Google AI’s New Study Enhance Reinforcement Learning (RL) Agent’s Generalization In Unseen Tasks Using Contrastive Behavioral Similarity Embeddings

Reinforcement learning (RL) is a field of machine learning (ML) that involves training ML models to make a sequence of intelligent decisions to complete a task (such as robotic locomotion, playing video games, and more) in an uncertain, potentially complex environment.
RL agents have shown promising results in various complex tasks. However, it is challenging to transfer the agents’ capabilities to new tasks even when they are semantically equivalent. Consider a jumping task in which an agent, learning from image observations, must jump over an obstacle. Deep RL agents who have been taught a handful of these tasks with varied obstacle positions find it difficult to jump over obstacles in previously unknown locations.

Source: https://ai.googleblog.com/2021/09/improving-generalization-in.html
A new Google research improves the agent’s generalization in unseen tasks by incorporating the inherent sequential structure in Reinforcement learning (RL) into the representation learning process. This is in contrast to earlier methods, which were often derived from supervised learning and, and as a result, primarily overlook the sequential aspect. The novel method takes advantage of the fact that an agent exhibits at least short sequences of actions comparable across tasks with similar underlying mechanics.
Contrastive Behavioral Similarity Embeddings for Generalization in Reinforcement Learning
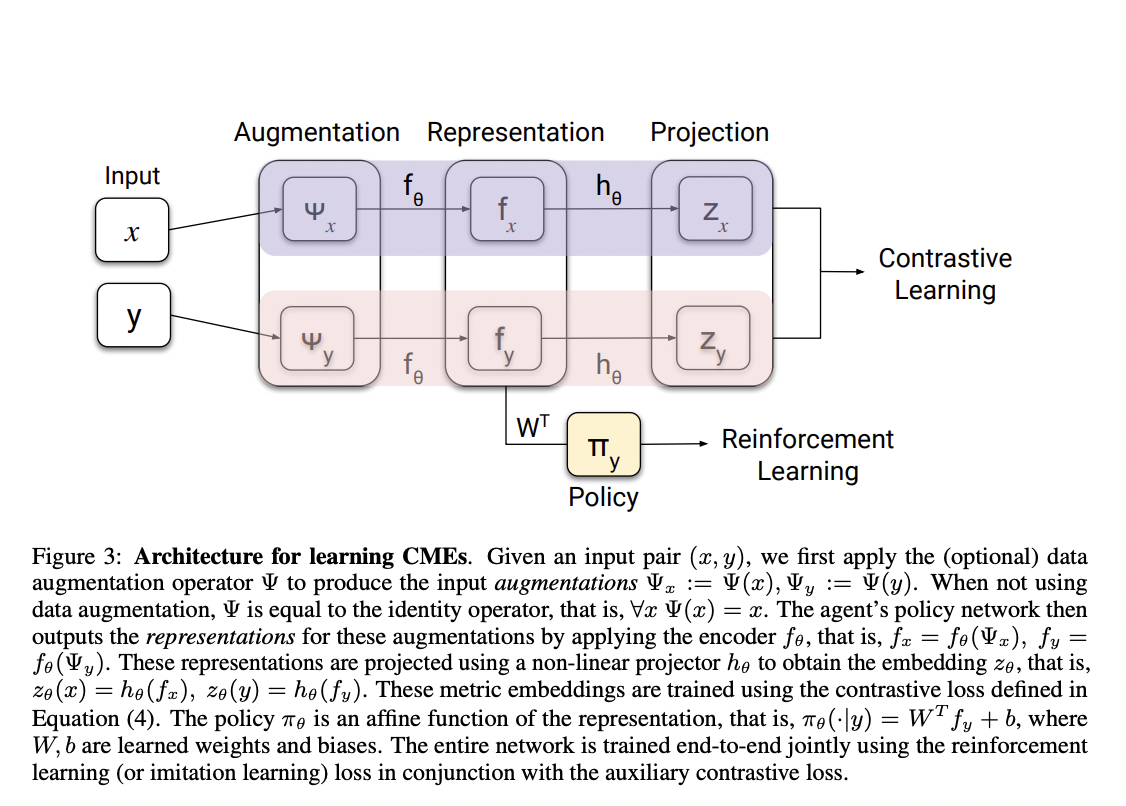
The team trains the agent to learn representations in which states are close when the agent’s best behavior in these states and future states are comparable. This concept of proximity, dubbed “behavioral similarity” by the researchers, can be applied to findings from various tasks. They propose a policy similarity metric (PSM), a theoretically driven state-similarity metric inspired by bisimulation, to assess the behavioral similarity between states across multiple tasks (e.g., different obstacle placements in the leaping task).

Source: https://ai.googleblog.com/2021/09/improving-generalization-in.html
The new method improves generalization by learning state embeddings. State embeddings are neural-network-based representations of task states that bring behaviorally similar states together while pushing behaviorally dissimilar ones apart. To that end, they introduce contrastive metric embeddings (CMEs), which use contrastive learning to learn representations based on a state-similarity metric.
They represent contrastive embeddings with the policy similarity metric (PSM) to learn policy similarity embeddings (PSEs). PSEs assign comparable representations to states that behave similarly in both those and future states.
The findings imply that PSEs significantly improve generalization on the previously mentioned jumping task from pixels, outperforming previous techniques.


Furthermore, the team projects the representations learned by PSEs and baseline methods to 2D points with UMAP to visualize the high dimensional data. Unlike other techniques, the results reveal that PSEs cluster behaviorally similar states together and dissimilar states apart. PSEs also divide the states into two groups: (1) all states prior to the jump, and (2) states where actions have no effect on the result (states after the jump).

This research demonstrates the advantages of using RL’s intrinsic structure to learn good representations. Finding new ways to define behavior similarity and utilizing this structure for representation learning are exciting directions for future research.
Paper: https://arxiv.org/pdf/2101.05265.pdf
Project: https://agarwl.github.io/pse/
Github: https://github.com/google-research/google-research/tree/master/pse
Slides: https://agarwl.github.io/pse/pdfs/slides.pdf
Source: https://ai.googleblog.com/2021/09/improving-generalization-in.html
Suggested
Credit: Source link
Comments are closed.