Meet Intel® Neural Compressor: An Open-Source Python Library for Model Compression that Reduces the Model Size and Increases the Speed of Deep Learning Inference for Deployment on CPUs or GPUs
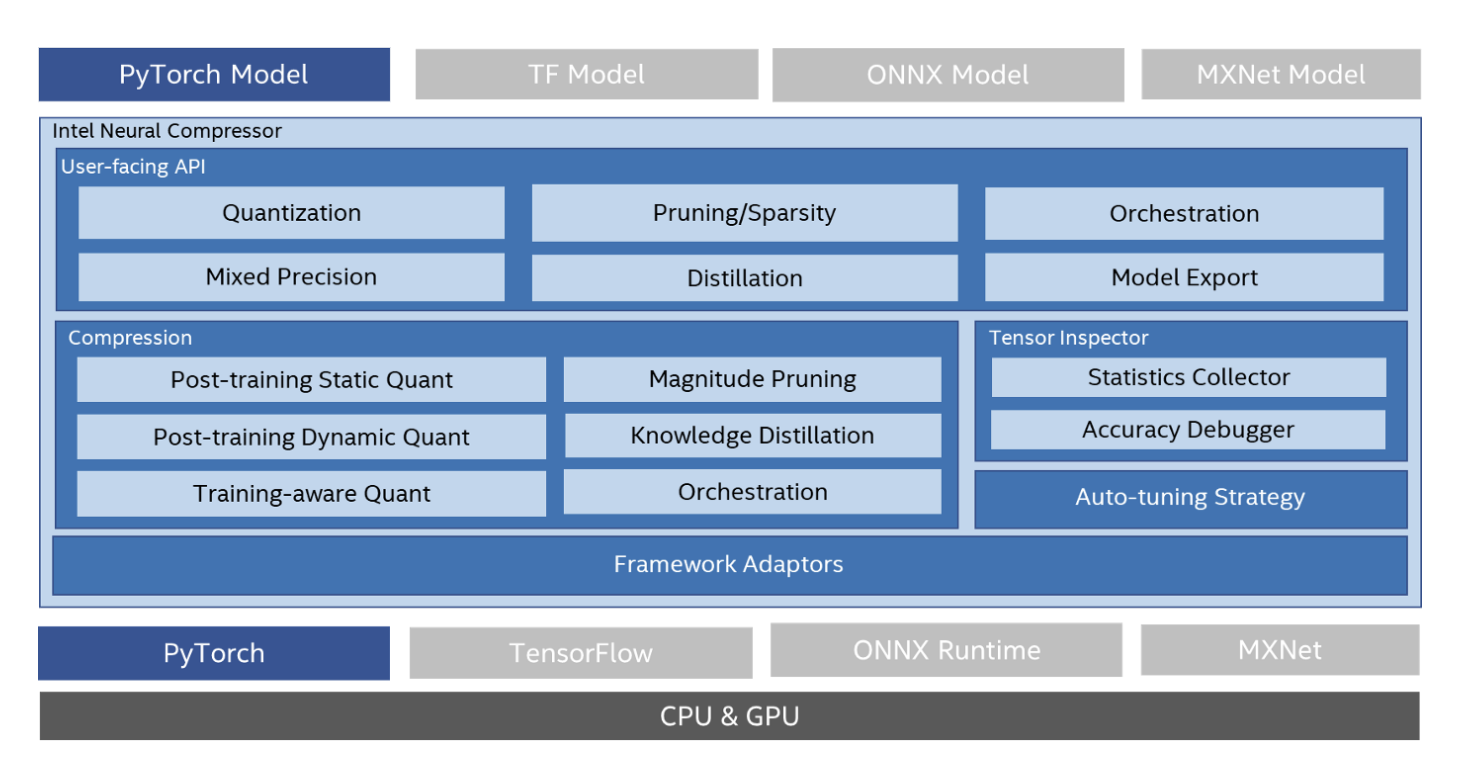

Intel has recently released Neural Compressor, an open-source Python package for model compression. This library can be applied to deep learning deployment on CPUs or GPUs to decrease the model size and speed up inference. Additionally, it offers a uniform user interface for well-known network compression techniques, including quantization, pruning, and knowledge distillation across various deep learning frameworks. The tool’s automatic accuracy-driven tweaking technique can be utilized to generate the best-quantized model. Additionally, it allows knowledge distillation so that the knowledge from the teacher model may be transferred to the student model. It implements several weight pruning methods to produce pruned models using a predetermined sparsity goal. For improved framework interoperability, the Python library also offers APIs for various deep learning frameworks, including TensorFlow, PyTorch, and MXNet.
In order to allow fine-grained quantization granularity from the model level to the operator level, the library’s quantization functionality builds upon the standard PyTorch quantization API and makes its changes. Intel Neural Compressor expands PyTorch quantization by offering sophisticated recipes for quantization, automatic mixed precision, and accuracy-aware tweaking. It accepts a PyTorch model as input and produces an ideal model in response. With this method, users can improve accuracy without making any additional hand-tuning effort. The Neural Compressor also features an automatic accuracy-aware adjustment method for increased quantization productivity. The tool searches the framework in the first stage for several quantization capabilities, including quantization granularity, scheme, data type, and calibration approach. The supported data types for each operator are then questioned. The tool uses these inquired capabilities to produce a vast tuning space of various quantization configurations and begins the tuning rounds. It carries out the calibration, quantization, and evaluation for each set of quantization configurations. The tool stops adjusting when the evaluation reaches the accuracy objective and creates a quantized model.
Unstructured and structured weight pruning and filter pruning are the keys focuses of Intel’s Neural Compressor’s pruning functionality. When the magnitude of the weights falls below a set threshold during training, the weights are pruned using the unstructured pruning procedure. To improve the efficiency of the sparsity model, structured pruning incorporates experimental tile-wise sparsity kernels. The NLP model’s head, intermediate layers, and hidden states are pruned based on the importance score determined by the gradient using a pruning algorithm called filter pruning, which also includes gradient-sensitivity pruning. To transmit knowledge from a larger “teacher” model to a smaller “student” model without losing validity, the Intel Neural Compressor also uses a knowledge distillation technique.
In order to increase productivity and address the problems associated with accuracy loss while using popular neural network compression techniques, Intel launched Neural Compressor. Neural Compressor has an easy-to-use API and an auto-tuning mechanism. The team is constantly working to improve the tool by including more compression formulas and fusing these methods to create ideal models. Additionally, the team solicits open-source community input and encourages people to contribute to the Python package. The Github repo for the library can be accessed here.
Free-2 Min AI NewsletterJoin 500,000+ AI Folks
References:
- https://www.intel.com/content/www/us/en/developer/tools/oneapi/neural-compressor.html
- https://medium.com/pytorch/pytorch-inference-acceleration-with-intel-neural-compressor-842ef4210d7d
Credit: Source link
Comments are closed.