Google AI Researchers Propose N-Grammer for Augmenting the Transformer Architecture with Latent n-grams
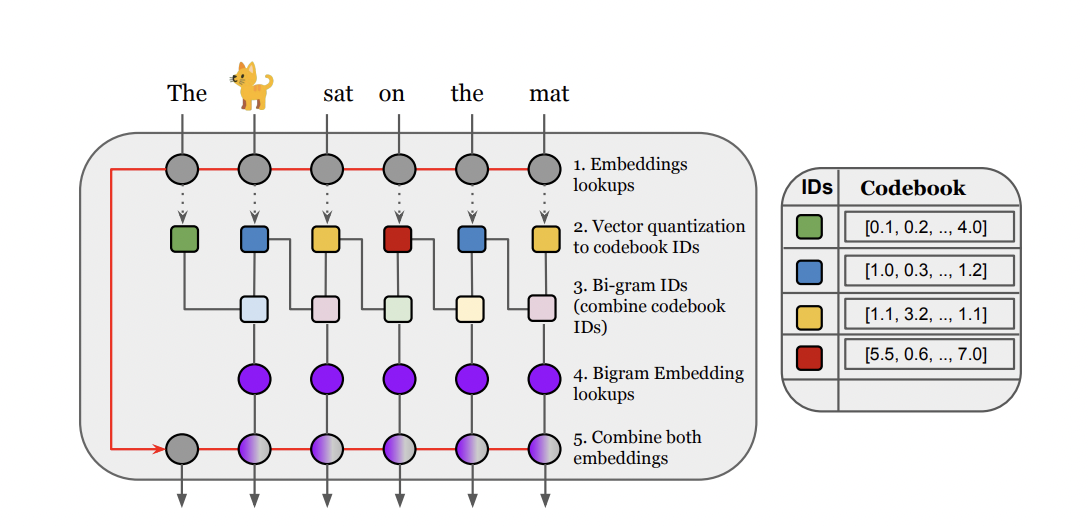
Introducing self-attention to neural networks has propelled rapid and outstanding progress in generative text modeling. Transformer models are now recognized as the fundamental approach to natural language processing. Hence, scaling these models has attracted several recent interests and investments. This paper suggests a simple alteration to the Transformer architecture, called the N-Grammer. During training and inference, the N-Grammer layer uses sparse operations only. This work discovers that while being substantially faster at inference, a Transformer framework integrated with the latent N-Grammer layer can also attain the worth of a larger Transformer. Although the N-Grammer layer is flexible enough to consider any N-gram, this work utilizes bi-grams. The architecture of the N-Grammer layer is represented in Figure 1.
The layer that is added in this research has four core functions. 1) To determine a sequence of discrete latent representation using Product Quantization (PQ) provided a succession of text uni-gram embeddings. 2) Determine the latent sequence’s bigram representation. 3) Hash into the bi-gram vocabulary to find trainable bi-gram embeddings. 4) Integrate the input uni-gram embeddings with the bi-gram embeddings.
The first step in the N-Grammer layer is to achieve a parallel series of discrete latent representations with PQ. Smaller bi-gram embedding tables and effective learning representation are two main benefits of adopting latent representation. The uni-gram latent IDs from the preceding position are combined to create the latent bi-gram IDs at each place. Instead of considering all bi-grams, the latent bi-gram IDs are mapped to a reduced bi-gram vocabulary by utilizing distinct hash functions for each head. Layer normalization (LN) is first applied to the bi-gram embedding and the uni-gram embedding separately, after which the two are concatenated along the embedding dimension and supplied as input to the remainder of the Transformer network.
On the C4 data set, the proposed N-Grammer model is compared against the Transformer framework and the recent Primer framework. A Gated Linear Unit is employed as the feed-forward network along with a GELU activation function and rotary position embedding (RoPE) to create a solid baseline in this research. On a TPU-v3, each model is trained using a 256 batch size and a 1024 sequence length.
The ablation study is carried out on N-Grammer with sizes ranging from 128 to 512 for the bi-gram embedding dimension. As N-Grammer relies on sparse look-up operations, its training and inference costs do not scale with the number of parameters in the n-gram embedding layer. This research utilizes an Adam optimizer with a 10-3 learning rate for optimization. All models are trained on 32 cores TPU-v3 and 1024 sequence length using a global batch size of 256. The n-gram embedding tables are trained with a learning rate of 0.1 using the Adagrad optimizer, which is known to be efficient at learning sparse features.
The latent N-Grammer layer can be introduced to any intermediary layer of the network; hence, ablation tests are also performed on its position. It was found that positioning the n-gram layer at the beginning of the network is the best option. Additionally, performance declines with time due to moving the layer to the end of the network. In convergence comparison, it has been found that the proposed N-Grammer model achieves the same perplexity or accuracy in wall clock time about two times more quickly than the Primer model. While evaluation downstream classification gains, It is emphasized that for most Super-GLUE jobs, the N-Grammer performs better than the Transformer and Primer models.
Hence, this research introduces the N-Grammer layer to add latent ngrams to the Transformer design. It has been found that this layer is significantly faster at inference and can equal the quality of a larger Transformer and Primer. The suggested method is appropriate for systems that support large embedding tables. The N-Grammer is appealing for deployment since sparse operations like an embedded look-up are difficult to carry out on most hardware platforms.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'N-Grammer: Augmenting Transformers with latent n-grams'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Priyanka Israni is currently pursuing PhD at Gujarat Technological University, Ahmedabad, India. Her interest area lies in medical image processing, machine learning, deep learning, data analysis and computer vision. She has 8 years of teaching experience to engineering graduates and postgraduates.
Credit: Source link
Comments are closed.