Researchers from Bytedance and Dalian University Propose ‘Unicorn’: a Unified Computer Vision Approach to Address Four Tracking Tasks Using a Single Model with the Same Model Parameters
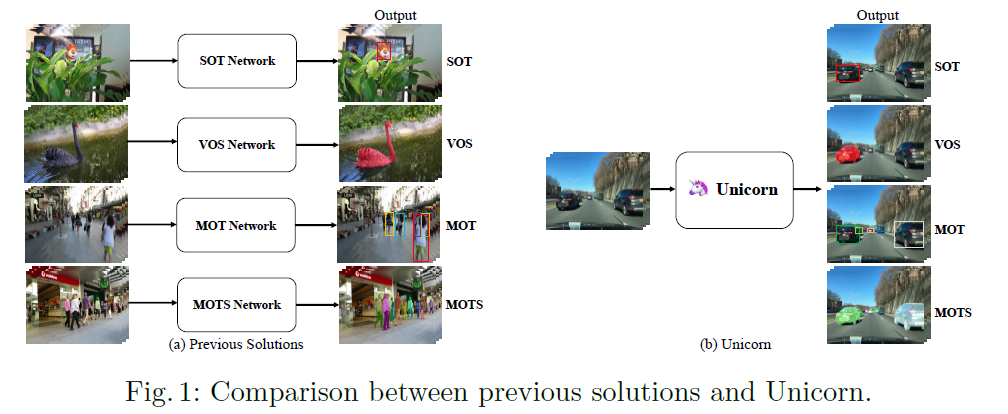
Object tracking is one of the core applications in the field of computer vision. It constructs pixel-level or instance-level connections amongst frames and produces trajectories in the form of boxes (masks). There are four primary categories of object tracking that include: Single Object Tracking (SOT); Video Object Segmentation (VOS); Multiple Object Tracking (MOT); Multi-Object Tracking and Segmentation (MOTS). Most of the applications solve only one category of tracking. A unified model is required to handle all the categories of tracking simultaneously.
This work proposes two core parts to resolve this issue: the pixel-wise correspondence and the target prior. The pixel-wise correspondence represents the resemblance between all pairs of points from the reference and the current frames. The target prior acts as a switch amongst four tracking categories and is an extra input for the detection head. This study introduces Unicorn, a single network architecture that addresses the problem of tracking four categories in parallel.
The contributions of this work include 1) For four categories of tracking, Unicorn successfully unifies the learning paradigm and network architecture. 2) It fills the gap between the pixel-wise correspondence and target prior approaches for all four categories of tracking. 3) Unicorn presents cutting-edge performance on eight severe tracking benchmarks using the same model parameters. The comparison between Unicorn and task-specific techniques is showcased in Figure 1.
This work proposes Unicorn, a unified approach for object tracking comprised of three major components: unified inputs and backbone, united embedding, and unified head. Unicorn’s unified network forecasts the states of the monitored targets on the current frame utilizing the current frame, the reference frame, and reference targets. The architecture of the proposed Unicorn approach is showcased in Figure 2.
The proposed Unicorn approach selects the whole image as an input. The current and the reference frames are fed through a weight-sharing backbone to obtain Feature Pyramid Representations (FPN). In Unicorn, pixel-wise correspondence is calculated by multiplying the spatially flattened reference frame embedding by the current frame embedding. The transformer is selected to improve the representation of the original feature as it can capture long-range dependencies. End-to-end optimization of the unified embedding is performed using Dice Loss for SOT and VOS or Cross-Entropy Loss for MOT and MOTS. Unicorn adds an additional input to detect any target in the reference frame. Given the reference target map, the propagated target map can offer reliable prior knowledge about the state of the tracked target, which proves the significance of utilizing target prior. The target previous and the original FPN feature are the inputs utilized by the unified head. These two inputs are combined by Unicorn using a broadcast sum, and the integrated feature is then sent back to the initial detection head.
Training is partitioned into two parts. Using data from SOT&MOT, the network is first end-to-end fine-tuned for detection and correspondence loss. The addition and optimization of a mask branch with the mask loss are performed in the second stage utilizing data from VOS & MOTS while keeping other parameters constant. In the testing phase, Unicorn chooses the box or mask with the maximum assurance score as the final tracking outcome without performing hyperparameter-sensitive post-processing, such as a cosine window.
The proposed approach is compared with ConvNeXt-Large, ConvNeXt-Tiny, and ResNet-50. The dimension of an input image is 800 x 1280 pixels. 16 NVIDIA Tesla A100 GPUs are used to train the model, with a 32 global batch size. There are 200,000 pairs of frames in each of the 15 epochs that make up an individual training stage.
LaSOT and TrackingNet datasets are utilized to evaluate performance on SOT. Precision, success, and normalized precision are used to assess the performance of the proposed approach. MOT17 and BDD100K datasets are utilized to evaluate the performance of MOT. Multi-Object Tracking Accuracy (MOTA), Identity F1 Score (IDF1), the percentage of mostly tracked trajectories (MT), False Negatives (FN), False Positives (FP), Mostly lost trajectories (ML), and Identity Switches (IDS) are utilized to evaluate the performance of MOT. VOS is evaluated on DAVIS 2016 and 2017 datasets. Region similarity, contour accuracy, and an average of both are used as evaluation parameters for VOT. MOTS20 and BDD100K are utilized to evaluate the performance of MOTS utilizing sMOTSA and mMOTSA and other parameters utilized in MOT. To perform ablation analysis, ConvNeXt-Tiny is used.
Hence, this paper introduces Unicorn, a coordinated strategy with the same model parameters to handle tracking categories. The suggested model outperforms other category-specific approaches on eight severe benchmarks.
This Article is written as a summary article by Marktechpost Staff based on the research paper 'Towards Grand Unification of Object Tracking'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper and github link. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.