Amazon AI Research Presents A Formal Method To Locate Root Causes Of Outliers
Rare observations where a system deviates from its typical behavior are known as outliers. They appear in numerous real-world applications (such as medicine and finance) and necessitate more explanation than regular occurrences. Outliers in the training dataset can cause problems during a model fitting in machine learning (esp., linear models). It may also result in inflated error metrics that give larger errors more weight. As a result, it is necessary to treat outliers and determine their root cause before developing a machine learning model.
Over the years, there has been a lot of research on outlier detection. Yet, there is no precise definition of the “root causes” of outliers.
A new Amazon research presents a study on locating the underlying causes of outliers. Each of the underlying causes of an observed outlier’s quantitative causal contribution is formalized in their definition of an observed outlier. In other words, the contribution identifies how much a certain variable contributed to the outlier event. This also connects to philosophical issues; philosophers continue to discuss whether an event is a “real cause” of others, even if it is merely qualitative.
Their strategy is built on graphical causal models representing cause-and-effect interactions between system variables. It has two essential components.
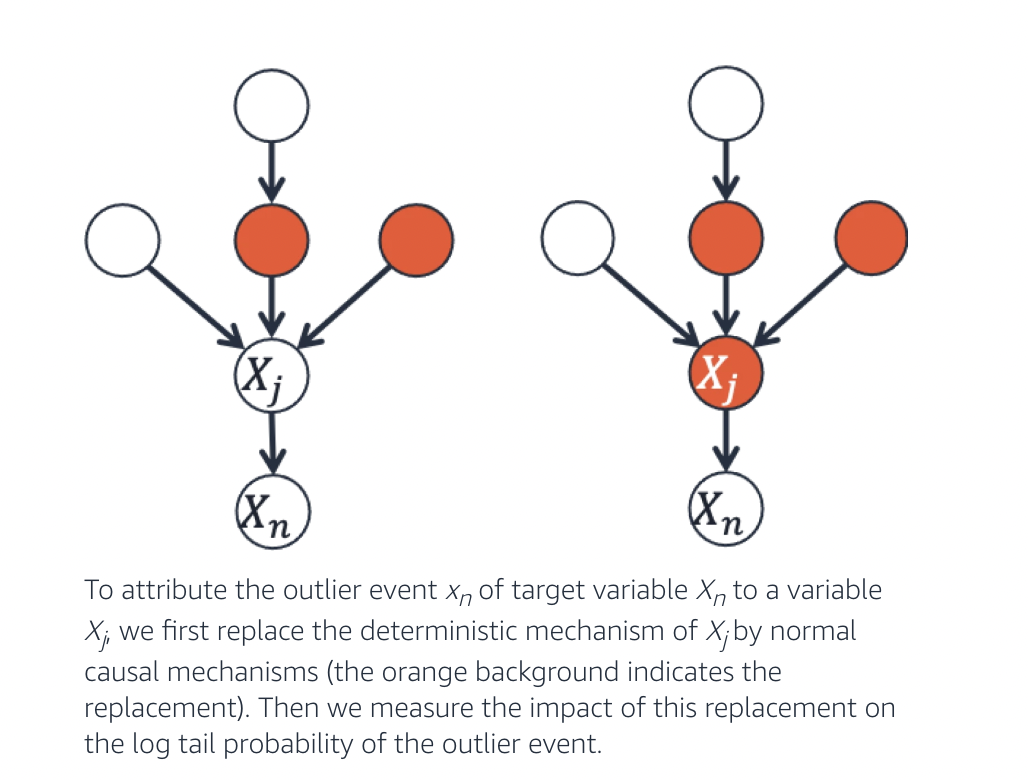
- A causal diagram that graphically illustrates the cause-and-effect links between the observed variables. It does this by using arrows to connect the nodes that indicate the causes and effects.
- Set of causal mechanisms that explain how each node in the causal diagram derives its values from the values of its parents or direct causes.
There are numerous algorithms for detecting outliers. They first developed an information-theoretic (IT) outlier score, which probabilistically calibrates current outlier scores to discover the underlying causes of outliers detected by one of these approaches.
The team’s outlier score is based on the idea of tail probability, which is the likelihood that a random variable would exceed a predetermined value. The negative logarithm of the event’s tail probability after some modification is the IT outlier score for that event. As mentioned in their paper, “Causal structure-based root cause analysis of outliers,” it draws inspiration from Claude Shannon’s information theory notion of the information content of a random event.
The more information an event carries, and the higher its IT outlier score, the less likely it is to be followed by events more extreme than the one in question. Thanks to probabilistic calibration, IT outlier scores are comparable across variables with differing dimensions, ranges, and scales.
The researchers pose the hypothetical question, “Would the event not have been an outlier had the causal mechanism of that variable been normal?” to link the outlier event to a particular variable. Since the counterfactuals constitute the third step in Pearl’s ladder of causation, functional causal models (FCMs) are needed to explain how variables cause them.
The researchers state that further study is necessary to conduct a systematic theoretical investigation of this method’s robustness to violated assumptions because it is based on causal assumptions.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Causal structure-based root cause analysis of outliers'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper and amazon article. Please Don't Forget To Join Our ML Subreddit
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.