Apple Researchers Developed an Adaptive Bayesian Learning Agent That Employs a Novel Form of Dynamic Memory for Interpretable Sequential Optimisation
The practice of gradually learning from data to make better judgments over time is known as sequential optimization. It is frequently phrased in the machine learning literature as the multi-armed bandit problem, in which a reinforcement learning agent gradually learns to maximize overall reward. Such agents have been used in the development of experimentation and recommendation systems. However, there is a further issue in real-world deployments of such learning agents: the relative payoff of different bandit arms varies during the learning agent’s lifetime. Researchers have long been stuck on ensuring the agent can adapt to changing conditions.
To meet the challenging learning task under nonstationary settings, the agent must retain current knowledge and select which previous knowledge to forget. This option to forget is required for the agent to be able to adjust to changes in incentives. This knowledge may no longer be valid to minimize regret. Several techniques for such forgetting have been proposed, all to maximize the agent’s long-term yield in the face of changing conditions. These processes, however, are frequently not constructed with interpretability in mind.
Many bandit applications are only concerned with the challenge of minimizing regret without considering the associated human interpretability of its behaviour. Such interpretability must be prioritized in any real-world system in which people interact with the output of machine intelligence. Furthermore, many contemporary methods for dealing with non-stationarity often need an explicit specification of the memory that the agent should keep, such as through a predetermined temporal frame or a specified discounting factor.
Although hyperparameter optimization can identify appropriate values for these parameters, verifying that a given value would function well over the spectrum of non-stationarities a real-world system may experience impossible. To circumvent this constraint, researchers suggest a solution to the problem of reward adaptation that permits memory to grow and decrease dynamically as needed. They create an adaptive Bayesian learning agent program that uses a unique type of dynamic memory of previous rewards.
Our technique distinguishes itself by actively enabling interpretability with statistical hypothesis testing by aiming for the desired set point of statistical power when comparing rewards. They use sequential Bayes factors to measure statistical confidence in robust hypothesis testing. More particular, whenever the agent receives a new batch of data, it computes statistical confidence on the relative difference between arm rewards based on the data it has thus far observed. When the necessary degree of statistical confidence is obtained, suggesting that arm rewards are either considerably different or identical, the agent gradually forgets its knowledge of previous rewards, diminishing its memory.
They assess the performance of our approach to the problem of forgetting the ADWIN algorithm, an existing adaptive memory solution, using numerical simulations. They show that the agent achieves a compromise between noisy stability. If statistical confidence falls below a certain threshold, the agent begins to re-grow its memory of previous rewards until statistical confidence is restored. This enhances adaptivity to actual changes in genuine rewards and interpretability of this adaptation.
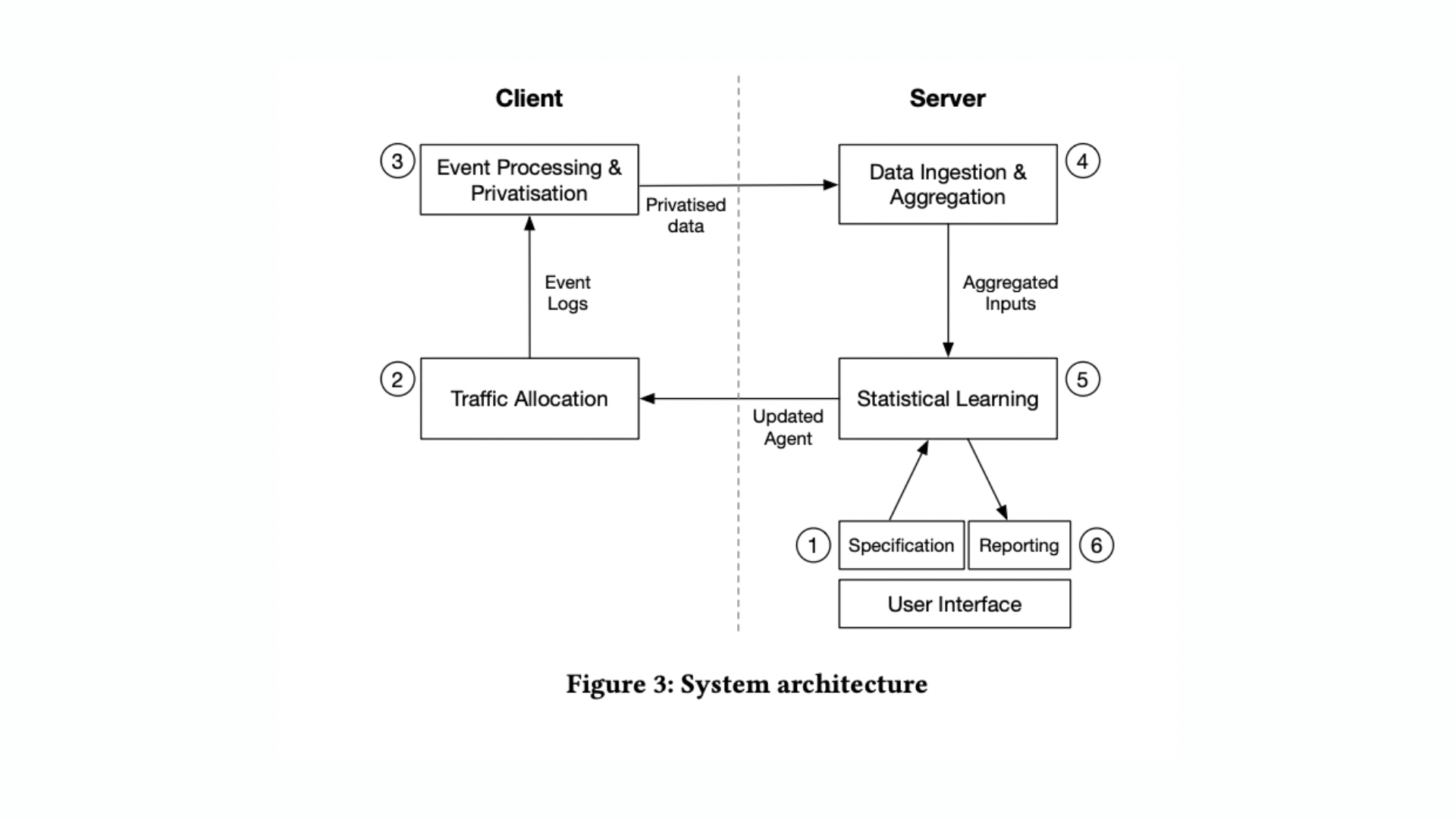
A human operator may control our adaptive Bayesian agent by specifying the desired statistical power, allowing them to interpret the agent’s knowledge and make more successful data-driven business choices. They visualize and show the adaptive behavior of a deployed learning agent. To demonstrate this, they design an overall system architecture that enables real-world optimization implementation at scale.
This Article is written as a summary article by Marktechpost Staff based on the research paper 'Dynamic Memory for Interpretable Sequential Optimisation'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.