Baidu AI Research Releases PLATO-XL: World’s First Dialogue Generation (NLP) Model Pre-Trained On 11 Billion Parameter

Artificial intelligence (AI) applications have a significant impact on our daily lives, making them easier. One of such applications is AI bots that are already proven effective in the automation of day-to-day tasks. These bots gather data and even imitate real-time human discussions, allowing humans to focus on more strategic activities.
However, having clear, informative, and engaging conversations in the same manner that humans do is difficult for AI bots. Robots must build high-quality open-domain dialogue systems if they are to serve as emotional companions or intelligent assistants. As pretraining technology improves models’ ability to learn from vast amounts of unannotated data, mainstream research concentrates on making better use of massive data to improve open-domain discussion systems.
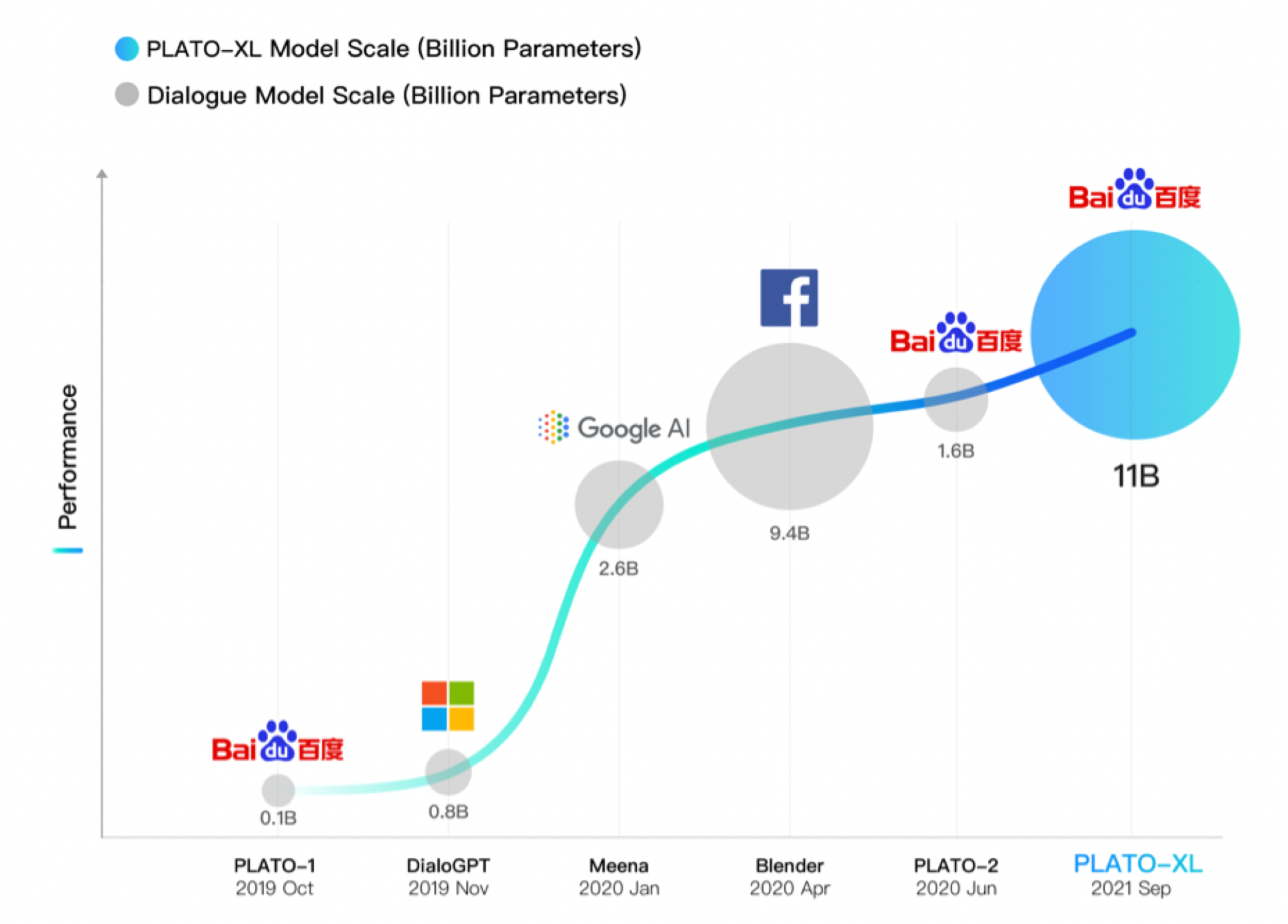
From Google’s Meena and Facebook’s Blender to Baidu’s PLATO, there has been a significant advancement in the field of open-domain communication in recent years. Baidu achieves new accomplishments in Chinese and English conversations with PLATO-XL, which now becomes the world’s largest Chinese and English dialogue generation model, pretrained on 11 billion parameters.
PLATO-XL’s Architecture
PLATO-XL is based on a unified transformer design that enables simultaneous modelling of dialogue comprehension and response production, saving time and money. The team used a variable self-attention mask technique to enable Bidirectional encoding of dialogue history and unidirectional decoding of responses.
According to researchers, the unified transformer architecture is effective in conversation generating training. Variable lengths of conversation samples in the training process have been shown to result in a significant number of incorrect computations. Through excellent sorting of the input samples, the unified transformer considerably improves training efficiency.
The majority of the pretraining data used is gathered from social media, where multiple users exchange ideas. The learned models tend to combine information from multiple participants in the context, making it difficult to generate consistent responses.
To address this issue, the team introduces multi-party aware pretraining, which assists the model in distinguishing information in context and maintaining consistency in dialogue generation. PLATO-XL undertakes multi-party aware pretraining to mitigate the inconsistency problem in multi-turn conversations. The proposed model has 11 billion parameters and two dialogue models, one for Chinese and one for English. For pretraining, 100 billion data tokens were used.

PLATOXL is implemented on PaddlePaddle, a deep learning platform developed by Baidu. The model employs gradient checkpoint and sharded data parallelism offered by FleetX, PaddlePaddle’s distributed training library to train large models. Furthermore, It is trained on 256 Nvidia Tesla V100 32G GPU cards in a high-performance GPU cluster.
PLATO-XL was compared to other open-source Chinese and English dialogue models for the complete evaluation. The results demonstrate that PLATO-XL performs significantly better than Blender, DialoGPT, EVA, PLATO-2, etc. In addition, PLATO-XL outperforms the existing mainstream commercial chatbots with a wide margin.

PLATO-XL actively supports knowledge grounded dialogue and task-oriented conversation with excellent performance. Additionally, it can have logical, informative, and engaging multi-turn conversations with users in English and Chinese.
The PLATO series includes dialogue models with parameters ranging from 93M to 11B. The researchers suggest that the influence of increasing model size on model performance is significant.

Dialogue generating models have some shortcomings, such as unfair biases, incorrect information, and the inability to learn continuously, to name a few. But Baidu’s PLATO-XL opens up new possibilities in open-domain dialogues, one of natural language processing’s most difficult tasks. PLATO-XL is the world’s largest pretraining model for Chinese and English conversation, bringing AI closer to a future of human-like learning and conversing abilities. The team plans to improve the quality of the conversation in terms of fairness and factuality.
Paper: https://arxiv.org/abs/2109.09519
Github: https://github.com/PaddlePaddle/Knover
Source: http://research.baidu.com/Blog/index-view?id=163
Suggested
Credit: Source link
Comments are closed.