Google AI Introduces ‘LocoProp,’ A New Machine Learning Framework That Reconceives A Neural Network As A Modular Composition of Layers

In a recent article from Google AI, the researchers present a fresh approach for training DNN models in the paper “LocoProp: Enhancing BackProp through Local Loss Optimization.” They envision neural networks as a modular construction of layers in their new framework, LocoProp.
For training neural networks, backpropagation, often known as BackProp, has been the method of choice. To calculate the derivative of a function, the BackProp is only an enlargement of the chain rule. Output loss function in relation to each weight layer.
While a deep neural network’s (DNN) effectiveness depends largely on the model architecture and training data, the specific optimization technique utilized to update the model parameters is less frequently explored (weights). In order to train DNNs, a loss function that gauges the difference between the model’s predictions and the ground truth labels is minimized. Backpropagation is used for training, which modifies the model weights through gradient descent stages. Gradient descent then uses the gradient (i.e., derivative) of the loss with respect to the weights to update the weights.
The most fundamental update rule, stochastic gradient descent, involves moving in the direction of the negative backpropagated gradients. AdaGrad, RMSprop, and Adam are examples of more sophisticated first-order algorithms that precondition the gradient by a diagonal matrix and incorporate momentum.
Free-2 Min AI NewsletterJoin 500,000+ AI Folks
The simplest weight update is stochastic gradient descent, which shifts the weights in relation to the gradients in the opposite direction at each step (with appropriate step size, a.k.a. the learning rate). By incorporating data from earlier stages and/or local features of the loss function near the current weights, such as curvature information, more sophisticated optimization techniques change the direction of the negative gradient before updating the weights. For instance, the AdaGrad optimizer scales each coordinate depending on previous gradients, while the momentum optimizer encourages moving in the average direction of previous updates. Since these optimizers often change the update direction using just data from the first-order derivative, they are known as first-order techniques (i.e., gradient). More crucially, each of the weight parameter’s components is handled separately.
Advanced optimization techniques, such as Shampoo and K-FAC, have been found to increase convergence, reduce the number of iterations, and enhance the quality of the solution because they capture the correlations between gradients of parameters. These techniques record data on local variations in the derivatives of the loss or variations in gradients. Higher-order optimizers can find far more effective update routes for training models by taking into consideration the correlations between various parameter groups using this additional information. The disadvantage is that higher-order update directions need more computer resources to calculate than first-order updates. Higher-order optimizers can’t be used in reality since the procedure includes matrix inversion and consumes more memory for statistics storage.
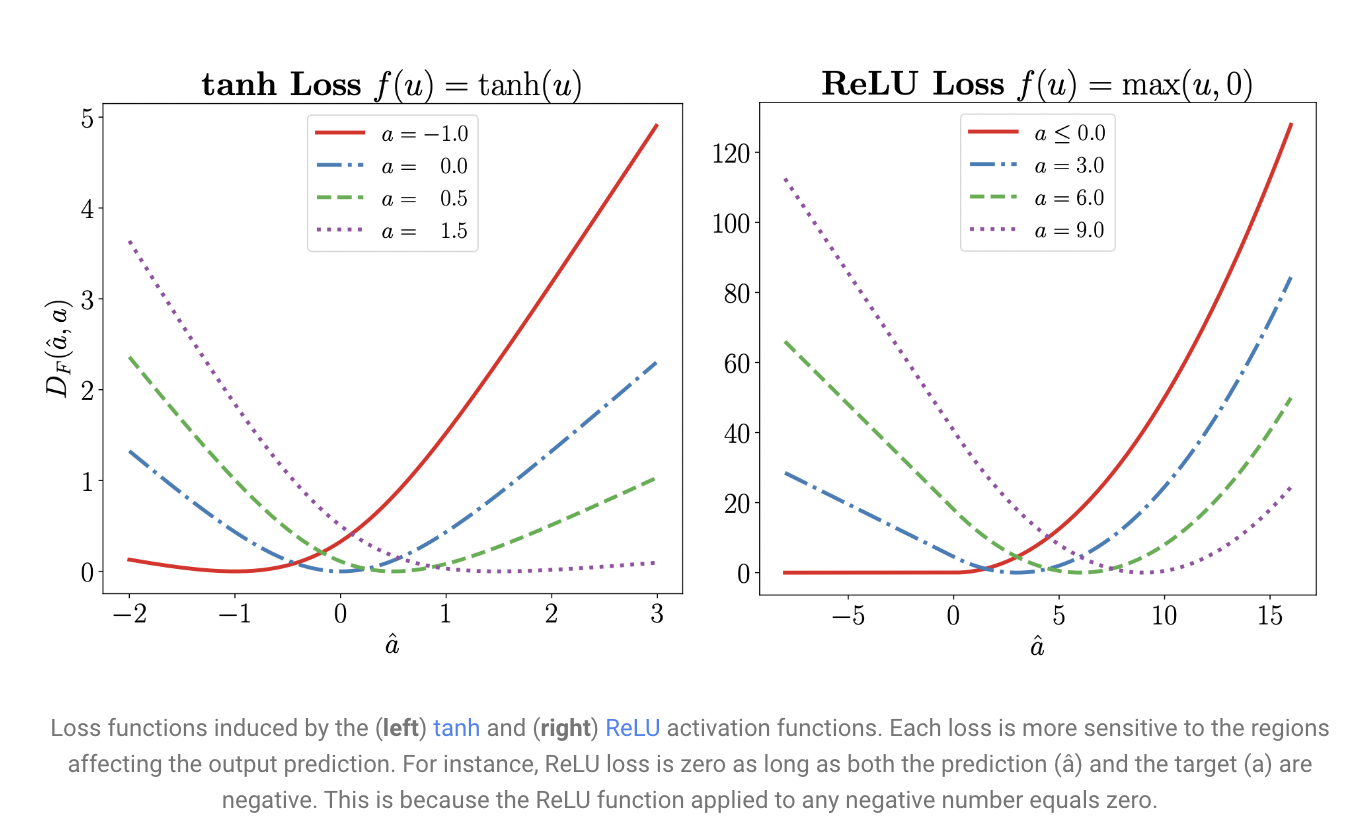
In a neural network, each layer typically transforms its inputs linearly before applying a non-linear activation function. Each layer in the new design has its own loss function, output objective, and weight regularizer. Each layer’s loss function is created to coincide with its activation function. With this approach, training repeatedly and concurrently across layers minimizes the local losses for a given mini-batch of instances. Their approach uses a first-order optimizer (like RMSProp) to conduct several local updates for each batch of instances, avoiding computationally costly processes like the matrix inversions necessary for higher-order optimizers. Researchers demonstrate, however, that the combined local updates resemble a higher-order update. On a deep autoencoder benchmark, they demonstrate empirically that LocoProp beats first-order techniques and compares favorably to higher-order optimizers like Shampoo and K-FAC without the burdensome memory and processing demands.
In general, neural networks are thought of as composite functions that, layer by layer, convert model inputs into output representations. This viewpoint is used by LocoProp as it divides the network into levels. In particular, LocoProp uses pre-defined local loss functions unique to each layer rather than modifying the layer’s weights to minimize the loss function at the output. The loss function for a certain layer is chosen to match the activation function; for example, a tanh loss would be chosen for a layer with a tanh activation. Each layerwise loss calculates the difference between the layer’s output (for a particular mini-batch of instances) and an idea of the layer’s desired output. A regularizer term also makes sure that the updated weights don’t deviate too much from the present values. The new goal function for each layer is the combined layerwise loss function (with a local target) plus regularizer.
LocoProp uses a forward pass to compute the activations, just like backpropagation does. LocoProp establishes per-neuron “targets” for each layer during the backward pass. Finally, LocoProp divides model training into separate issues across layers such that multiple local updates may be made to the weights of each layer concurrently.
Conclusion and Proposed Directions
For more effective deep neural network optimization, they presented LocoProp, a new framework. In order to minimize the local objectives, LocoProp divides neural networks into different layers, each of which has its own regularizer, output target, and loss function. The combined updates strongly approximate higher-order update directions, both conceptually and experimentally, while employing first-order updates for the local optimization issues.
Selecting the layerwise regularizers, targets, and loss functions is flexible with LocoProp. As a result, it permits the creation of fresh update rules based on these decisions.
This Article is written as a summary article by Marktechpost Staff based on the research paper 'LocoProp: Enhancing BackProp via Local Loss Optimization'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper, github link and reference article. Please Don't Forget To Join Our ML Subreddit
![]()
I am consulting intern at MarktechPost. I am majoring in Mechanical Engineering at IIT Kanpur. My interest lies in the field of machining and Robotics. Besides, I have a keen interest in AI, ML, DL, and related areas. I am a tech enthusiast and passionate about new technologies and their real-life uses.
Credit: Source link
Comments are closed.