Researchers from DeepMind and University College London Propose Stochastic MuZero for Stochastic Model Learning
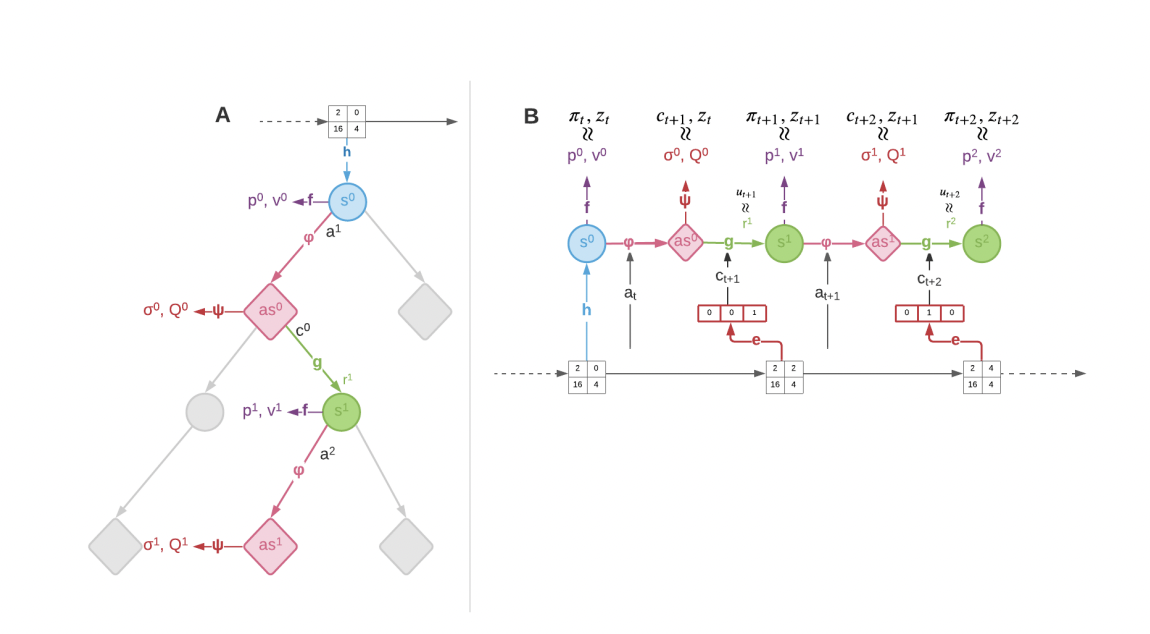

Recent research has shown that model-based reinforcement learning is incredibly effective. However, learning a model separately from using it during planning can be challenging in complicated contexts. The most efficient strategies to combat this have instead coupled value-equivalent model learning with powerful tree-search techniques. This strategy is demonstrated by the model-based reinforcement learning agent MuZero. In the past, this agent has demonstrated cutting-edge performance in various fields, from board games to landscapes with plenty of visual detail. However, earlier implementations of this strategy were restricted to the application of deterministic models. This restricts their ability to function in settings that are inherently stochastic, partially observable, or so big and complicated that a finite agent perceives them as stochastic. In their most recent article, a research team from DeepMind and University College London introduced a novel stochastic model learning technique called Stochastic MuZero. The revolutionary methodology maintains the original MuZero’s superhuman performance in deterministic contexts like the game of Go while achieving performance comparable to or better than state-of-the-art solutions in complicated single- and multi-agent environments. To represent the dynamics of stochastic environments, stochastic MuZero combines a learned stochastic transition model of the environment dynamics with a Monte Carlo tree search form. Stochastic MuZero uses afterstates which can be defined as the hypothetical state of an environment after an action is applied but before the environment has transitioned to an actual state, to capture the stochastic dynamics. Stochastic MuZero, in contrast to MuZero, solely uses latent states to describe actual environmental states.
The first function in the Stochastic MuZero algorithm is a representation function that converts the current observation to a latent state. The second function represents a dynamic afterstate function that generates the subsequent latent afterstate. The other functions include a prediction function that generates value and policy predictions, a reward prediction, and a dynamics function that determines the subsequent latent state. The final function produces a value prediction and a distribution of potential future chance events. It is an afterstate prediction function. By using chance nodes and chance values in the search, stochastic MuZero additionally expands the capabilities of the Monte Carlo Tree Search algorithm. Querying the stochastic model allows each chance node to be enlarged to represent a latent afterstate. The tree is then backpropagated up using this expanded value. Finally, a code is chosen from the prior distribution when the node is traversed during the selection phase. Thus, the Stochastic MuZero search can be successfully used in stochastic settings. The team tested Stochastic MuZero in their empirical research against a wide range of difficult stochastic and deterministic situations, such as the traditional 2048 puzzle game, Backgammon, and the game of Go. The results demonstrate that Stochastic MuZero significantly outperforms MuZero in stochastic environments and achieves comparable or better performance than AlphaZero. It also matches or exceeds existing methods that use a perfect stochastic simulator without requiring prior knowledge of the environment.
This Article is written as a summary article by Marktechpost Staff based on the research paper 'PLANNING IN STOCHASTIC ENVIRONMENTS WITH A LEARNED MODEL'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.