Researchers at Meta AI Create ‘OMNI3D’ Dataset For Object Recognition And ‘Cube R-CNN’ Model That Generalizes To Unseen Images
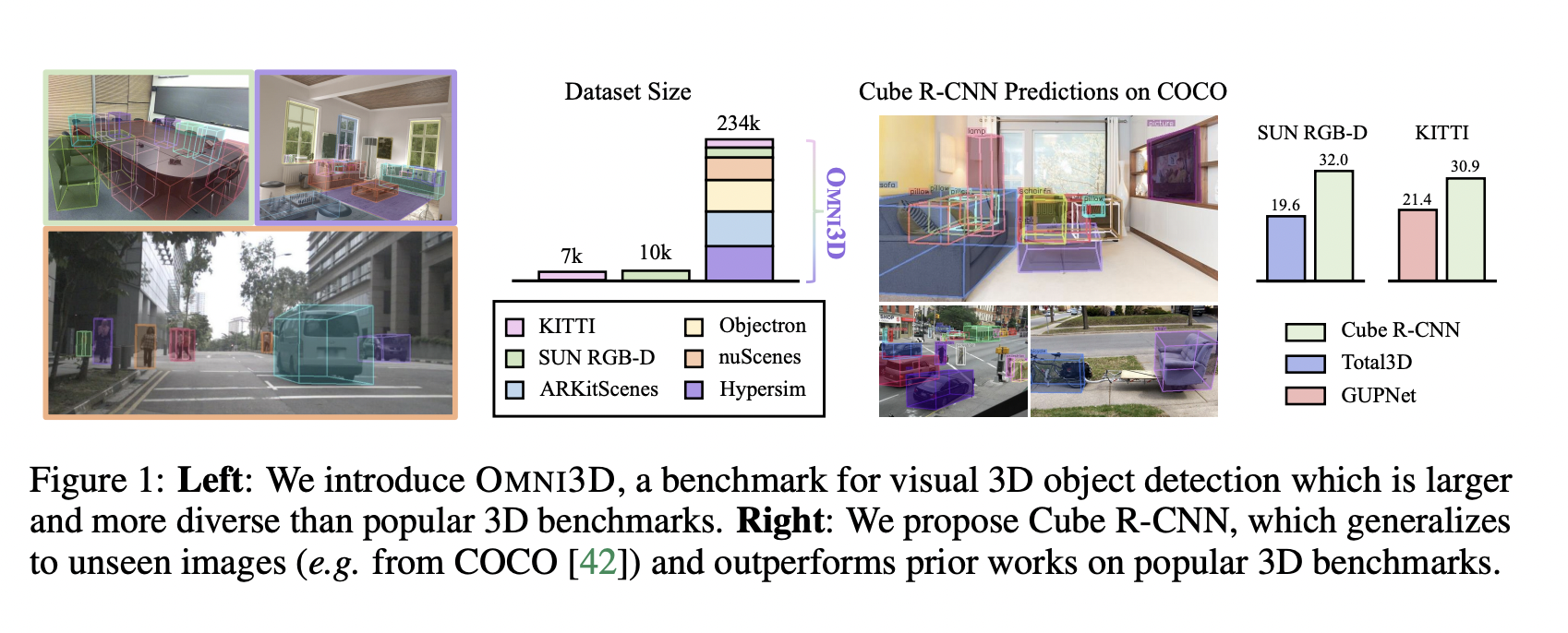
Computer vision has long struggled to comprehend objects and their characteristics from a single image, a topic that has applications in robotics, assistive technology, and AR/VR. The problem of 3D object recognition frames new challenges related to the perception of things in 3D from 2D visual inputs. Large-scale datasets have helped 2D object identification make significant strides in predicting and localizing items on the 2D picture grid in the recent decade. On the other hand, the world is three-dimensionally built out in three dimensions. Here, the objective is to create a tight-oriented 3D bounding box that estimates the 3D location and extent of each item in a picture.
Currently, two areas of 3D object identification are being researched: interior settings and urban domains with self-driving cars. Although the issue formulation is similar, there are few cross-domain insights into urban and internal scenarios solutions. Approaches are frequently designed so that they only function in the given domain. For instance, urban techniques represent yaw angles for 3D rotation and assume that objects are lying on a ground plane. A limited depth range is used for indoor procedures (e.g., up to 6m in ). Most of the time, these presumptions are incorrect for things and scenarios in the real world.
The most widely used benchmarks for 3D object identification using images are also somewhat tiny. Urban KITTI features 7k photos, and the indoor SUN RBG-D comprises 10,000; in comparison, 2D benchmarks like COCO are 20 times more extensive. They introduce a sizable and varied 3D benchmark dubbed OMNI3D to address the lack of a general large-scale dataset for 3D object detection. OMNI3D is a collection of 234k images with 3 million objects annotated with 3D boxes across 97 categories, including a chair, sofa, laptop, table, cup, shoes, pillow, books, car, person, etc. It is curated from publicly available datasets, including SUN RBG-D, ARKitScenes, Hypersim, Objectron, KITTI, and nuScenes.
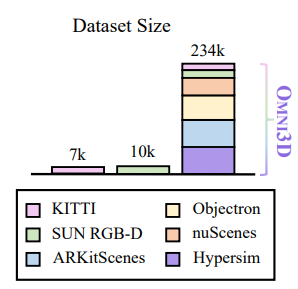
SUN RGB-D and KITTI, two standard benchmarks for 3D detection, are 20 bigger than OMNI3D. They offer a novel, quick, batched, and accurate intersection-over-union for 3D boxes technique for practical assessment of our sizable dataset that is 450 times quicker than existing approaches. They use evidence to demonstrate the value of OMNI3D as a massive dataset, showing that it can enhance single-dataset AP performance by up to 5.3 percent on benchmarks for urban areas and 3.8 percent for interior spaces. On this new dataset, they developed a universal and straightforward 3D object detector dubbed Cube R-CNN, which produces cutting-edge outcomes across domains and is motivated by significant research advancements in 2D and 3D recognition in recent years.
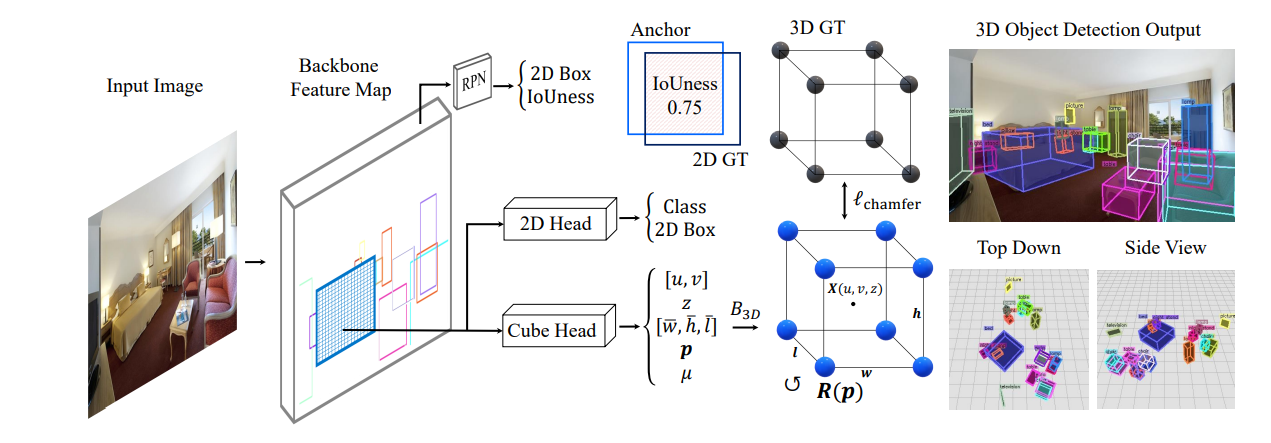
Cube R-CNN can detect every item in an image and all its 3D attributes, including rotation, depth, and domain. Due to the complexity of OMNI3D, our model exhibits great generalization and performs better than other studies for indoor and urban environments using a single integrated model. Learning from such a wide range of data presents difficulties since OMNI3D contains pictures with wildly fluctuating focus lengths that exacerbate scale-depth ambiguity. They address this by transforming object depth using the same virtual camera intrinsics across the dataset through virtual depth.
The use of data augmentations (such as picture rescaling) during training is a crucial component for 2D detection and, as they demonstrate, also for 3D, is made possible by virtual depth as an extra advantage. Compared to previous state-of-the-art methodologies, our solution with a single unified design beats Total3D by 12.4 percent IoU3D on indoor SUN RGB-D and GUPNet by 9.5 percent AP3D on urban KITTI. The code for OMNI3D is available on GitHub.
This Article is written as a summary article by Marktechpost Staff based on the research paper 'OMNI3D: A Large Benchmark and Model for 3D Object Detection in the Wild'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper, github link and project. Please Don't Forget To Join Our ML Subreddit
![]()
Content Writing Consultant Intern at Marktechpost.
Credit: Source link
Comments are closed.