Researchers From China Propose ‘LViT’, A Language-Vision Model To Leverage Text Medical Reports For Improved Segmentation
Among the many applications of Deep Learning in healthcare, segmentation is undoubtedly one of the most studied, given the broad range of possible advantages that it could bring.
Nevertheless, segmentation is not a costless task: first of all, as in the majority of applications in the healthcare fields, obtaining high-quality images is not trivial; second, the tagging phase is insanely costly in terms of time and resources, especially compared to the labeling that has to be done when the task is classification or even object detection.
Training a segmentation model that also relies on other information would be a turning point for medical segmentation.
This is precisely the idea of a research group from Xiamen, Texas, and Hull Universities, together with the Alibaba Group, that proposes LViT, a segmentation architecture to leverage written medical notes, which are usually generated along with the patient and thus come with no extra cost.
Medical text data and image data are naturally complementary, so text information can 1) compensate for the lack of medical image data and improve segmentation performance and 2) allow the use of unlabeled images.
LViT

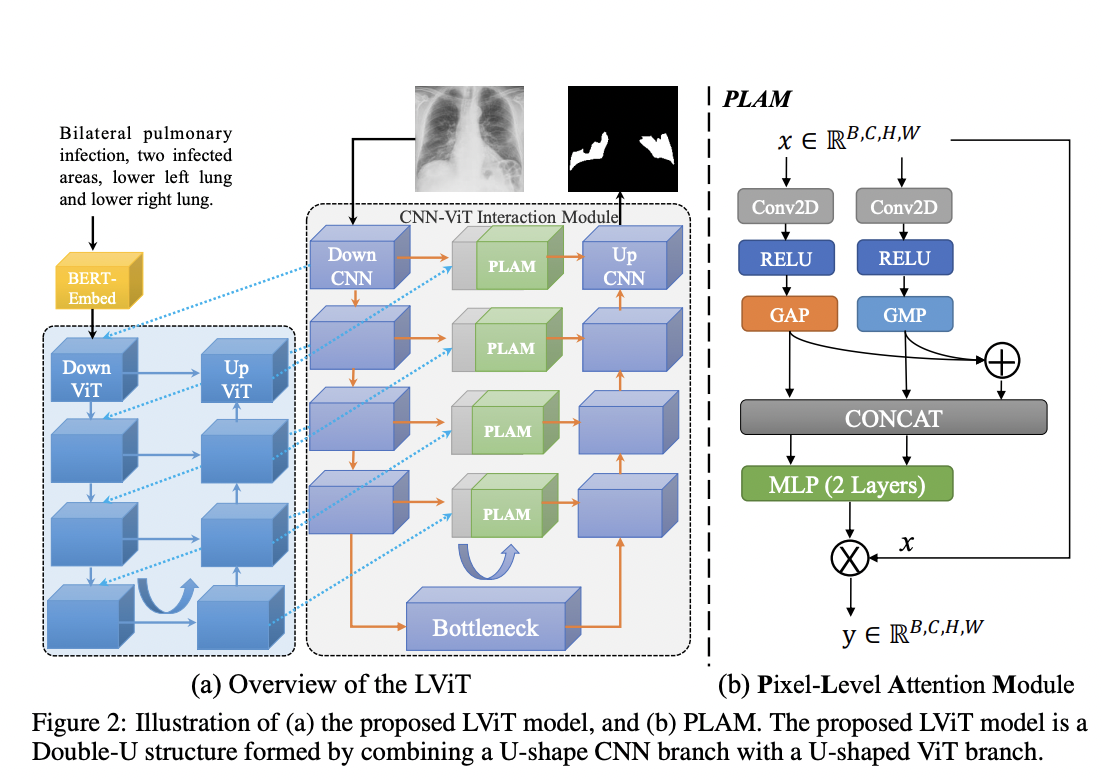
The LViT model is composed of two U-shaped branches: a CNN and a Transformer. The first reads the image and predicts the segmentation, while the second merges text and embedding to add cross-modality information and help the CNN segment the image.
More precisely, the CNN branch is composed of a downsampling and upsampling part. The subsequent outputs of each downsampling layer are passed directly to the ViT branch to merge text and image encoding. PLAM (Pixel-Level Attention Module) blocks are used as skip connections that take as input the intermediate representation of the downsampling branch and the reconstructed features in the upsampling part of ViT. The configuration of PLAM is shown in the figure above on the right: the outputs of two parallel branches with Global Average Pooling and Global Max Pooling are added, concatenated, and passed to an MLP. This technique is designed to preserve the local features of the image and further merge the semantic features in the text.
On the other hand, the ViT branch receives a text embedding from BERT-Embed of the medical annotation. together with the image embedding.
Last but not least, the authors also introduced a very efficient technique for handling pseudo labels (labels assigned to unlabeled data) based on Exponential Moving Average called Exponential Pseudo-label Iteration (EPI). Very briefly, at each step, the pseudo predicted segmentation is gradually updated using the previously predicted segmentation map as ground truth.
The network is trained with dice loss and cross-entropy for labeled data, summed with LV (Language Vision) Loss for unlabeled data. In practice, a similarity metric is computed to find the most similar text to the one we are computing. Once found, the corresponding segmentation map is taken, and a loss of the similarity between it and the ground truth mask is calculated.
Results
After an extensive ablation study on the different components, the model size, and the hyperparameters, the method has been applied to two different datasets, MoNuSeg and QaTa-COV19, and compared with many state-of-the-art models, obtaining outstanding results in terms of dice and mIoU (mean Intersection over Unit). Some graphic results are shown below:

This Article is written as a research summary article by Marktechpost Research Staff based on the research paper 'LViT: Language meets Vision Transformer in Medical Image Segmentation'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper and github link Please Don't Forget To Join Our ML Subreddit
![]()
Leonardo Tanzi is currently a Ph.D. Student at the Polytechnic University of Turin, Italy. His current research focuses on human-machine methodologies for smart support during complex interventions in the medical domain, using Deep Learning and Augmented Reality for 3D assistance.
Credit: Source link
Comments are closed.