Researchers at Microsoft Propose a Low-Precision Training Algorithm for GBDT, Based on Gradient Quantization
Gradient boosting decision trees is a sophisticated machine learning technique frequently utilized in real-world applications such as electronic advertising, search ranking, time-series prediction, and so on. One disadvantage of GBDT is that its training needs arithmetic operations on high-precision floating point integers and the handling of big datasets, which restricts scalability in distributed environments.
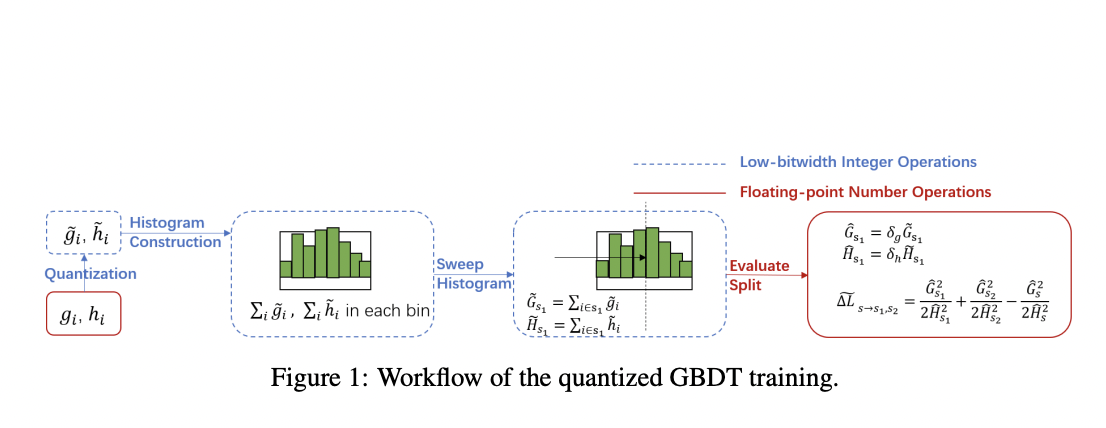
In a research paper Quantized Training of Gradient Boosting Decision Trees, A research team from Microsoft Research, DP Technology, and Tsinghua University demonstrate that GBDTs can benefit from low-precision training, suggesting a quantized methodology with low-bitwidth integer arithmetic for efficient low-precision GBDT training.
The researchers suggested using a quantized training technique across gradients to reduce the high-precision requirements of GBDTs. They quantize gradients into incredibly low-precision integers, allowing floating point arithmetic operations to be substituted with integer arithmetic operations, decreasing the total computing overhead.
The researchers also introduced two critical approaches for retaining the precision of quantized training, the two approaches being stochastic gradient discretization and leaf value refitting. They not only introduced but also demonstrated their effectiveness both practically and theoretically, verifying that the proposed method allows GBDTs to use low-precision computational resources to accomplish training speedups without affecting the performance.
The researchers used both CPUs and GPUs to build their suggested system in their empirical assessments. When compared to state-of-the-art GBDT techniques on both CPUs and GPUs, the researchers obtained up to 2x speedups using quantized training. The study’s findings showed that the technique could accelerate GBDT training in settings such as the single process on CPUs, single operation on a GPU, and distributed training across CPUs, demonstrating its adaptability to diverse computing resources.
The team claims this will be the first low-precision training method described for GBDT, and their work indicates that two or three-bit gradients are adequate for training with equivalent accuracy. They anticipate that these results will lead to a greater understanding of and improvements to the conventional GBDT algorithm.
This Article is written as a summary article by Marktechpost Staff based on the research paper 'Quantized Training of Gradient Boosting Decision Trees'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Nischal Soni is a consulting intern at MarktechPost. He is currently pursuing his B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. He is a Data Science and Supply Chain enthusiast and has a keen interest in the growing adaptation of technology across various sectors. He loves interacting with new people and is always up to learn new things when it comes to technology.
Credit: Source link
Comments are closed.