Researchers From Princeton And Max Planck Developed A Reinforcement Learning–Based Simulation That Shows The Human Desire Always To Want More May Have Evolved As A Way To Speed Up Learning
Through the means of a computational framework of reinforcement learning, researchers from Princeton University have tried to find the relationship between happiness with habituation and comparisons that humans operate on. habituation and comparison are two factors that are found to affect human happiness the most, but the most crucial question is why these features decide when we feel happy and when we do not. The framework is built to answer this question precisely and in a scientific manner. In standard RL theory, the reward functions serve the role of defining optimal behavior. Through machine learning, it’s also come to light that the reward function steers the agent from incompetence to mastery. It is found that the reward functions that are based on external factors facilitate faster learning. It is found that the agents perform sub-optimally where aspirations are left unchecked, and they become too high.
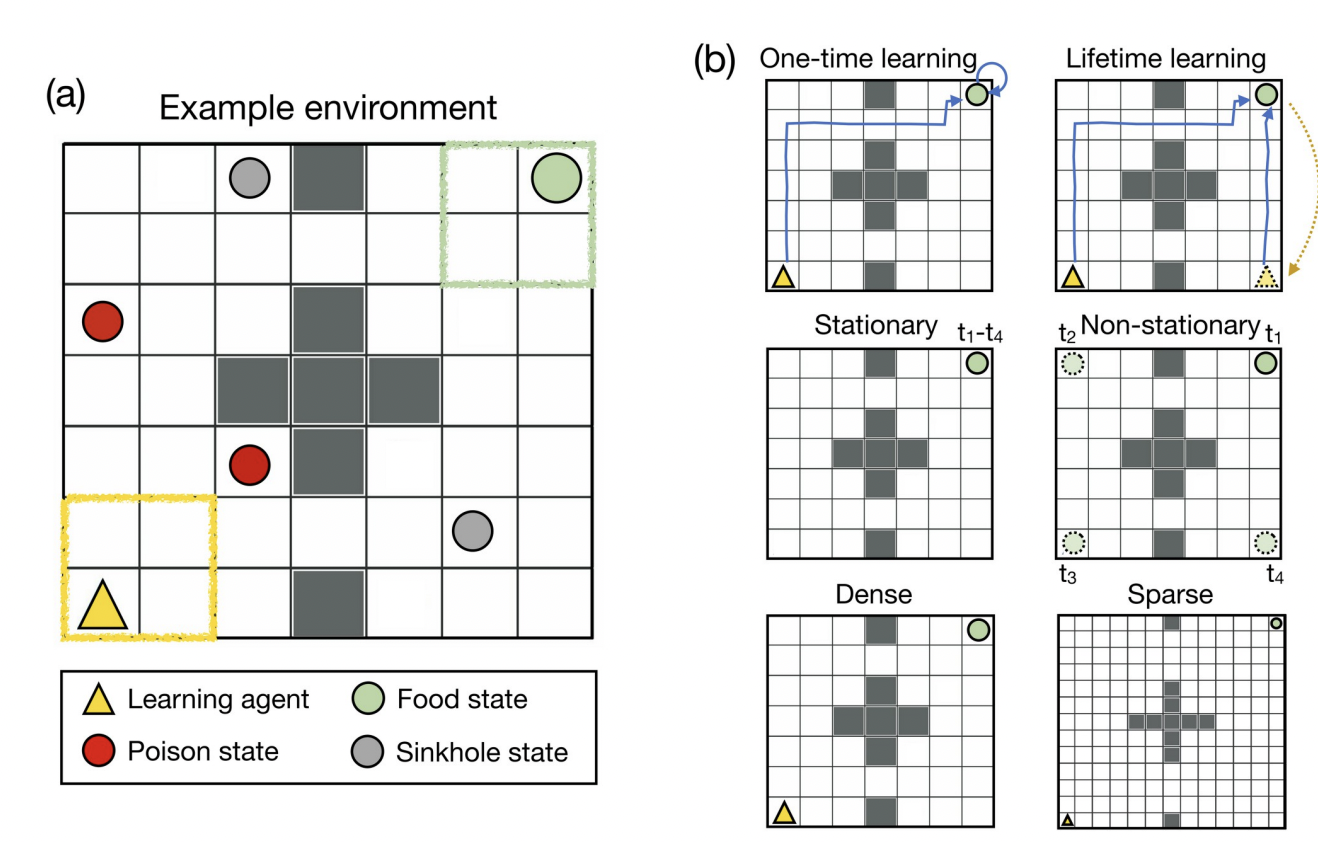
RL describes how an agent interacting with its environment can learn to choose its actions to maximize the reward from an activity; The environment has different states, which can lead to multiple distinguishable actions from the agent. We divide the reward function into two categories Objective and Subjective reward functions. The objective reward function outlines the task, i.e., what the agent designer wants the RL agent to achieve, making the job significantly harder to solve. Because of this, some parameters of the reward functions are changed. The parametric modified objective reward system is called subjective reward functions, which, when used by an agent to learn, can maximize the expected objective reward. The reward functions depend very sensitively on the environment. The environment chosen is a simulated space inside a more extensive environment known as a grid world which is a popular testing space for RL.
When we explore the results of the experiment, we find the following results –
- The comparison provides an explorative space that helps in improving learning significantly. This is because the ‘compare only’ agents learn and explore, which lets them assign a negative value to a negative result state and helps them reduce the time they have to spend while going through all the scenarios in a new test case.
- Prior expectation and comparison help deal with non-stationarity. In a non-stationary environment, both previous expectations and relative comparisons are valuable components that help the agent move quickly from the states that used to be previously rewarding but are not anymore.
- Reward sparsity requires controlling comparisons – In the ‘compare only’ state, if it is left unchecked, the agent can become too passive and might learn sub-optimal policy in the environment of sparse reward functions.
While this model provides us great insights into the human mind, it also tells us that habituation and relative comparison are great in promoting adaptation to a new environment and
It also tells us that these steps are deeply engraved in the human mind, and if we have any hope of reducing overconsumption, we have to think about tackling these biases of the human mind seriously. For better or worse, we are trapped in an unending cycle of needs and desires. It is essential and urgent that we create policies and perform steps to limit the habituation and comparison of the human mind.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'The pursuit of happiness: A reinforcement learning perspective on habituation and comparisons'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and reference article. Please Don't Forget To Join Our ML Subreddit
![]()
A Machine Learning enthusiast who loves to research and get to know new and latest technologies like AlphaFold, DeepMind AlphaZero etc. that are the best AI in their respective fields and I am very excited what the future of AI and how we will implement it in our daily life
Credit: Source link
Comments are closed.