Researchers from China Propose DAT: a Deformable Vision Transformer to Compute Self-Attention in a Data-Aware Fashion
In recent years, the extension of transformers in the computer vision field has slowly made vision transformers (ViT) the state-of-the-art model for many topics, such as object detection or image classification. The main reason is their larger receptive field and their ability to model long-term relationships compared to their historical counterparts CNNs.
Nevertheless, there are still some drawbacks. In fact, the mechanism of ViT relies on three main matrixes, Query (Q), Key (K), and Value (V). These matrices are used to compute self-attention between the different tokens. In the original paper, the image is split into patches used as tokens. To compute self-attention for the first patch, the Q associated with it is used by comparing it with all the K/V of all the other tokens. In addition, in multi-head attention, multiple sets of matrices build different representations. With this technique, each patch is associated with an insane number of matrices, bringing high computational costs and the risk of overfitting.
This extra attention has been handled in different ways: Swin Transformer restricts attention to local windows, while Pyramid Vision Transformer (PVT) downsamples the key and value feature maps. Nevertheless, the shift window of the former results in slower growth of the receptive field, and the downsampling of the latter lead to severe information loss.
A group made of researchers from Amazon, Beijing Academy of AI and Tsinghua University hypothesized that the main limitation of these two approaches is that they are data-agnostic and, ideally, the set of key/values for a given query would have to be adapted to the specific input. Following this idea, they proposed a deformed self-attention module and used it as the backbone for a new architecture named Deformable Attention Transformer (DAT).
A comparison of the behaviour of different models, which helps to understand the mechanism of deformable attention intuitively, is shown below.

Deformable Attention Module

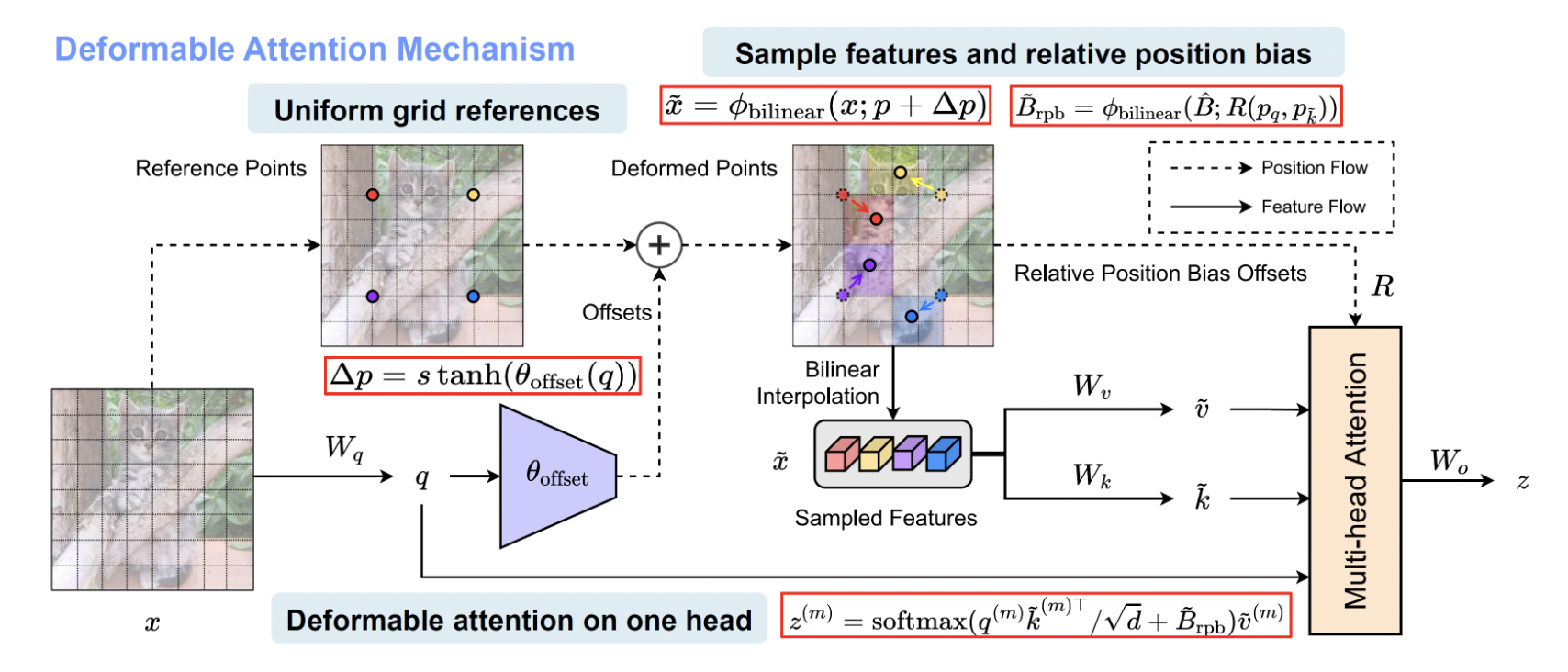
The module receives a feature map x and downsizes it to create a uniform grid of points normalized between -1 and 1, where (-1, -1) is the top-left corner of the grid while (1, 1) is the bottom right corner. The features are in parallel projected to obtain the Q matrix. The Q representation is then passed to a lightweight offset network (a straightforward network composed of a depthwise convolution followed by a GELU non-linearity and a 1×1 convolution, shown in the figure above on the right) that predicts the offset for each of the reference points. Its output is, in fact, a 2D matrix containing the value (x, y) for the offsets of each point. Once obtained the deformed point, each of the s x s regions around each reference point are bilinearly interpolated to obtain the deformed representations of K and V. Bilinear interpolation is a scheme that gives you a way to estimate the function at any point in a rectangle’s interior if the value of a function is known at the four corners of a rectangle. Q, K, and V are then used to compute multi-head self-attention together with the relative offset. All this process is clearly shown in the figure above.
Model Architectures

DAT has a pyramid structure composed of 4 stages with a progressively increasing stride. As illustrated in the figure above, an image is firstly embedded by a 4×4 non-overlapped convolution with stride 4, followed by a normalization layer to get the patch embeddings. Between two consecutive stages, there is a non-overlapped 2×2 convolution with stride 2 to downsample the feature map to halve the spatial size and double the feature dimensions. In the first stages, the feature maps are processed by a Swin Transformer window-based local attention to aggregate information locally and then passed through the deformable attention block to model the global relations.
Results
The authors experimented with DAT for the task of image classification, object detection and segmentation, obtaining SOTA results in all of them.
To also confirm the adaptable behaviour of DAT, the authors share a fascinating visualization of the learned keys. As it is possible to see from the figure below, deformable attention learns to place the keys mainly in the foreground, indicating that it focuses on the critical regions of the objects.

In conclusion, this paper proposed a very innovative technique to compute self-attention in a data-dependent way, improving the results and saving computational resources.
Our notes on a piece of paper:

This Article is written as a summary article by Marktechpost Staff based on the research paper 'Vision Transformer with Deformable Attention'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper and github link. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.