UC Berkeley and Google AI Researchers Introduce ‘Director’: a Reinforcement Learning Agent that Learns Hierarchical Behaviors from Pixels by Planning in the Latent Space of a Learned World Model
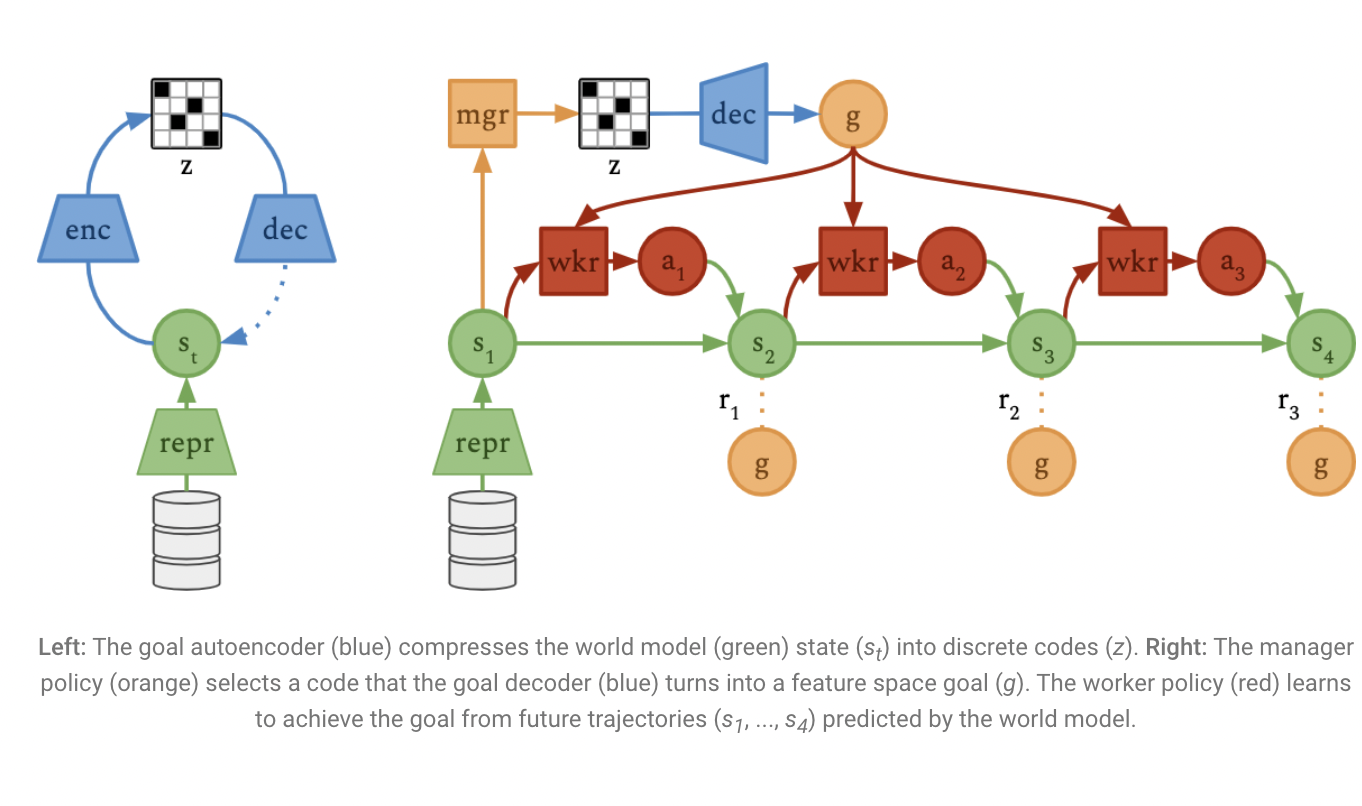

UC Berkeley and Google AI Researchers Introduce ‘Director’: a Reinforcement Learning Agent that Learns Hierarchical Behaviors from Pixels by Planning in the Latent Space of a Learned World Model. The world model Director builds from pixels allows effective planning in a latent space. To anticipate future model states given future actions, the world model first maps pictures to model states. Director optimizes two policies based on the model states’ anticipated trajectories: Every predetermined number of steps, the management selects a new objective, and the employee learns to accomplish the goals using simple activities. The direction would have a difficult control challenge if they had to choose plans directly in the high-dimensional continuous representation space of the world model. To reduce the size of the discrete codes created by the model states, they instead learn a goal autoencoder. The goal autoencoder then transforms the discrete codes into model states and passes them as goals to the worker after the manager has chosen them.
Deep reinforcement learning advancements have accelerated the study of decision-making in artificial agents. Artificial agents may actively affect their environment by moving a robot arm based on camera inputs or clicking a button in a web browser, in contrast to generative ML models like GPT-3 and Imagen. Although artificial intelligence has the potential to aid humans more and more, existing approaches are limited by the necessity for precise feedback in the form of often given rewards to acquire effective techniques. For instance, even robust computers like AlphaGo are restricted to a certain number of moves before earning their next reward while having access to massive computing resources.
Contrarily, complex activities like preparing a meal necessitate decision-making at all levels, from menu planning to following directions to the shop to buy supplies to properly executing the fine motor skills required at each stage along the way based on high-dimensional sensory inputs. Artificial agents can complete tasks more independently with scarce incentives thanks to hierarchical reinforcement learning (HRL), which automatically breaks down complicated tasks into achievable subgoals. Research on HRL has, however, been difficult because there is no universal answer, and existing approaches rely on manually defined target spaces or subtasks.
The Director trains a management policy to suggest subgoals inside the latent space of a learned world model, and a worker policy is trained to carry out these proposals. Despite working with latent representations, they may inspect and analyze Director’s choices by translating its internal subgoals into pictures. They assess the Director using a variety of benchmarks, demonstrating that they can learn various hierarchical techniques and solve problems with very few rewards. Where other methods have failed, such as controlling quadruped robots to navigate 3D mazes directly from first-person pixel inputs.
Free-2 Min AI NewsletterJoin 500,000+ AI Folks
By automatically subdividing complicated long-horizon tasks, the Director learns to do them. Each panel displays the internal objectives decoded on the right and the environment interaction on the left.
Since Director optimizes every component simultaneously, the manager learns to choose objectives the employee can meet. The manager can choose goals that will optimize both the work reward and an exploration bonus, encouraging the agency to investigate and direct their attention to remote areas of the environment. They discovered that a straightforward and efficient exploration bonus favors model states when the target autoencoder experiences significant prediction error. In contrast to other approaches like Feudal Networks, their worker learns solely by maximizing the feature space similarity between the current model state and the objective.
Benchmark Findings
Director operates in an end-to-end RL environment. In contrast to earlier work in HRL that frequently used bespoke assessment methods, such as assuming various practice objectives, accessing the agents’ global position on a 2D map, or using ground-truth distance rewards. They provide the challenging Egocentric Ant Maze benchmark to evaluate the capacity to investigate and resolve long-horizon challenges. In this difficult set of activities, a quadruped robot’s joints must be controlled using solely proprioceptive and first-person camera inputs to locate and attain targets in 3D mazes. The scant reward is only delivered when the robot achieves the objective, forcing the agents to explore independently for most of their learning period because there are no task rewards.
They compare Director against two cutting-edge world model-based algorithms: Plan2Explore, which maximizes task reward and an exploration bonus determined by ensemble disagreement, and Dreamer, which just maximizes task reward. From imagined world model trajectories, both baselines learn non-hierarchical policies. Plan2Explore causes the robot to flip onto its back loudly, preventing it from achieving its goal. Dreamer successfully completes the shortest maze but fails to navigate the longer ones. Director is the only way to locate and consistently reach the destination in these more giant mazes.
They suggest the Visual Pin Pad suite to investigate how agents might find extremely few rewards independently of the difficulty of learning representations of 3D surroundings. In these jobs, the agent moves a black square across the workspace such that it can tread on variously colored pads. Long-term memory is not required because the history of previously activated pads is displayed at the bottom of the screen. The spy must determine how to start each pad to get the little payout. Once more, Director performs far better than the earlier techniques.
Researchers can assess agents using the Visual Pin Pad benchmark even when there are few rewards available and without the interference of problems like long-term memory or the perception of 3D objects.
They examine Director’s performance on various tasks often seen in the literature, which usually do not require lengthy investigation, in addition to completing assignments with little rewards. Their experiment consists of 12 activities, including DMLab maze settings, Control Suite exercises, Atari games, and the Crafter research platform. The fact that the Director completes each of these jobs successfully while using the identical hyperparameters shows how reliable the hierarchy learning process is. Additionally, by giving the worker the job reward, Director may learn the exact motions needed to do the assignment, totally matching or even outperforming the performance of the most advanced Dreamer program.
Visualizing objectives
The learned world model enables translation of the latent model states that Director uses as objectives into visuals that people can understand. To better understand how Director makes decisions, they depict its internal purposes for various contexts. They discover that Director picks up a variety of techniques for decomposing long-horizon tasks. For instance, the management asks for a forward stance and altering floor patterns on the Walker and Humanoid jobs, and the employee fills in the specifics of how the legs should move. The manager in the Egocentric Ant Maze directs the ant robot by requesting a series of various wall colors. The management motivates the worker in DMLab mazes via the teleport motion that takes place soon after collecting the requested object. In contrast, in the 2D research platform Crafter, the manager asks for resource and tool collection via the inventory display at the bottom of the screen.

In Egocentric Ant Maze XL, the manager guides the employee through the maze by aiming at various colored walls. Right: In Visual Pin Pad Six, the manager designates subgoals by highlighting several pads and using the history display at the bottom.
In Walker, the manager asks the employee to assume a forward-leaning position with both feet off the ground and a moving floor pattern. The employee then fills in the specifics of the leg movement. Right: Director learns to get up and walk steadily from pixels without early episode terminations in the difficult Humanoid assignment.
Upcoming Directions
They consider Director to be a development in HRL research and are almost ready to share its source code. The research community can use Director as a helpful starting point for developing hierarchical artificial agents in the future by allowing goals to only correspond to portions of the entire representation vectors, learning the duration of the goals dynamically, and creating hierarchical agents with three or more levels of temporal abstraction. We are confident that following algorithmic developments in HRL will enable intelligent agents to operate at unprecedented levels of performance and autonomy.
This Article is written as a summary article by Marktechpost Staff based on the research paper 'Deep Hierarchical Planning from Pixels'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper and project. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.