University of Michigan Researchers Open-Source ‘FedScale’: a Federated Learning (FL) Benchmarking Suite with Realistic Datasets and a Scalable Runtime to Enable Reproducible FL Research on Privacy-Preserving Machine Learning
Federated learning (FL) is a new machine learning (ML) environment in which a logically centralized coordinator orchestrates numerous dispersed clients (e.g., cellphones or laptops) to train or assess a model collectively. It enables model training and assessment of end-user data while avoiding significant costs and privacy hazards associated with acquiring raw data from customers, with applications spanning a wide range of ML jobs. Existing work has focused on improving critical features of FL in the context of varied execution speeds of client devices and non-IID data distributions.
A thorough benchmark for evaluating an FL solution must study its behavior in a practical FL scenario with (1) data heterogeneity and (2) device heterogeneity under (3) heterogeneous connectivity and (4) availability conditions at (5) many scales on a (6) wide range of ML tasks. While the first two elements are frequently cited in the literature, real network connections and client device availability might impact both forms of heterogeneity, impeding model convergence. Similarly, large-scale assessment can reveal an algorithm’s resilience since actual FL deployment frequently involves thousands of concurrent participants out of millions of customers.
Overlooking just one component can cause the FL assessment to be skewed. Regrettably, established FL benchmarks frequently fall short across numerous dimensions. For starters, they have restricted data flexibility for many real-world FL applications. Even though they have many datasets and FL training objectives (e.g., LEAF, their datasets frequently comprise synthetically created partitions derived from conventional datasets (e.g., CIFAR) and do not represent realistic features. This is because these benchmarks are primarily based on classic ML benchmarks (e.g., MLPerf or are built for simulated FL systems such as TensorFlow Federated or PySyft.
Second, existing benchmarks frequently ignore system performance, connection, and client availability (e.g., FedML and Flower). This inhibits FL attempts from considering system efficiency, resulting in unduly optimistic statistical performance. Third, their datasets are predominantly small-scale because their experimental setups cannot simulate large-scale FL deployments. While real FL frequently involves thousands of participants in each training cycle, most available benchmarking platforms can only train tens of participants each round.
Finally, most of them lack user-friendly APIs for automatic integration, necessitating significant technical work for large-scale benchmarking. To facilitate complete and consistent FL assessments, we present FedScale, an FL benchmark and supporting runtime: • FedScale, to the best of our knowledge, has the most comprehensive collection of FL datasets for examining various elements of practical FL installations. It presently has 20 actual FL datasets with small, medium, and large sizes for a wide range of task categories, including image classification, object identification, word prediction, speech recognition, and reinforcement learning.
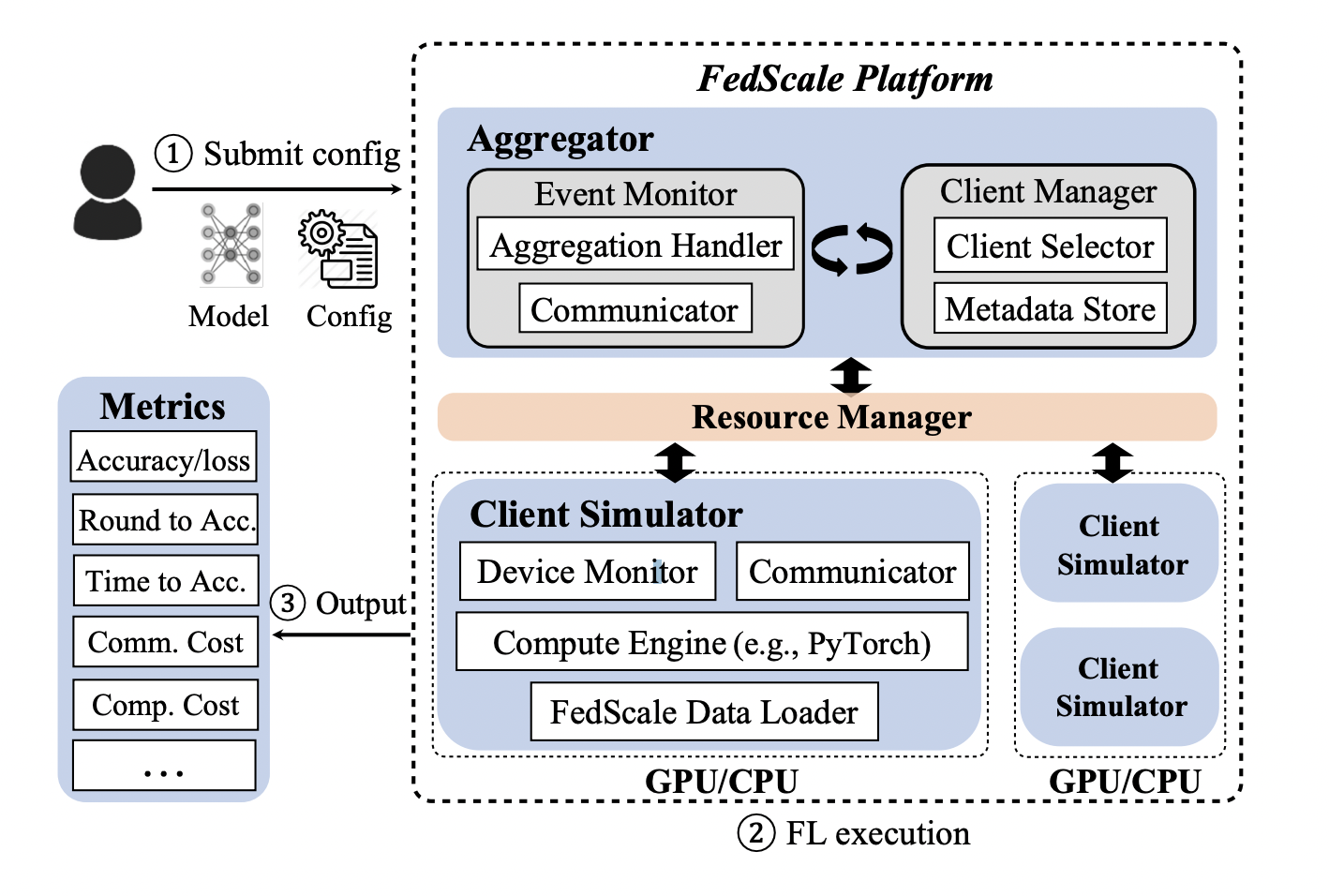
FedScale Runtime to standardize and simplify FL assessment in more realistic conditions. FedScale Runtime includes a mobile backend for on-device FL assessment and a cluster backend for benchmarking different practical FL metrics (for example, actual client round length) on GPUs/CPUs using accurate FL statistical and system information. The cluster backend can efficiently train thousands of clients on a small number of GPUs in each cycle. FedScale Runtime is also extendable, allowing for the quick implementation of new algorithms and concepts through flexible APIs. Researchers conducted systematic tests to demonstrate how FedScale enables thorough FL benchmarking and highlight the critical requirement for co-optimizing system and statistical efficiency, particularly in dealing with system stragglers, accuracy bias, and device energy trade-offs.
FedScale (fedscale.ai) provides high-level APIs for implementing FL algorithms, deploying, and evaluating them at scale across various hardware and software backends. FedScale also features the most comprehensive FL benchmark, including FL tasks from image classification and object identification to language modeling and speech recognition. Furthermore, it delivers datasets that properly simulate FL training scenarios where FL will be applied practically. The best feature is its open source, and the code is freely available on Github.
This Article is written as a summary article by Marktechpost Staff based on the research paper 'FedScale: Benchmarking Model and System Performance of Federated Learning at Scale'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper, github link and reference article. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.