS. The use of weak supervision to expand the vocabulary makes sense since the expense of annotating big-category detection datasets is prohibitively expensive. In contrast, image-text/label pairings are easily accessible via large categorization datasets or online sources. Because the CLIP model is developed with full-scale pictures, pretrained CLIP embeddings utilized in previous OVD models do not perform well in finding object areas.
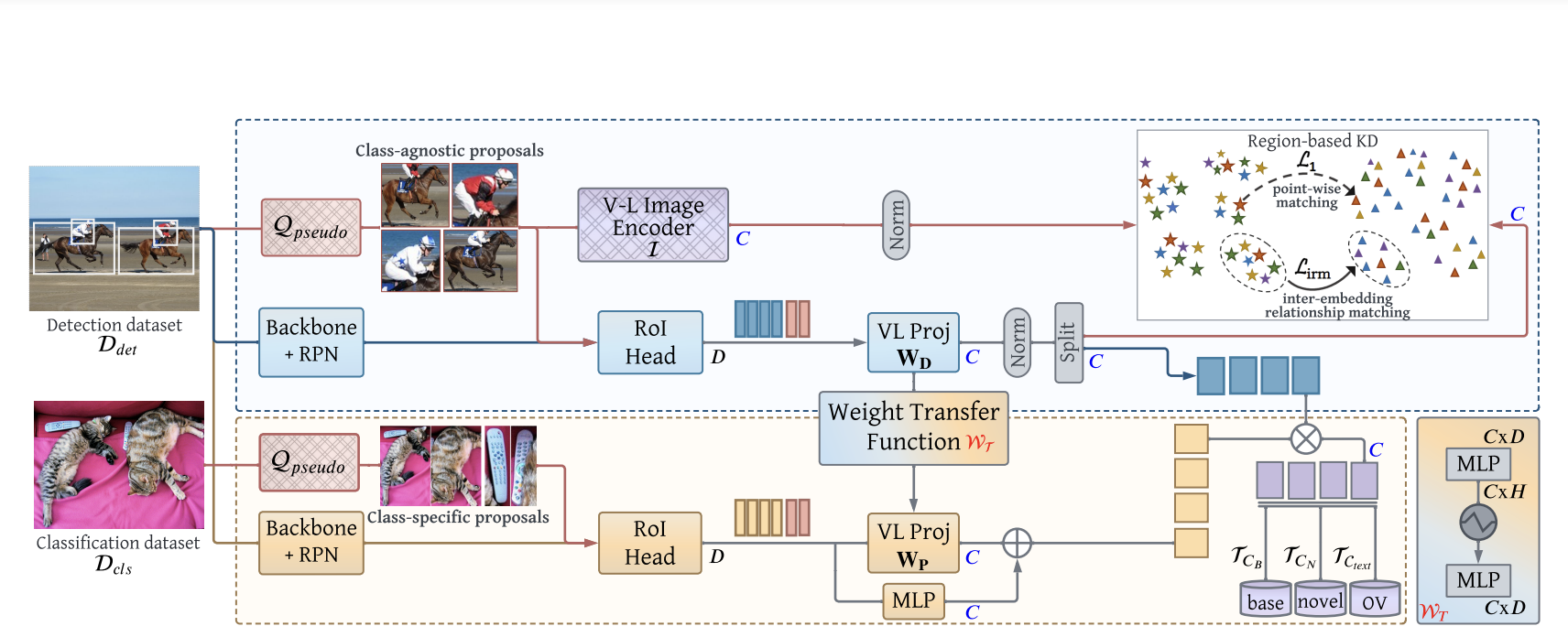
The latest work investigates expensive pretraining with supplementary objectives or heuristics such as the max-score or max-size boxes for label grounding in pictures. Similarly, pictures with poor supervision, such as caption descriptions or image-level labelling, do not transmit exact object-centric information. Researchers set out in this study to bridge the gap between object-centric and image-centric representations inside the OVD pipeline. They suggest using the pretrained multi-modal vision transformer (ViT) to generate high-quality class-agnostic and class-specific object recommendations.
The proposed method links image, region, and language representations to improve generalization to novel open-vocabulary items. The class-agnostic object proposals are then used to extract region-specific information from the CLIP visual embeddings, allowing them to be utilized for local objects. Furthermore, the class-specific proposal set enables us to visually ground a broader vocabulary, assisting in generalization to new categories. The third and most critical topic is making visual-language (VL) mapping compatible with local object-centric data. They present a region-conditioned weight transfer approach that tightly integrates image and region VL mapping.
Free-2 Min AI NewsletterJoin 500,000+ AI Folks
This study makes key contributions as follows:
- Propose region-based knowledge distillation to modify image-centric CLIP embeddings for local regions, enhancing alignment between region and language embeddings
- To visually ground weak picture labels, the technique uses high-quality object suggestions from pretrained multi-modal ViTs to conduct pseudo-labelling
- The contributions listed above are primarily aimed at the visual realm. To retain the benefits of object-centric alignment in the language domain, a unique weight transfer function is advised to condition the (pseudo-labeled) image-level VL mapping on the region-level VL mapping.
On COCO and LVIS benchmarks, our method achieves absolute gains of 11.9 and 5.0 AP on the novel and rare classes over the current SOTA methods. Further generalizability is demonstrated by our cross-dataset evaluations performed on COCO, OpenImages, and Objects365, leading to consistent improvements compared to existing methods. The code implementation of this paper is freely available on GitHub.
This Article is written as a summary article by Marktechpost Staff based on the research paper 'Bridging the Gap between Object and Image-level Representations for Open-Vocabulary Detection . All Credit For This Research Goes To Researchers on This Project. Checkout the paper and github link. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.