Alibaba AI Research Team Introduces ‘DCT-Net’; A Novel Image Translation Architecture For Few-Shot Portrait Stylization

Portrait stylization aims to transform a person’s appearance into more creative visual styles (e.g., 3D-cartoon, anime, and hand-drawn) while maintaining personal identity. This research topic has many applications in the digital arts, like art creations, animation making, and virtual avatar generation. Unfortunately, creating these artistic artifacts requires specific creative skills and intense human efforts.
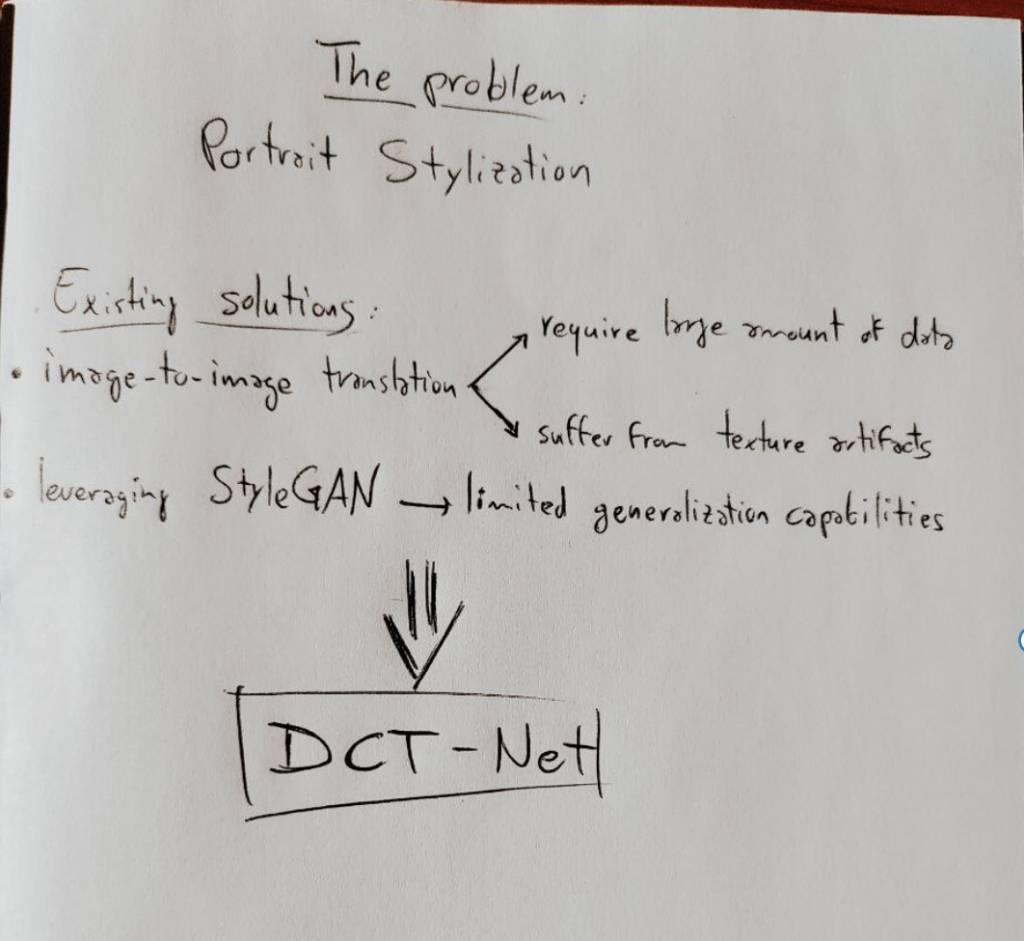
In the scientific literature, two main methods have been considered to automatically transform the visual style of a person’s picture. Image-to-image translation techniques automatically learn a function that maps an input image from the source domain to a target domain. However, these methods require huge amounts of data and suffer from texture artifacts when the input picture scene is complex. On the other hand, most recent works rely on the pre-trained StyleGAN to achieve portrait stylization but with limited generalization capabilities. Moreover, both these existing methods just focus on head images and cannot handle full-body pictures.
For these reasons, a research team of the Alibaba DAMO Academy recently proposed DCT-Net, a novel image translation architecture for few-shot portrait stylization. As shown in Figure 1, given limited style examples (∼100), DCT-Net produces high-quality style transfer results in different styles, even considering full-body images.

The goal of the DCT-Net framework is to learn a function that maps the images of the source domain into the target domain. The image generated by the framework should present a texture style of the target domain while keeping the content details of the source image. Figure 3 depicts an overview of DCT-Net, which consists of a sequential pipeline of three modules: Content Calibration Network (CCN), Geometry Expansion Module (GEM), and Texture Translation Network (TTN).
Thanks to transfer learning, the CCN calibrates the target domain distribution based on a generator model trained on source domain images. To support the generation of full-body images, the GEM applies geometry transformations to the samples of both source and target domains. Finally, the TTN learns how to generate the cross-domain translation. During the training process, the CCN and the TTN are trained independently. Moreover, DCT-Net only relies on the TTN for its final inferences after the training process.
Content Calibration Network (CCN)
The goal of the CCN is to calibrate the distribution of the few target domain samples based on the parameters of a network trained on source domain examples. This process is achieved through transfer learning. As it is possible to see in Figure 4, the authors rely on Gs, a StyleGAN2-based model trained on source domain samples (i.e., pictures of real faces from the FFHQ dataset). On the other hand, the model Gt is initialized as a copy of Gs and then adapted to generate images in the target domain. This adaptation is achieved during the training process of the CCN by fine-tuning Gt through a discriminator model Dt ensuring that the outputs of Gt belong to the target domain. At the same time, an existing face recognition model called Rid is added to the framework to preserve person identity between source and target domains. During the inference process of the CCN, instead, the first k layers of the two generators Gs and Gt are blended in order to better preserve the content of the source domain images.
Geometry Expansion Module (GEM)
As previously described, the CCN module relies on the FFHQ dataset as the source domain. However, this dataset only includes images that have been aligned with the standard facial position. This would limit the framework generalization capabilities. To mitigate this issue and to support the inference of full-body images, the GEM applies geometry transformations to both source and target samples. These transformations involve the application of a random scale ratio and an arbitrary rotation angle to the considered images.
Texture Translation Network (TTN)
Thanks to the CCN, the authors obtained a global mapping between source and target domains. However, this does not ensure the preservation of local content details. For this reason, the TTN (whose architecture is shown in Figure 5) introduces a mapping network Ms🡪t that learns how to convert the global domain mapping into a pixel-level texture translation.
Given an input image from the source domain xs, a target domain sample xt, and the generated image xg, DCT-Net extracts the style representation Fsty of xt and xg through texture and surface decompositions. Then, a discriminator Ds guides Ms🡪t in generating xg with the same style as xt. A style loss function penalizes the distance between the style representation distributions of xt and xg.
At the same time, the pre-trained VGG16 network extracts the content representations Fcon from both xs and xg. Hence, to ensure content consistency, the authors rely on a content loss function, computed as the distance between xs and xg in the feature space considered by the VGG16 network.
Finally, to encourage the generation of excessive deformations like simplified mouths and big eyes, the authors added an expression regressor Rexp that forces the framework to pay more attention to the regions of facial components like the mouth and the eyes of the image subject.

In Figure 7, there are other examples generated through DCT-Net. These examples show how the proposed framework is able to preserve detailed contents and complex scenes.
This Article is written as a summary article by Marktechpost Research Staff based on the research paper 'DCT-Net: Domain-Calibrated Translation for Portrait Stylization'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper, project and github link. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.