Apple AI Researchers Propose GAUDI: a Generative Model That Captures Distributions of Complex and Realistic 3D Scenes
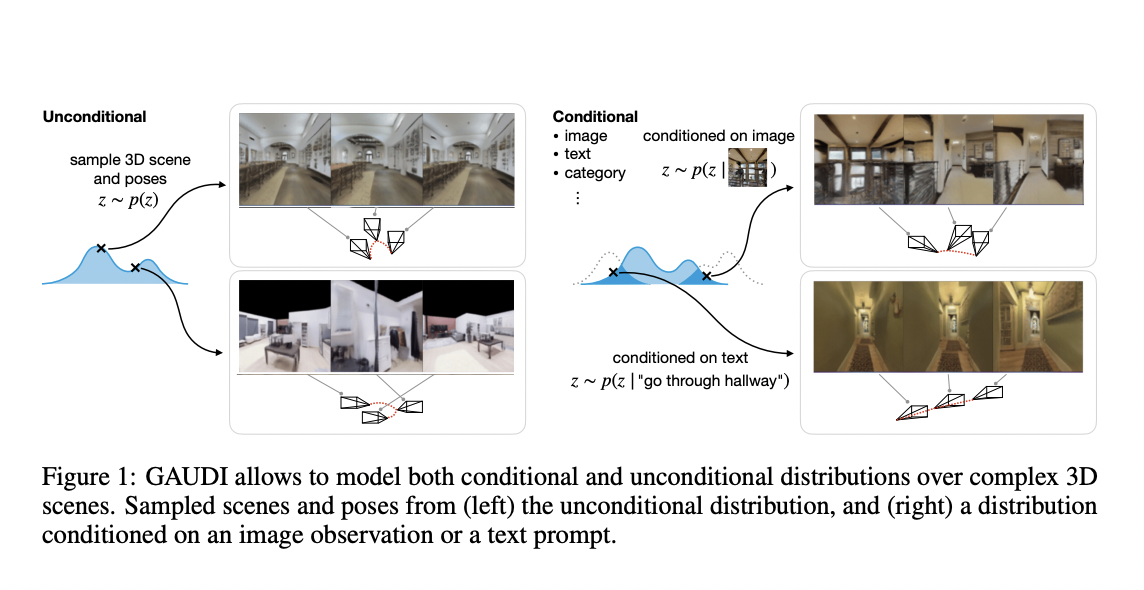
Progress in 3D generative models is desperately needed if learning systems are to comprehend and build 3D spaces. The researchers honor Antoni Gaud, whose remark, “The invention continues continuously via the medium of people,” with the name of their approach, as you can see from the article title. In order to display views from scenes sampled from the learned distribution, they are interested in generative models that can record the distribution of 3D scenes. Such generative model extensions to conditional inference issues might significantly improve a variety of machine learning and computer vision tasks. For instance, a written description or a sample of possible scenario completions may be helpful.
A Generative Adversarial Network (GAN), a parametric function that inputs the coordinates of a point in 3D space and camera posture, and returns a density scalar and RGB value for that 3D point, has been used recently in generative modeling for 3D objects or scenes. By putting the 3D points queried through the volume rendering equation and projecting them onto any 2D camera view, images may be created from the radiance field that the model created. Additionally, these models would be beneficial in SLAM, model-based reinforcement learning, or the development of 3D content.
Despite being effective on small or simple 3D datasets (such as single objects or a limited number of indoor scenes), these datasets have a canonical coordinate system. GANs are challenging to train on data for which a canonical coordinate system does not exist, as is the case for 3D scenes, and they suffer from training pathologies such as mode collapse. Furthermore, when modeling distributions of 3D objects, it is frequently believed that camera postures are sampled from a distribution shared across objects (i.e., generally over SO(3)). However, this is not the case when modeling distributions of sceneries.
This is due to the independent dependence of each scene on the distribution of viable camera postures (based on the structure and location of walls and other objects). Additionally, this distribution might include all postures from the SE(3) group for scenarios. This fact becomes more apparent when they consider camera postures as a route across the scene. Each trajectory in GAUDI, a collection of posed photos from a 3D scene, is converted into a latent representation that decouples the camera path from the radiance field, such as a 3D scene. They identify these latent representations by seeing them as free parameters and presenting an optimization problem in which the reconstruction goal optimizes the latent representation for each trajectory.
This straightforward training method can handle thousands of trajectory combinations. It is also straightforward to manage a large and variable number of views for each trajectory when the latent representation of each trajectory is interpreted as a free parameter instead of needing a complex encoder architecture to pool over a large number of views. They develop a generative model using the set of latent representations after optimizing them for an observed empirical distribution of trajectories. The model may create scenes by interpolating within the latent space in the unconditional case since it can sample radiance fields fully from the previous distribution it has learned. The conditional case allows the generation of radiance fields compatible with conditional variables made accessible to the model at training time (such as pictures and text prompts).
These contributions may be summed up as follows:
- They scale 3D scene production to thousands of interior scenes with hundreds of thousands of photos without experiencing mode collapse or canonical orientation problems during training.
- To identify latent representations that disentangle simultaneously describe a radiance field and the camera positions, they develop a unique denoising optimization goal.
- Using a variety of datasets, the method achieves cutting-edge generation performance.
- This method supports unconditional and conditional generating setups, depending on either text or pictures.
The code implementation is available on the GitHub repository of Apple.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'GAUDI: A Neural Architect for Immersive 3D Scene Generation'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper and github link Please Don't Forget To Join Our ML Subreddit
![]()
Content Writing Consultant Intern at Marktechpost.
Credit: Source link
Comments are closed.